数据说话:Go 1.26 或成近年来“问题最多”的大版本,现在升级安全吗?

本文永久链接 – https://tonybai.com/2026/03/06/go-1-26-most-problematic-release
大家好,我是Tony Bai。
2026 年 2 月,Go 1.26 如约而至。伴随着 new(expr) 语法糖的引入、Green Tea GC 的全面转正,以及go fix 现代化重构等一系列重磅特性,许多 Gopher 都按捺不住尝鲜的冲动。
然而,在经验丰富的 Go 团队和架构师群体中,流传着一条不成文的“潜规则”:永远不要在生产环境第一时间升级 X.Y.0 大版本,至少等到 X.Y.1 补丁发布后再做决定。
这条潜规则并非空穴来风。Go 的 1.N.0 版本虽然经过了长达半年的开发和 RC 阶段的测试,但只有当它真正被全球几百万开发者投入到千奇百怪的生产环境中时,那些隐藏在深处的边界 Bug 才会浮出水面。而 1.N.1 版本,正是官方对这“第一波真实世界火力测试”所暴露问题的集中修复。
因此,一个非常客观且有趣的推论诞生了:观察 1.N.1 里程碑下的 Issue 数量,可以作为衡量 1.N.0 初始质量的一张“晴雨表”。
最近,我在例行了解 Go 官方仓库的 GitHub 里程碑数据时,发现了一个令人警惕的信号:Go 1.26.1 的 Issue 数量,正在呈现出明显的“异常峰值”。
本文将用真实的数据说话,带你横向拉网式对比 Go 1.17 到 Go 1.26 这五年间、共十个大版本的初期质量水平,并深度拆解这些 Issue 的具体成分。Go 1.26 到底稳不稳定?现在升级安全吗?答案就在这些数据里。

核心数据全景:Go 1.26 的“异常峰值”
为了得出客观的结论,我利用 GitHub cli端gh工具 提取了从 Go 1.17.1 到 Go 1.26.1 的完整里程碑数据。这跨越了 Go 语言 2021 年至 2026 年的五年黄金发展期。
为了更直观地感受这组数据的冲击力,我们将其绘制成趋势图(数据采集于 2026 年 3 月4日晚):

从数据中读出的残酷真相
仔细审视这组数据,我们可以得出几个不容忽视的结论:
- 总量拉响警报:Go 1.26.1 的总 Issue 数目前已升至 39 个,直接打破了五年来历史最差的 Go 1.21.1 的记录(38 个)。这意味着它发布后暴露出的问题远超常规水平。
- 与“前任”形成鲜明对比:就在半年前发布的 Go 1.25,其 Go 1.25.1 补丁仅有 9 个 Issue,堪称近年来最稳定的“神仙版本”。Go 1.26 的问题数量是其四倍有余,这种断崖式的质量波动令人意外。
- 修复压力巨大:截至数据采集时,Go 1.26.1 仍有 17 个 Open Issue 亟待修复,官方团队正处于“救火”状态中,Go 1.26.1 补丁的发布可能还需要一些时间。
初步结论:Go 1.26 大版本的初始质量(Initial Quality)存在明显瑕疵,社区踩坑率偏高。

深度挖掘:为什么 Go 1.26 成了“重灾区”?
看到这里,你可能会问:Go 团队的开发流程一向严谨,为什么 1.26 会出现如此多的问题?
为了探寻真相,我没有停留在宏观数字上,而是将 Go 1.26.1 里程碑下的 全部 39 个 Issue 逐一扒开,按其性质进行了分类。不看不知道,一看吓一跳,这 39 个问题背后的成分大有玄机。

