Claude Mythos 到底多可怕?准备加入核不扩散公约吗?

Anthropic 的最新模型 Mythos,到底强到什么程度了?会不会像核不扩散一样,被美国死死掐在手里?
今天咱们来聊一个很吓人的话题。Anthropic 最新曝光、后来又正式官宣的模型,叫 Claude Mythos Preview,中文大概可以叫“克劳德·神话预览版”。它到底有多吓人?
Mythos 为什么引发巨大关注

这个模型,之前我们还分析过。从名字上看,它绝对不是 5.0 这样的普通版本升级,而更像是规模上的扩大。所以以后 Anthropic 的模型,可能每次升级就是 Mythos、Opus、Sonnet 和 Haiku 一起升级。
Haiku 是很小的、讲究音节的诗,Sonnet 是十四行诗,Opus 是作品、篇章,而 Mythos 是神话。从命名上来看,这个东西应该是非常非常强大的。
这一次发布有一个非常神奇的地方,就是它不给别人用。我发布了,但并不向大家公开,不让大家直接使用。它开了一个计划,叫“玻璃翅膀计划”。
“玻璃翅膀计划”到底是什么意思

为什么要用这样的方式?因为这个东西实在太危险了。Anthropic 当时就在讲,Mythos 在网络安全方面非常强,可以去攻击漏洞,也可以去发现漏洞。
一旦拿出来,现有的操作系统、网络设备以及芯片,很多问题可能都会被它找出来,而且它还可以自动去攻击。这件事情实在太危险了。
那怎么办?Anthropic 邀请了一些友好的合作伙伴,先把这个产品拿出来,把漏洞补上,补完以后再说。它做了这样一个“玻璃翅膀计划”。
这个名字也让人想到一个神话故事:有人用蜡做的翅膀飞向太阳,最后离太阳太近,翅膀化掉了,人就摔死了。所以这个“玻璃翅膀计划”,按照 Anthropic 一贯喜欢用“人类”“故事”一类命名规则来看,应该也是一个类似寓意的名字。
Mythos 可怕在哪:不只是找漏洞,还可能自动利用漏洞
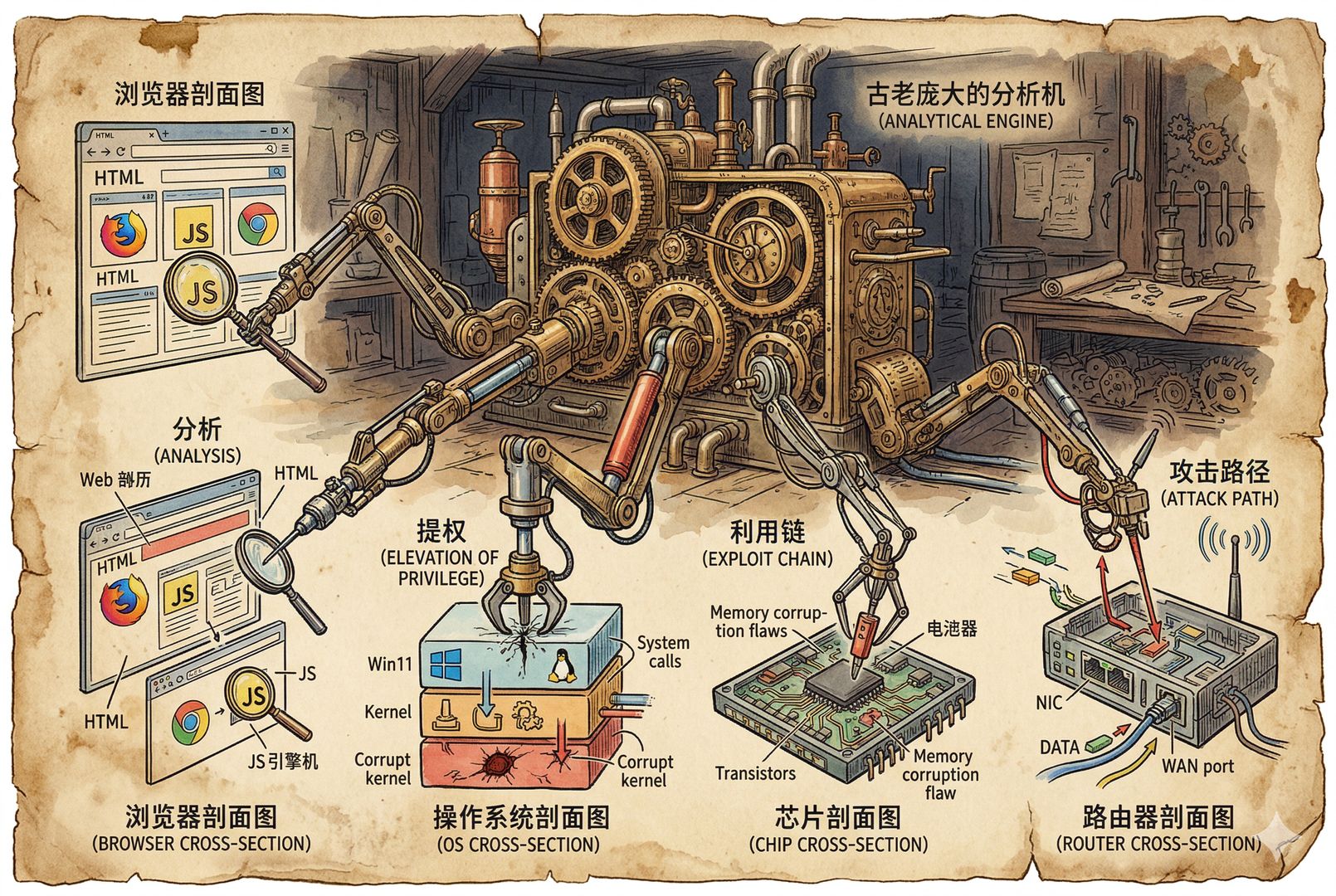
那么 Mythos 到底有多吓人?很明显,Anthropic 担心这样的模型一旦流出,坏人就可以用。用 Anthropic 的话来说,Mythos 是一个“两用技术”。我们现在也经常讲两用技术,就是既可以民用,也可以军用。所以它显然也具备做军用用途的可能。
据说它在训练过程中就发现了数以千计的额外高危或严重级别漏洞,非常非常多。你会说,我们这么多系统,积累了这么多年,也是人类智慧的结晶,怎么会千疮百孔?
