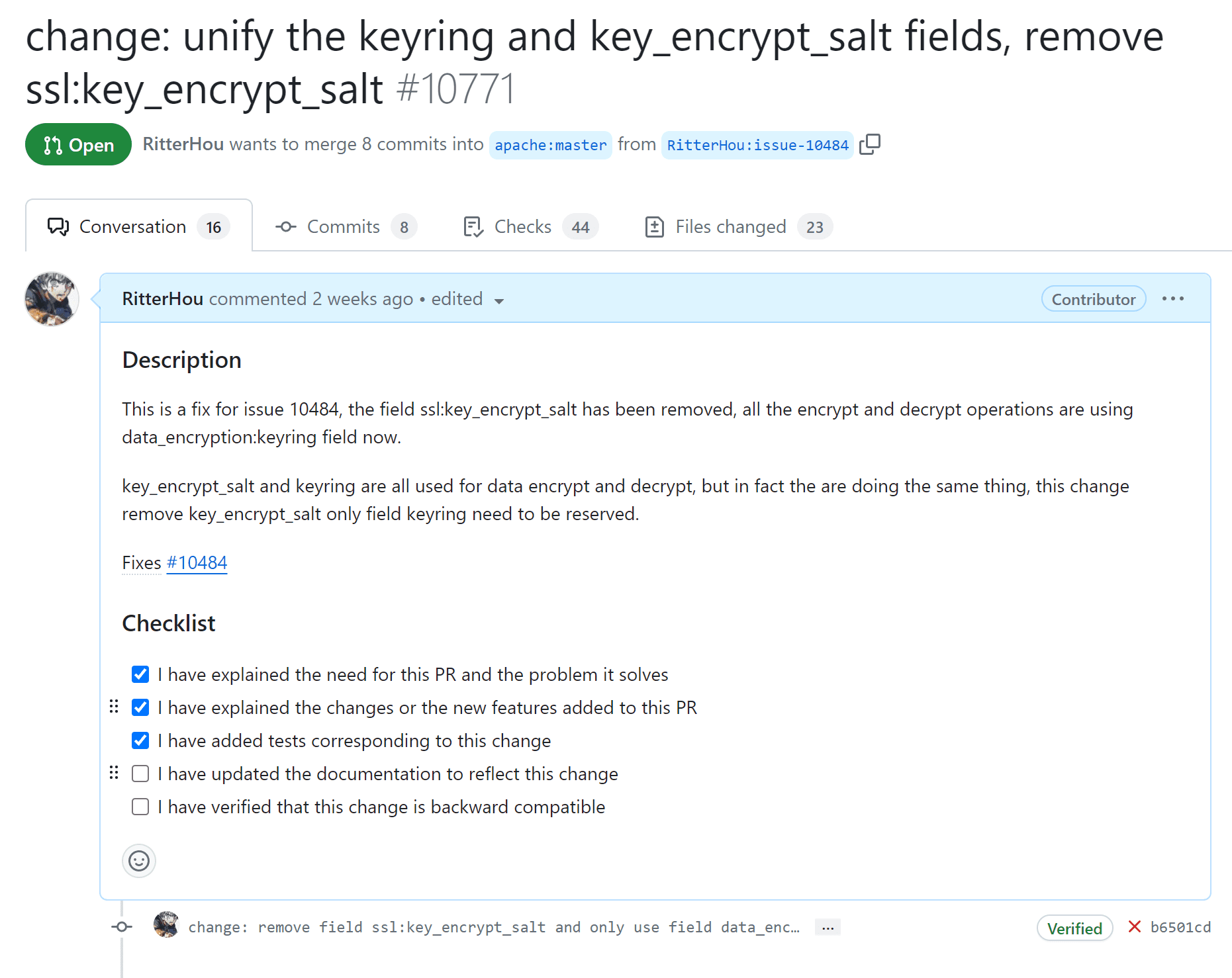
最近对Elasticsearch(以下简称ES)进行了升级,升级之后把部分数据从之前的ES-1.5集群同步到了现在的ES-7.5集群,之后在新集群中进行数据查询的时候发现会有偶发性的查询非常慢的情况。新集群的大部分查询耗时都在10ms以内,但是偶尔却会出现800ms左右的超高查询耗时,本文记录了该问题的排查过程。
GC的原因?