通过分类数据,我们可以清晰地看到导致 Go 1.26 翻车的“三大元凶”:
cmd/fix / modernize 相关:创新的“生长痛” (占比 33%)
这是 Go 1.26 核心新特性——全新的 go fix 自动代码现代化工具——直接引发的问题(约 13 个)。
静态分析并自动修改代码是一把双刃剑。在真实世界极其复杂的抽象语法树(AST)场景中,go fix 暴露出了一些“好心办坏事”的边界 Bug。例如:
- stringsbuilder 重写规则破坏了某些合法代码。
- rangeint 升级在某些跨平台场景下存在兼容问题。
- minmax 替换规则意外破坏了 select 语句的结构。
- waitgroup 检查器导致了误报的编译错误。
- … …
好消息是:这个类别虽然问题多,但大多数是被工具链“误伤”的语法层面的问题,且 绝大部分已被 Go 团队快速修复(目前该类别仅剩少数处于 Open 状态)。这说明 Go 团队对新特性的反馈响应非常迅速。
compiler/runtime 相关:最令人担忧的核心动荡 (占比 44%)
这是本次分析中最令人担忧的类别。多达 17 个 Issue 直指 Go 的心脏——编译器和运行时。
引入 Green Tea GC 全面转正、栈分配优化以及实验性的 SIMD 等底层变动,不可避免地触碰了最敏感的神经:
- 出现了多个 Internal Compiler Error (ICE),这意味着编译器在处理特定代码时直接崩溃了。
- 曝出了 runtime segfault / panic,这是运行时层面的致命错误。
- 32 位架构上的 timespec 定义错误。
- SIMD 实验特性的相关 Bug。
这些直击核心的问题中,有大约一半目前仍处于 Open(待修复)状态。底层 Bug 的修复往往需要极其谨慎的测试和论证,这可能会直接影响 Go 1.26 在高并发、复杂内存场景下的稳定性。
Regression (回归问题):亮起最高级别的红灯 (占比 10%)
虽然只有 4 个 Issue 被打上了 regression(回归)标签,但这是最严重的信号。回归意味着:在 Go 1.25 中能够正常编译和完美运行的代码,在什么都不改的情况下,升级到 Go 1.26 后却出错了!
这打破了 Go 最引以为傲的“向后兼容”承诺。这些回归问题包括:
- Synology Linux 环境下 fork syscall 发生冲突。
- 32 位 Android 系统下的 seccomp 问题。
- mipsle 架构下出现的 segfault。
- Windows 平台上 os.RemoveAll 行为异常(已修复)。
4 个 regression 问题中有 3 个至今尚未修复(Open)。这意味着,如果你恰好使用了相关的平台或系统接口,升级 Go 1.26 后将掉入一个“大坑”。
数据背后的真相总结
综合以上硬核拆解,我们得到了一张更为清晰的“风险热力图”:

理性决策:现在该升级 Go 1.26 吗?
数据虽然冰冷,但它为我们的技术决策提供了极其理性的支撑。面对目前 Go 1.26 这样一份成分复杂的“体检报告”,我为不同场景的开发者提供以下实操建议:
场景一:公司核心生产环境
强烈建议:暂缓升级,绝对按兵不动!
不要拿核心业务去为新编译器和新 Runtime 做“小白鼠”。鉴于存在多个未解决的 Compiler/Runtime Bug 和严重的 Regression 问题,至少要等到 Go 1.26.1 正式发布,仔细阅读其 Release Notes 确认相关雷区被排除后,再做评估。如果可能的话,我甚至建议那些对稳定性要求极高的金融或电商系统,等到 Go 1.26.2 发布后再进行灰度迁移。
场景二:团队的辅助工具 / 内部系统
建议:可以在本地或测试环境准备迁移,但不要上生产。
现在是让团队架构师开始在本地测试 Go 1.26 兼容性的好时机。你可以利用这段时间跑一遍全量的单元测试和集成测试,看看新的 Green Tea GC 是否对你们的特定负载有负面影响,或者有没有踩中那几个未修复的 Regression 雷区。
场景三:个人项目 / 新技术学习
建议:大胆升级,享受新特性。
对于没有历史包袱的个人项目,new(expr) 和强大的 go fix 绝对值得立刻体验。遇到 Bug 怎么办?去 GitHub 提 Issue!这也是参与开源社区建设、为 Go 生态排雷的绝佳方式。
小结:读懂版本号背后的语言演进
软件工程没有魔法,没有哪个大版本能在经历了底层大换血后依然完美无瑕。
Go 1.26.1 高达 39 个的 Issue 数量,以及占比极高的底层 Runtime/Compiler 报错,并不是在说“Go 团队不行了”,而恰恰反映了这门语言仍在保持着极其旺盛的生命力、以及为了追求更高性能而积极重构底层债务的勇气。
只不过,作为一线开发者和架构师,我们需要学会读懂这些数据发出的信号。在“享受技术红利”和“保障业务稳定”之间,让数据帮助我们找到最完美的平衡点。
最后,做个小调查:你目前在使用 Go 的哪个版本?是否有计划在近期升级到 1.26?欢迎在评论区分享你的看法!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
- 告别低效,重塑开发范式
- 驾驭AI Agent(Claude Code),实现工作流自动化
- 从“AI使用者”进化为规范驱动开发的“工作流指挥家”
扫描下方二维码,开启你的AI原生开发之旅。

你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
- 想写出更地道、更健壮的Go代码,却总在细节上踩坑?
- 渴望提升软件设计能力,驾驭复杂Go项目却缺乏章法?
- 想打造生产级的Go服务,却在工程化实践中屡屡受挫?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。

© 2026, bigwhite. 版权所有.