其实很简单。当一个系统复杂度达到一定程度以后,里面一定会有一些以人力无法找到的漏洞。人力有时而穷,但现在有了 AI,它就可以把这些原来靠人力找不到的问题,通通给你找出来。
所以我们以前使用的各种防护系统、操作系统、网络设备、芯片,在 Mythos 面前,基本上可以认为是在裸奔了。这是一个非常危险的事情。
而且它不仅能找,还会打。传统上,很多模型或者工具更多是辅助分析,比如我拿你的源代码分析一下,看看哪里可能有问题。Mythos 让人紧张的地方就在于,它已经不只是告诉你哪里可能有 bug 了,它还可以进一步参与:
- 漏洞分析
- 利用链的构成
- 攻击路径的演练
- 提权链的拼接
- 更复杂的漏洞利用代码开发
所谓“提权”,就是我进去以后把自己的权限提高。它甚至可以直接写出漏洞利用代码,把漏洞打开。它还可能直接突破主流操作系统和主流浏览器。
Anthropic 的公开材料里写过,Mythos 在每一个主要网页浏览器中都识别并利用了漏洞。相当于某种病毒突然进化到让所有抗生素、所有免疫系统都拿它没办法的地步了。
Anthropic 已公开了哪些信息
那它到底发现了哪些漏洞?现在 Anthropic 其实已经公开了一些,但严格来说,这叫“负责任的披露”。
什么是“负责任的披露”

很多黑客其实没有自己发现漏洞的能力,他们怎么攻击别人?他们看新闻,看到哪里有漏洞被公开了,就去打那里。那为什么公开的漏洞还能被利用?因为你升级升不过来。
今天这边说某个漏洞发现了、补丁出了,结果你那边还没补,很多黑客就是干这样的事情。
所谓负责任的披露,可能就是说:
- 我告诉你哪有漏洞了,但我不告诉公众具体漏洞细节
- 同时我会通知厂商
- 还要等厂商自己决定怎么公开、怎么让用户升级
比如告诉苹果,你家的操作系统和浏览器有什么问题;告诉谷歌,你家的 Android 和 Chrome 有什么问题。并且在告诉之后,还要等厂商自己决定怎么公开、怎么让用户升级。
现在真正被点名的,其实只是少数案例,大量案例还没有说出来。
目前提到的典型案例
比如,OpenBSD 有一个 27 年的老 bug 被它找到了,27 年都没人发现。OpenBSD 是什么?我们现在使用的苹果 macOS、iOS、iPadOS,这些系统的底层都和 BSD 有很深的关系。还有任天堂 Switch、索尼 PS5,底层也都和 BSD 有关系。这样一个老漏洞被它拎了出来。