首先我们怀疑是ES的GC导致了偶发性的慢查询,我们知道JVM的GC会导致Stop The World现象,在GC时节点无法处理任何逻辑导致查询行为被阻塞最终导致超长的查询耗时,而GC这种行为本身也是会偶发的,所以和我们观察到的偶尔出现查询耗时非常高的现象非常吻合。
我们观察ES运行的GC日志,并未看到有延迟特别高的GC行为,而且也没有看到任何Old GC的动作,因此这些慢查询应该并不是因为JVM的GC行为导致的。
顺便介绍一下,我们使用的是ES-7.5.2自带的bundled JDK,它的版本为13.0.1
~ java -versionopenjdk version "13.0.1" 2019-10-15OpenJDK Runtime Environment AdoptOpenJDK (build 13.0.1+9)OpenJDK 64-Bit Server VM AdoptOpenJDK (build 13.0.1+9, mixed mode, sharing)
在该版本的Java中已经废弃了以前的GC日志打印配置方式,新版本的Java使用了一种新的叫做JVM Unified Logging Framework的方式来控制GC日志的打印,它通过 -Xlog 这个属性来进行设置。
我们在当前的ES配置jvm.options中添加GC相关配置如下
## JDK 8 GC logging8:-XX:+PrintGCDetails8:-XX:+PrintGCDateStamps8:-XX:+PrintTenuringDistribution8:-XX:+PrintGCApplicationStoppedTime8:-Xloggc:logs/gc.log8:-XX:+UseGCLogFileRotation8:-XX:NumberOfGCLogFiles=328:-XX:GCLogFileSize=64m# JDK 9+ GC logging9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
上面我们设置了两种GC日志配置,一种是针对Java8的配置,还有一种是针对大于或者等于Java9的配置,ES会根据JVM的版本选择合适的GC日志配置。
因为我们使用的是Java13,它的版本号是大于9的,因此ES会自动使用
-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
这个Xlog的配置来设置GC LOG的打印方式。Xlog属性使用冒号 ( : ) 把它的内容分割为了四个部分:
- JVM中哪些tag的日志需要被打印,多个tag之间用逗号 (
, ) 分割 - 日志打印的目标位置,可以是标准输出或文件等等
- 打印日志时同时一起打印的附加属性,例如时间、进程号、tag名称等等,属性之间用逗号 (
, ) 分割 - 一些打印日志时会用到的其它属性
我们再了解一下上面ES使用的-Xlog属性的各个部分的具体含义,这些属性被分为了四大类
| 属性 | 含义 |
|---|
| (tags) |
| gc* | 打印JVM中tag以gc开头的日志,级别为默认值info |
| gc+age=trace | 打印JVM中tag为gc+age的日志,级别为trace |
| safepoint | 打印JVM的safepoint日志,级别为默认值info |
| (日志打印位置) |
| file=logs/gc.log | GC日志所保存的文件名 |
| (需要被打印的其它一些属性) |
| utctime | 打印GC的时间点 |
| pid | JVM的进程号 |
| tags | 打印对应的tags信息 |
| (控制日志打印的一些其它属性) |
| filecount=32,filesize=64m | 当日志文件达到64m是进行切割,保存32个切割文件 |
上面的Xlog可以得到日志如下,包含了gc*、gc+age和safepoint等tag的一些日志
[2020-08-01T09:54:10.551+0000][1836][gc,heap] Heap region size: 4M[2020-08-01T09:54:14.339+0000][1836][gc ] Using G1[2020-08-01T09:54:14.339+0000][1836][gc,heap,coops] Heap address: 0x0000000600000000, size: 8192 MB, Compressed Oops mode: Zero based, Oop shift amount: 3[2020-08-01T09:54:14.339+0000][1836][gc,cds ] Mark closed archive regions in map: [0x00000007ffc00000, 0x00000007ffc77ff8][2020-08-01T09:54:14.339+0000][1836][gc,cds ] Mark open archive regions in map: [0x00000007ffb00000, 0x00000007ffb47ff8][2020-08-01T09:54:14.355+0000][1836][gc ] Periodic GC disabled[2020-08-01T09:54:14.376+0000][1836][safepoint ] Safepoint "EnableBiasedLocking", Time since last: 26126542 ns, Reaching safepoint: 711439 ns, At safepoint: 88387 ns, Total: 799826 ns[2020-08-01T09:54:14.381+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 4864660 ns, Reaching safepoint: 286521 ns, At safepoint: 99576 ns, Total: 386097 ns...省略部分日志...