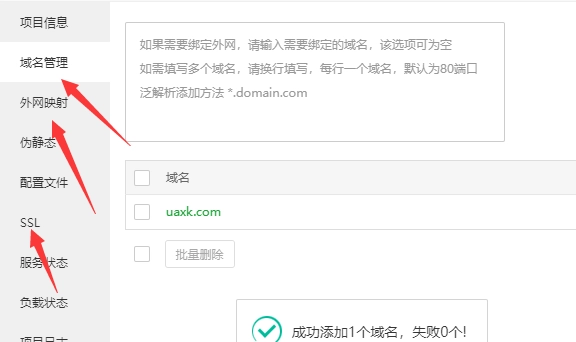
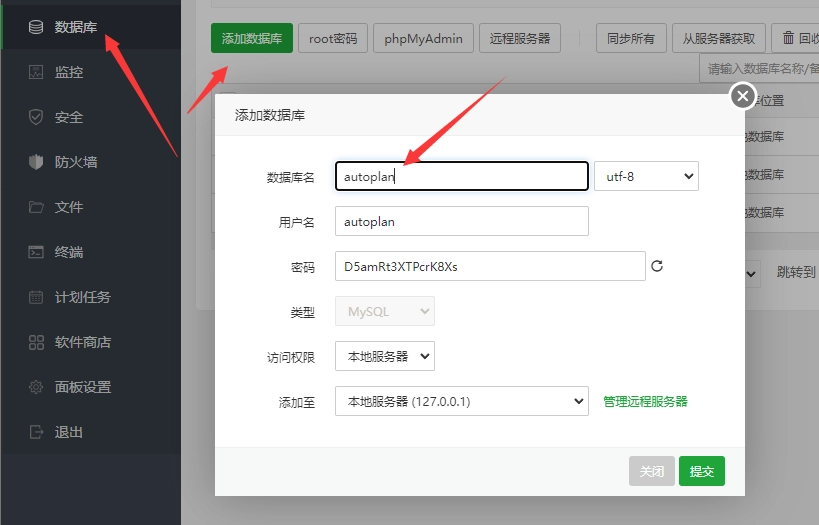
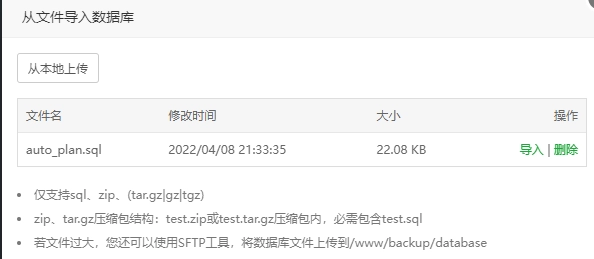
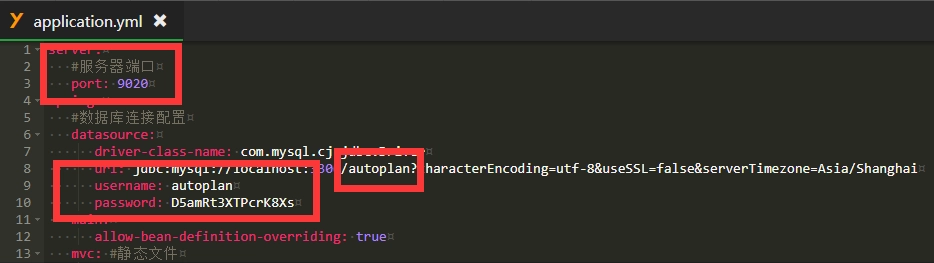 服务器端口及数据库配置信息需修改,其余信息可根据自定义修改
服务器端口及数据库配置信息需修改,其余信息可根据自定义修改 点击未启动,即可启动项目
点击未启动,即可启动项目