另外,FreeBSD 一个 17 年的远程代码执行漏洞也被找到了。BSD 本身也有很多分支。Linux 内核的本地提权链条也被它找到了,它可以直接进入 Linux 内核里提权。
你可能说我又不是服务器,但安卓手机的核心就是 Linux。只要你是安卓手机,它就可以通过 Linux 内核提权链条把权限提上去。
至于主流浏览器,Anthropic 官方已经确认,Mythos 在主流浏览器中识别并利用了漏洞,但细节没有公开。浏览器其实比操作系统还复杂,因为浏览器要打开网页,而每个网页里实际上有很多很多 JavaScript 代码,这些代码可以利用浏览器漏洞做各种事情,这就非常危险,所以这部分它不敢细说。
Anthropic 是怎么官宣 Mythos 的

Anthropic 的官宣时间线也很值得注意:
- 2026 年 3 月 26 日,媒体先发现了端倪。《财富》杂志说他们发现 Anthropic 的 CMS 系统泄露了一个新模型名字,叫 Mythos。
- 2026 年 4 月 7 日,Anthropic 正式官宣,说我们有一个“玻璃翅膀计划”。
- 同时放出了 Claude Mythos Preview System Card,也就是预览版系统卡。
- 此外还发布了一些安全研究文章,以及平台上的 release notes,也就是更新说明。
这些都是正式发布出来的材料。
第一批参与“玻璃翅膀计划”的组织有哪些

但是,到底给谁用、不给谁用?这就涉及参与项目的名单了。第一批大概包括以下这些组织:
- Amazon AWS:亚马逊云科技。上面有大量云主机,如果这块搞不明白,风险极大。
- 苹果:有 iOS、macOS、iPhone、Safari 浏览器,还有自己的芯片,漏洞必须赶紧补。
- 博通:做各种 ASIC 芯片,比如谷歌 TPU,很多定制算力芯片也与它相关。
- Cisco 思科:专门做路由器,网络攻击里路由器一定是重点目标。
- CrowdStrike:专门做网络安全防护的公司。
- 谷歌:Android、Chrome 都在里面,底层还有 Linux。
- JPMorgan 摩根大通:银行系统也要做预案和补救准备。
- Linux Foundation:Linux 基金会下面有大量开源项目需要一起补。
- 微软:有操作系统、Office、网络设备和云服务。
- 英伟达