[2020-08-01T09:54:17.374+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 743562 ns, Reaching safepoint: 193154 ns, At safepoint: 51118 ns, Total: 244272 ns[2020-08-01T09:54:17.374+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 198778 ns, Reaching safepoint: 375962 ns, At safepoint: 58373 ns, Total: 434335 ns[2020-08-01T09:54:17.410+0000][1836][gc,start ] GC(0) Pause Young (Normal) (G1 Evacuation Pause)[2020-08-01T09:54:17.412+0000][1836][gc,task ] GC(0) Using 13 workers of 13 for evacuation[2020-08-01T09:54:17.413+0000][1836][gc,age ] GC(0) Desired survivor size 27262976 bytes, new threshold 15 (max threshold 15)[2020-08-01T09:54:17.452+0000][1836][gc,age ] GC(0) Age table with threshold 15 (max threshold 15)[2020-08-01T09:54:17.452+0000][1836][gc,age ] GC(0) - age 1: 13104680 bytes, 13104680 total[2020-08-01T09:54:17.452+0000][1836][gc,phases ] GC(0) Pre Evacuate Collection Set: 1.8ms[2020-08-01T09:54:17.452+0000][1836][gc,phases ] GC(0) Evacuate Collection Set: 25.5ms[2020-08-01T09:54:17.452+0000][1836][gc,phases ] GC(0) Post Evacuate Collection Set: 2.3ms[2020-08-01T09:54:17.452+0000][1836][gc,phases ] GC(0) Other: 12.1ms[2020-08-01T09:54:17.452+0000][1836][gc,heap ] GC(0) Eden regions: 102->0(98)[2020-08-01T09:54:17.452+0000][1836][gc,heap ] GC(0) Survivor regions: 0->4(13)[2020-08-01T09:54:17.452+0000][1836][gc,heap ] GC(0) Old regions: 0->0[2020-08-01T09:54:17.452+0000][1836][gc,heap ] GC(0) Archive regions: 2->2[2020-08-01T09:54:17.452+0000][1836][gc,heap ] GC(0) Humongous regions: 0->0[2020-08-01T09:54:17.452+0000][1836][gc,metaspace ] GC(0) Metaspace: 20335K->20335K(1067008K)[2020-08-01T09:54:17.452+0000][1836][gc ] GC(0) Pause Young (Normal) (G1 Evacuation Pause) 411M->16M(8192M) 41.802ms[2020-08-01T09:54:17.452+0000][1836][gc,cpu ] GC(0) User=0.17s Sys=0.14s Real=0.04s[2020-08-01T09:54:17.452+0000][1836][safepoint ] Safepoint "G1CollectForAllocation", Time since last: 35223271 ns, Reaching safepoint: 235074 ns, At safepoint: 42013632 ns, Total: 42248706 ns[2020-08-01T09:54:17.452+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 274881 ns, Reaching safepoint: 134481 ns, At safepoint: 40119 ns, Total: 174600 ns[2020-08-01T09:54:17.452+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 43491 ns, Reaching safepoint: 140798 ns, At safepoint: 26232 ns, Total: 167030 ns[2020-08-01T09:54:17.453+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 64481 ns, Reaching safepoint: 129088 ns, At safepoint: 25018 ns, Total: 154106 ns[2020-08-01T09:54:17.453+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 35003 ns, Reaching safepoint: 129551 ns, At safepoint: 28893 ns, Total: 158444 ns[2020-08-01T09:54:17.453+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 111722 ns, Reaching safepoint: 113937 ns, At safepoint: 37371 ns, Total: 151308 ns[2020-08-01T09:54:17.453+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 36233 ns, Reaching safepoint: 128605 ns, At safepoint: 30396 ns, Total: 159001 ns[2020-08-01T09:54:17.454+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 