- Palo Alto Networks:大型网络安全公司。
- Anthropic 自己
后面官方说还会逐渐扩充到 40 多家额外组织,但这些额外组织到底能不能拿到完整的 Mythos,这事就不好说了。刚才点名的这些公司,具体怎么用 Mythos,其实也没有说得特别清楚。
所以现在能看到的情况是:模型出来了,但先别发布给公众。先把受影响的基础设施拉个小群,封闭起来,把 bug 修一修,然后再说后面的事。
Mythos 以后会开放给公众吗
那是不是等 bug 修完以后,Mythos 就可以开放了?这个还真不好说。所以前面才会说,这件事情有点像核不扩散协议的玩法。
Anthropic 当前的逻辑是:先给少数可信的合作方使用,先帮助关键系统、关键软件、关键开源项目找漏洞并修补。在这个过程中,建立更强的安全措施和防护机制,也就是安全护栏。然后再看未来怎么安全地部署“Mythos 级别”的模型。
这里“级别”这两个字很关键,意思不是说一定把原生 Mythos 放出来,而是可能放出具有类似能力的产品。也就是说,普通人很可能永远都看不到原生的 Mythos 模型了。
Anthropic 有没有说什么时候开放给公众?截至目前,没有给出开放时间表。而且官方说得非常明确:我们不计划让 Claude Mythos Preview 普遍可用。
也就是说,他们压根没打算把这个版本全面开放。它的意思并不是永远不会有类似能力的产品发布,而是当前这个 Preview 版本不准备全民开放。未来在他们认为比较安全的时候,可能会开放一些 Mythos 级别的产品出来。至于到那个时候产品是什么样,现在不好说。
这像不像“AI 版核不扩散”

这就有点像核能利用。高浓缩铀谁都不允许有,但你要和平利用核能,比如做放射医疗,或者建核电站,使用低浓缩铀,是不是可以?未来 Mythos 级别产品,也可能朝这个方向发展。
至于 Mythos 的价格,现在也没有完全公开。很多报道说没有明确价格,但成本太高,这东西实在太贵,普通人就算给你用,你也用不起。
这个大家其实可以想象,它可能是一个极其巨大的模型。Opus 就已经比 Sonnet 大很多了,那 Mythos 很可能比 Opus 还大。整个模型跑起来,可能非常非常不经济,这也可能是它没办法向公众开放的原因之一。
当然,也许未来硬件成本进一步下降,比如显卡算力变得更便宜,这个东西才有可能开放出来。成本可承受了,才有机会普及。
至于前面那些参加项目的组织,Anthropic 也给出了参与方价格,但普通人肯定拿不到:
- 输入价格:每百万 Token 25 美元
- 输出价格:每百万 Token 125 美元
比现在常见模型贵很多,普通人目前根本没法用。
它会不会被美国严控
那么最敏感的问题来了:它会不会像核不扩散一样被美国严控?
首先讲,目前没有明确证据表明 Mythos 已经进入了类似核不扩散那样的正式国际治理架构。这更像是一个标题上的类比。但是从战略效果上说,它确实已经出现了一点“高端网络能力受控扩散”的意味。
Anthropic 自己也说这是一个两用技术。既然是两用的,那到底给谁用、不给谁用,怎么防止别人用上,这就是他们真正要思考的问题。
因为你看 OpenAI 不给中国大陆直接用,其实也不是真的拦得住。我们可以去美国建机房,可以在新加坡建机房,照样可以用。我想蒸馏你,你一点都拦不住。所以这种两用能力到底怎么管控,是个很现实的问题。
可以从三个层次理解这件事
第一层:它不是核武器,但像网络安全时代的战略工具
核武器的特点是极端稀缺、门槛极高、扩散极敏感。Mythos 这样的模型未必有核武器那种一锤定音的破坏力,但它可能在另一个维度上造成类似效果:
- 谁先拿到,谁就更快找到漏洞
- 谁先拿到,谁就更快修补自己的系统
- 谁先拿到,谁也更可能让别人的系统直接崩溃
所以它不是现实中的炸弹,但它可能是网络安全系统上的一颗巨大炸弹。
第二层:先发优势非常巨大
如果美国公司和美国盟友的关键厂商先拿到这种能力,那他们至少在几个维度上会比别人更快:
- 更快发现自己系统的问题
- 更快补上开源和商用组件上的问题
- 更快建立 AI + 漏洞治理 + 补丁分发的新体系
在这里,时间差非常重要。
第三层:未必是永久垄断,但一定是阶段性领先
它不像核武器那样,别人几十年也追不上。因为网络安全最终还是要落到补丁、配置、代码审计、供应链治理、自动更新系统这些基础工作上。
也就是说,后发国家并不是完全没路,但这个时间差非常要命。
下面这些属于大胆猜测,不是已证实事实
猜测一:Mythos 的意义可能是一条漏洞发现工业化流水线
过去找漏洞靠的是顶级研究员长时间审计少量高价值目标,而 Mythos 可能代表着把漏洞发现、利用链拼接、风险评估、修复建议,推向半自动化、规模化和工业化。
原来很多虽然做得很烂,但没有太大被利用价值的系统,烂也就烂了;有了 Mythos 这样的模型以后,可能全都暴露出来。