44610 ns, Reaching safepoint: 129399 ns, At safepoint: 28918 ns, Total: 158317 ns[2020-08-01T09:54:17.456+0000][1836][gc,start ] GC(1) Pause Young (Concurrent Start) (Metadata GC Threshold)[2020-08-01T09:54:17.456+0000][1836][gc,task ] GC(1) Using 13 workers of 13 for evacuation[2020-08-01T09:54:17.456+0000][1836][gc,age ] GC(1) Desired survivor size 27262976 bytes, new threshold 15 (max threshold 15)[2020-08-01T09:54:17.473+0000][1836][gc,age ] GC(1) Age table with threshold 15 (max threshold 15)[2020-08-01T09:54:17.473+0000][1836][gc,age ] GC(1) - age 1: 29256 bytes, 29256 total[2020-08-01T09:54:17.473+0000][1836][gc,age ] GC(1) - age 2: 13077648 bytes, 13106904 total[2020-08-01T09:54:17.473+0000][1836][gc,phases ] GC(1) Pre Evacuate Collection Set: 0.4ms[2020-08-01T09:54:17.473+0000][1836][gc,phases ] GC(1) Evacuate Collection Set: 15.3ms[2020-08-01T09:54:17.473+0000][1836][gc,phases ] GC(1) Post Evacuate Collection Set: 0.9ms[2020-08-01T09:54:17.473+0000][1836][gc,phases ] GC(1) Other: 0.6ms[2020-08-01T09:54:17.473+0000][1836][gc,heap ] GC(1) Eden regions: 1->0(98)[2020-08-01T09:54:17.473+0000][1836][gc,heap ] GC(1) Survivor regions: 4->4(13)[2020-08-01T09:54:17.473+0000][1836][gc,heap ] GC(1) Old regions: 0->0[2020-08-01T09:54:17.473+0000][1836][gc,heap ] GC(1) Archive regions: 2->2[2020-08-01T09:54:17.473+0000][1836][gc,heap ] GC(1) Humongous regions: 0->0[2020-08-01T09:54:17.473+0000][1836][gc,metaspace ] GC(1) Metaspace: 20366K->20366K(1069056K)[2020-08-01T09:54:17.473+0000][1836][gc ] GC(1) Pause Young (Concurrent Start) (Metadata GC Threshold) 20M->16M(8192M) 17.263ms[2020-08-01T09:54:17.473+0000][1836][gc,cpu ] GC(1) User=0.06s Sys=0.03s Real=0.02s[2020-08-01T09:54:17.473+0000][1836][gc ] GC(2) Concurrent Cycle[2020-08-01T09:54:17.473+0000][1836][gc,marking ] GC(2) Concurrent Clear Claimed Marks[2020-08-01T09:54:17.473+0000][1836][gc,marking ] GC(2) Concurrent Clear Claimed Marks 0.039ms[2020-08-01T09:54:17.473+0000][1836][gc,marking ] GC(2) Concurrent Scan Root Regions[2020-08-01T09:54:17.473+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 93450 ns, Reaching safepoint: 129146 ns, At safepoint: 17510480 ns, Total: 17639626 ns[2020-08-01T09:54:17.474+0000][1836][safepoint ] Safepoint "RevokeBias", Time since last: 59519 ns, Reaching safepoint: 157428 ns, At safepoint: 40661 ns, Total: 198089 ns
关于Xlog的更加详细的信息可以查看**参考文档**。有的时候我们只想看到GC的日志而不在意其它的日志信息,此时可以只设置gc日志的tag而移除其它日志的tag,同时我们停止打印tags信息并且将打印时间修改为ISO-8601格式。那么根据参考文档,具体设置如下
-Xlog:gc:file=logs/gc.log:t,pid:filecount=32,filesize=64m
改完之后得到的日志如下