猜测二:Anthropic 不公开,不只是出于道德
第二种猜测,Anthropic 现在不公开,不只是出于道德,也可能是因为这个东西太敏感、太贵、太难控制。官方当然会强调安全和负责任,这没有问题,但从现实角度看,可能还叠加了几层原因。
原因一:太危险
拿到这样的系统以后,整个世界都可能变得更可怕,而且太容易被国家级攻击者利用。之前就有说法称,有中国团队曾利用 Opus 模型去写各种攻击代码。一旦 Mythos 这种模型被攻破或者被越狱,后果会非常可怕。
这有点像什么?像锦衣卫监察百官,然后又建立东厂监察锦衣卫,再建立西厂监察东厂。你说如果锦衣卫、东厂、西厂自己腐败了,或者被人攻破了,那危害就极大。
现在等于 Mythos 站在最上面,它成了新的监督者。一旦它被越狱,这件事就很难控制。
原因二:容易引发监管震荡
另外,这个产品太容易引发监管震荡。再加上它的算力成本太高,一旦开放,输出边界基本没法控制。
猜测三:未来最吃亏的是补丁链条慢、设备老旧、升级困难的系统
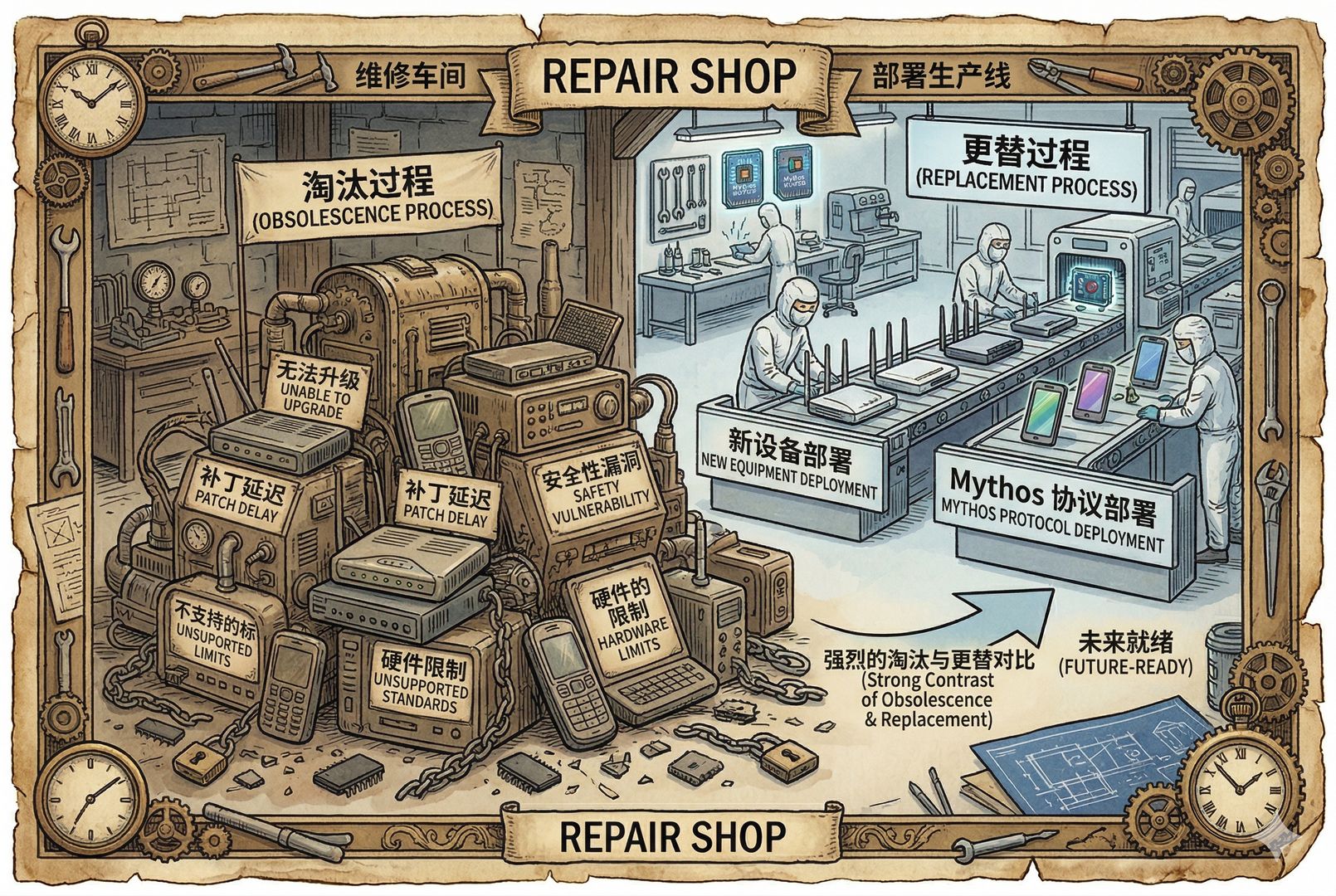
以后最吃亏的,不是没有大模型的国家,而是补丁链条慢、设备老旧、升级困难的系统。比如中国现在大量系统,其实也是拿 Linux 改一改,或者拿 Android 改一改。别听那些吹牛,说什么从头自主研发、自主知识产权。很多底层漏洞,你还是得等 Linux 那边去修。
但问题是,Linux 修了,我们也打上了,中国这些系统就安全吗?平时不打仗,可能看起来没毛病。但你真到冲突环境里,你相信别人会把所有漏洞都补给你吗?会不会自己留两个?你要是完完全全相信对方是好人,那就太天真了。
当然,还有像鸿蒙这种号称从头自己做、没有参考其他系统的东西。那你就没法直接跟着别人的补丁体系去升级。以后如果我们自己做不出同样级别的能力,这种号称完全自主开发的操作系统、浏览器或者各种编译系统,就没有任何安全性可言。你没有参与到这个圈子里,问题就会很大。
Mythos 可能带来的现实变化
这种系统出来以后,会带来什么变化?一个非常现实的变化就是“以旧换新”必须加快推进。为什么?因为不是所有系统都可以打补丁,不是所有设备都能把漏洞补上。有很多设备根本没法整。
比如华为在全世界卖了那么多网络通信设备,你现在又没有被邀请进那个补丁体系里,人家做的各种修补你未必用得上。因为你自己号称自主研发、自主知识产权。那么这些设备可能就该以旧换新了。