[2020-08-07T14:41:42.809+0800][25593] Using G1[2020-08-07T14:41:42.827+0800][25593] Periodic GC disabled[2020-08-07T14:41:54.322+0800][25593] GC(0) Pause Young (Normal) (G1 Evacuation Pause) 411M->16M(8192M) 32.843ms[2020-08-07T14:41:54.339+0800][25593] GC(1) Pause Young (Concurrent Start) (Metadata GC Threshold) 20M->16M(8192M) 12.395ms[2020-08-07T14:41:54.339+0800][25593] GC(2) Concurrent Cycle[2020-08-07T14:41:54.357+0800][25593] GC(2) Pause Remark 24M->24M(8192M) 2.347ms[2020-08-07T14:41:54.359+0800][25593] GC(2) Pause Cleanup 24M->24M(8192M) 0.409ms[2020-08-07T14:41:54.393+0800][25593] GC(2) Concurrent Cycle 53.919ms[2020-08-07T14:41:54.889+0800][25593] GC(3) Pause Young (Normal) (G1 Evacuation Pause) 408M->19M(8192M) 16.746ms[2020-08-07T14:41:55.335+0800][25593] GC(4) Pause Young (Normal) (G1 Evacuation Pause) 411M->22M(8192M) 13.978ms[2020-08-07T14:41:56.946+0800][25593] GC(5) Pause Young (Normal) (G1 Evacuation Pause) 426M->42M(8192M) 38.684ms[2020-08-07T14:41:57.545+0800][25593] GC(6) Pause Young (Concurrent Start) (Metadata GC Threshold) 104M->50M(8192M) 106.594ms[2020-08-07T14:41:57.545+0800][25593] GC(7) Concurrent Cycle[2020-08-07T14:41:57.566+0800][25593] GC(7) Pause Remark 52M->52M(8192M) 3.391ms[2020-08-07T14:41:57.571+0800][25593] GC(7) Pause Cleanup 52M->52M(8192M) 0.689ms[2020-08-07T14:41:57.599+0800][25593] GC(7) Concurrent Cycle 54.224ms[2020-08-07T14:42:00.515+0800][25593] GC(8) Pause Young (Concurrent Start) (Metadata GC Threshold) 364M->59M(8192M) 135.170ms[2020-08-07T14:42:00.515+0800][25593] GC(9) Concurrent Cycle[2020-08-07T14:42:00.544+0800][25593] GC(9) Pause Remark 63M->63M(8192M) 3.422ms[2020-08-07T14:42:00.560+0800][25593] GC(9) Pause Cleanup 65M->65M(8192M) 0.432ms[2020-08-07T14:42:00.591+0800][25593] GC(9) Concurrent Cycle 75.614ms[2020-08-07T14:42:01.937+0800][25593] GC(10) Pause Young (Normal) (G1 Evacuation Pause) 447M->84M(8192M) 33.470ms[2020-08-07T14:42:02.786+0800][25593] GC(11) Pause Young (Normal) (G1 Evacuation Pause) 448M->117M(8192M) 42.285ms[2020-08-07T14:42:09.939+0800][25593] GC(12) Pause Young (Normal) (G1 Evacuation Pause) 1088M->730M(8192M) 60.019ms[2020-08-07T14:42:19.286+0800][25593] GC(13) Pause Young (Normal) (G1 Evacuation Pause) 1854M->769M(8192M) 51.429ms[2020-08-07T14:43:19.996+0800][25593] GC(14) Pause Young (Normal) (G1 Evacuation Pause) 4924M->770M(8192M) 43.029ms[2020-08-07T14:44:50.846+0800][25593] GC(15) Pause Young (Normal) (G1 Evacuation Pause) 6717M->771M(8192M) 50.404ms[2020-08-07T14:46:32.710+0800][25593] GC(16) Pause Young (Normal) (G1 Evacuation Pause) 7767M->774M(8192M) 41.461ms[2020-08-07T14:47:38.164+0800][25593] GC(17) Pause Young (Normal) (G1 Evacuation Pause) 5766M->855M(8192M) 48.741ms[2020-08-07T14:47:53.993+0800][25593] GC(18) Pause Young (Normal) (G1 Evacuation Pause) 5667M->809M(8192M) 40.445ms
和我们之前看到的详细日志相比,现在的日志已经显得清晰多了。对于线上ES的JVM而言,这些日志一般已经足够我们在出现问题时进行相应的排查了。当然,如果你需要了解JVM的详细工作情况,那么也可以将尽可能多tag的日志都打印出来以方便进行分析,具体需要哪些日志还是根据实际情况进行考虑。
最后再放一些其它的关于JVM GC LOG打印的参考文档
https://stackoverflow.com/q/54144713/4614538
GC logging - Elasticsearch
Setting JVM options - Elasticsearch
JEP 158: Unified JVM Logging
ES本身的Cache?