所以,Mythos 模型的发布,可能会极大推进全世界华为设备的淘汰。这也是一种推测。
另一个猜想:Claude Gov 可能已经在用 Mythos
还有一个猜想:Claude Gov 可能早就已经用上 Mythos 了。这纯属猜测,没有事实依据。
因为美国、以色列和伊朗之间的冲突里,很多人都在说,伊朗内部各种网络安全设施形同虚设,漏洞多得像筛子,间谍也好,内鬼也好,到处都是。
可你要想清楚,很多高职位的内鬼未必懂计算机,低职位的人又未必有能力决定重大行动。但现在伊朗各种内部安全系统,包括监控系统,看上去就像给美国开着地图打仗一样。那是不是 Mythos 已经在里面干活了?这只是个人猜测,没有任何事实依据。
最后的判断:Mythos 的真正危险是什么

最后给一个完整判断。
Anthropic 的 Mythos 不是核武器,但它有一定的“核属性”。它是两用技术,是战略能力倍增器,可以看成网络安全领域的战略能力倍增器。
它最可怕的,不是能找到几个 bug,而是它可能意味着:
- 漏洞发现被规模化
- 利用开发被自动化
- 防守与进攻之间的时间差被急剧压缩
原来我发现问题了,到真正攻击你,中间还有一段时间,你还能补。现在这个时间差可能直接就没了。
关键基础设施里的老旧系统,必须加速以旧换新,因为这些系统会越来越不安全。谁先掌握这类模型,谁就能掌握安全节奏。
而 Anthropic 现在的做法,说白了就是一句话:这东西太强,强到不能像普通模型那样,先扔给所有人再说。
所以今天大家最该盯住的,已经不是它会不会写诗、会不会做题,而是它会不会把全球网络安全正式推进到一个 AI 大规模找漏洞的新阶段。因为一旦到了这个阶段,全球网络可能会出现大规模震荡。
如果真到了这一步,Mythos 也许不是终点,它只是第一个开枪的人。就像美国在广岛扔下原子弹以后,斯大林马上就下令必须去做一样。我相信国内的各种安全公司、大模型公司,现在应该也在奋起直追。
这个事情,还是非常非常危险的。
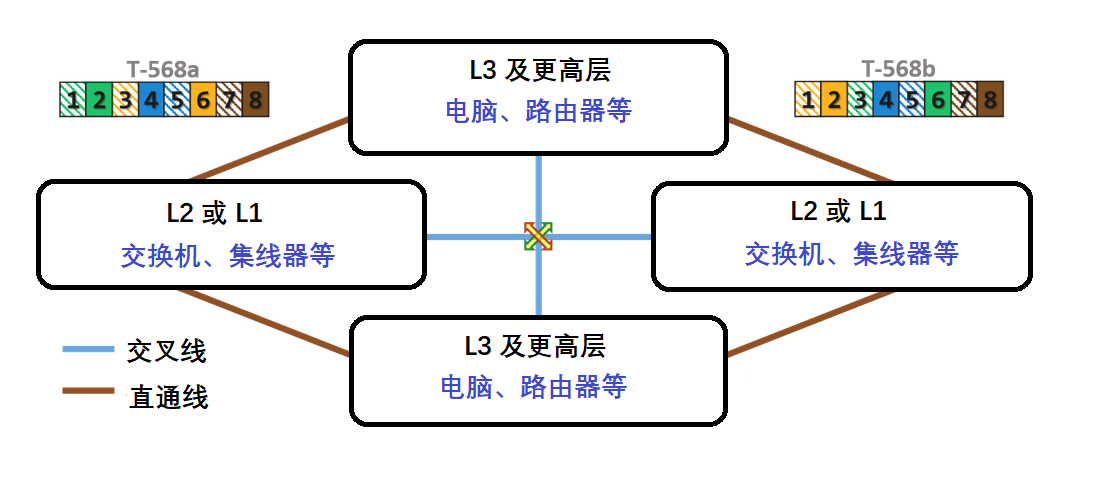
背景图片





 最后的感想:不要等到自己觉得“准备好了”再开始。你的旅程始于第一个视频。按下录制键、上传,然后让全世界看到你想分享的东西吧。
最后的感想:不要等到自己觉得“准备好了”再开始。你的旅程始于第一个视频。按下录制键、上传,然后让全世界看到你想分享的东西吧。