排除了GC的问题之后,我们又考虑到可能是ES本身的缓存失效导致的慢查询。验证方式非常简单,针对指定的索引我们调用ES清除缓存的接口清掉其缓存
POST /index-name/_cache/clear
清除掉缓存之后我们立即进行一次查询,发现该次查询耗时80ms左右。虽然清除缓存在一定程度上降低了查询速度,但是也并没有降低到800ms那么慢,可见ES缓存失效也不是偶发性慢查询的真正原因。因为如果是ES缓存失效导致的慢查询,那么在清除掉ES缓存之后查询速度也应该降低到800ms才对。
Page cache
我们知道在Linux操作系统中,内核是按页来管理内存的。如果想要访问磁盘上的一段数据,操作系统会分配一页(一般是4K)物理内存,之后把这些数据读取到这一页内存中以进行后续的操作。读取流程如下参考
- 进程调用库函数read发起读取文件请求
- 内核检查已打开的文件列表,调用文件系统提供的read接口
- 找到文件对应的inode,然后计算出要读取的具体的页
- 通过inode查找对应的页缓存
- 如果页缓存节点命中,则直接返回文件内容
- 如果没有对应的页缓存,则会产生一个缺页异常(page fault)
- 操作系统创建新的空的页缓存并从磁盘中读取文件内容,更新页缓存,然后重复第4步
- 读取文件返回
页缓存,也叫做文件缓存或磁盘缓存,它对于ES的核心部件Lucene十分重要。Lucene的读写文件十分依赖操作系统的页缓存来提高访问速度,以至于ES在官方文档中都提到ES的JVM进程只应该占用操作系统的一半物理内存,而把剩下的一半物理内存留给Lucene用作读写文件的页缓存。空闲内存越多,操作系统可用于Page Cache的内存也就越多,Lucene也就可以缓存越多的数据在内存中,这样就可以大大的提高Lucene的读写速度。当物理内存不足时,操作系统也会让部分缓存失效以空出内存空间。
需要注意的是,Page Cache是完全由操作系统控制的,程序无法干预。在程序读写文件时操作系统会自动的创建Page Cache来提高访问速度,但是在程序看来它只是进行了一次文件读写操作,而并不知道在读写操作背后操作系统具体是如何完成这次读写的、以及操作系统是否使用了缓存。
背景知识介绍到此。我们怀疑ES的偶发性慢查询是否是因为Page Cache的失效导致数据查询无法通过缓存获得,因此从磁盘上获取数据导致了比平时更长的查询时间呢?通过对慢查询发生时机器状态的监控我们发现,在发生慢查询时对应查询较慢的分片所在的机器节点CPU负载很低、内存空闲资源充足,并不存在内存资源不足的情况。因此应该并不是内存资源不足导致Page Cache失效而引发的慢查询。
index.search.idle.after
以上两个因素都不是偶发慢查询的真正原因,我们继续在Google上搜索相关的问题,最后我们发现了这个帖子。帖子里面提到了一个叫做 index.search.idle.after 的属性,它是在ES-7.0中新增的一个配置属性。
按照官方文档的说法,只要一个分片在 index.search.idle.after 时间段(默认30s)没有能够收到任何请求,就会进入search idle状态。
但是!!!按照官方文档的说法是即使进入了search idle状态,只要 index.refresh_interval 设置了刷新间隔,分片依旧会刷新,**这部分好像与事实不符**。
事实上,一旦分片进入了search idle状态,该分片就会停止refresh以节省资源(即使设置了index.refresh_interval)。等到后面再有search请求在该分片发生时,分片首先需要进行一次refresh,refresh完成之后才会执行真正的search。所以一旦分片进入search idle之后再次查询时就会比平时消耗更多的时间。
至此我们偶发性的慢查询问题就找到原因了。因为我们新的集群刚刚搭建不久,还处于测试阶段,所以我们只切了很少的一部分查询流量到新的集群,那么每个分片在两次查询之间的间隔就有可能会大于30s。而一个分片一旦30s都没有任何查询就会进入search idle状态,那么下一次的查询自然就会比普通的查询慢很多。
知道了原因之后我们就开始着手解决这个问题,目前有两个解决方案。
1. 修改index.search.idle.after的值
我们可以把 index.search.idle.after 值改大一些,避免分片频繁的进入search idle,例如我们可以把其从默认值30秒修改为5分钟
PUT /index-name/_settings{ "index.search.idle.after": "5m"}
修改完之后我们可以看下修改是否生效
GET /index-name/_settings
得到结果如下,可见该值已经被修改5m了
{ "index-name": { "settings": { "index": { "search": { "idle": { "after": "5m" } }, "number_of_shards": "2", ...省略部分内容... } } }}
当然我们也可以恢复该值的默认设置
PUT /index-name/_settings{ "index.search.idle.after": null}
2. 增加请求频率
上面我们介绍了第一个解决方案是增加进入idle的时间,还有一个办法是我们把更多的查询流量切到新的集群中去,这样因为查询之间的间隔变低,也就不会进入idle状态了。
考虑到我们已经测试了一段时间的新集群了,所以我们选择第二种方案把所有的查询流量都切到新集群中,查询频率增加后也没有再出现偶尔查询很慢的情况了。