In this part of the Cache Lab, the mission is simple yet devious: optimize matrix transposition for three specific sizes: 32x32, 64x64, and 61x67. Our primary enemy? Cache misses.
Matrix Transposition
A standard transposition swaps rows and columns directly:
1 2 3 4 5 6 7 8 9 10 11 12
voidtrans(int M, int N, int A[N][M], int B[M][N]) { int i, j, tmp;
for (i = 0; i < N; i++) { for (j = 0; j < M; j++) { tmp = A[i][j]; B[j][i] = tmp; } }
}
While correct, this approach is a cache-miss nightmare because it ignores how data is actually stored in memory.
Cache Overview
To optimize effectively, we first have to understand our hardware constraints. The lab specifies a directly mapped cache with the following parameters:
Parameter
Value
Sets (S)
32
Block Size (B)
32 bytes
Associativity (E)
1 (Direct-mapped)
Integer Size
4 bytes
Capacity per line
8 integers
We will use Matrix Tiling and Loop Unrolling to optimize the codes.
32x32 Case
In this case, a row of the matrix needs 32/8 = 4 sets of cache to store. And cache conflicts occur every 32/4 = 8 rows. This makes 8x8 tiling the sweet spot.
By processing the matrix in 8×8 blocks, we ensure that once a line of A is loaded, we use all 8 integers before it gets evicted. We also use loop unrolling with 8 local variables to minimize the overhead of accessing B.
Since 61 and 67 are not powers of two, the conflict misses don’t occur in a regular pattern like they do in the square matrices. This “irregularity” is actually a blessing. We can get away with simple tiling. A 16x16 block size typically yields enough performance to pass the miss-count threshold.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
int BLOCK_SIZE = 16; int i,j,k,l,tmp; int a,b; for(i = 0; i<N; i+=BLOCK_SIZE){ for(j = 0; j<M; j+=BLOCK_SIZE){ a = i+BLOCK_SIZE; b = j+BLOCK_SIZE; for(k = i; k<N && k<a; k++) { for(l = j; l<M && l<b; l++){ tmp = A[k][l]; B[l][k] = tmp; } } } }
64x64 Case
This is the hardest part. In a 64x64 matrix, a row needs 8 sets, but conflict misses occur every 32/8=4 rows. If we use 8x8 tiling, the bottom half of the block will evict the top half.
We can try a 4x4 matrix tiling first.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
int BLOCK_SIZE = 4; int i,j,k,l,tmp; int a,b; for(i = 0; i<N; i+=BLOCK_SIZE){ for(j = 0; j<M; j+=BLOCK_SIZE){ a = i+BLOCK_SIZE; b = j+BLOCK_SIZE; for(k = i; k<N && k<a; k++) { for(l = j; l<M && l<b; l++){ tmp = A[k][l]; B[l][k] = tmp; } } } }
But this isn’t enough to pass the miss-count threshold.
We try a 8x8 matrix tiling. We solve this by partitioning the 8×8 block into four 4×4 sub-blocks and using the upper-right corner of B as a “buffer” to store data temporarily.
int i, j, k; int tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7, tmp8;
// Iterate through the matrix in 8x8 blocks to improve spatial locality for (i = 0; i < N; i += 8) { for (j = 0; j < M; j += 8) { /** * STEP 1: Handle the top half of the 8x8 block (rows i to i+3) */ for (k = 0; k < 4; k++) { // Read 8 elements from row i+k of matrix A into registers tmp1 = A[i + k][j]; tmp2 = A[i + k][j + 1]; tmp3 = A[i + k][j + 2]; tmp4 = A[i + k][j + 3]; // Top-left 4x4 tmp5 = A[i + k][j + 4]; tmp6 = A[i + k][j + 5]; tmp7 = A[i + k][j + 6]; tmp8 = A[i + k][j + 7]; // Top-right 4x4
// Transpose top-left 4x4 from A directly into top-left of B B[j][i + k] = tmp1; B[j + 1][i + k] = tmp2; B[j + 2][i + k] = tmp3; B[j + 3][i + k] = tmp4;
// Temporarily store top-right 4x4 of A in the top-right of B // This avoids cache misses by using the already-loaded cache line in B B[j][i + k + 4] = tmp5; B[j + 1][i + k + 4] = tmp6; B[j + 2][i + k + 4] = tmp7; B[j + 3][i + k + 4] = tmp8; }
/** * STEP 2: Handle the bottom half and fix the temporary placement */ for (k = 0; k < 4; k++) { // Read bottom-left 4x4 column-wise from A tmp1 = A[i + 4][j + k]; tmp2 = A[i + 5][j + k]; tmp3 = A[i + 6][j + k]; tmp4 = A[i + 7][j + k]; // Read bottom-right 4x4 column-wise from A tmp5 = A[i + 4][j + k + 4]; tmp6 = A[i + 5][j + k + 4]; tmp7 = A[i + 6][j + k + 4]; tmp8 = A[i + 7][j + k + 4];
// Retrieve the top-right elements we temporarily stored in B in Step 1 int t1 = B[j + k][i + 4]; int t2 = B[j + k][i + 5]; int t3 = B[j + k][i + 6]; int t4 = B[j + k][i + 7];
// Move bottom-left of A into the top-right of B B[j + k][i + 4] = tmp1; B[j + k][i + 5] = tmp2; B[j + k][i + 6] = tmp3; B[j + k][i + 7] = tmp4;
// Move the retrieved temporary values into the bottom-left of B B[j + k + 4][i] = t1; B[j + k + 4][i + 1] = t2; B[j + k + 4][i + 2] = t3; B[j + k + 4][i + 3] = t4;
// Place bottom-right of A into the bottom-right of B B[j + k + 4][i + 4] = tmp5; B[j + k + 4][i + 5] = tmp6; B[j + k + 4][i + 6] = tmp7; B[j + k + 4][i + 7] = tmp8; } } }
Note: The key trick here is traversing B by columns where possible (so B stays right in the cache) and utilizing local registers (temporary variables) to bridge the gap between conflicting cache lines.
Conclusion
Optimizing matrix transposition is less about the math and more about mechanical sympathy—understanding the underlying hardware to write code that plays nice with the CPU’s cache.
The jump from the naive version to these optimized versions isn’t just a marginal gain; it’s often a 10x reduction in cache misses. It serves as a stark reminder that in systems programming, how you access your data is just as important as the algorithm itself.
A cache can be described with the following four parameters:
S=2s (Cache Sets): The cache is divided into sets.
E (Cache Lines per set): This is the “associativity.”
If E=1, it’s a direct-mapped cache. If E>1, it’s set-associative.
Each line contains a valid bit, a tag, and the actual data block.
B=2b (Block Size): The number of bytes stored in each line.
The b bits at the end of an address tell the cache the offset within that block.
m: The bits of the machine memory address.
2. Address Decomposition
When the CPU wants to access a 64-bit address, the cache doesn’t look at the whole number at once. It slices the address into three distinct fields:
Field
Purpose
Tag
Used to uniquely identify the memory block within a specific set. t = m - b - s
Set Index
Determines which set the address maps to.
Block Offset
Identifies the specific byte within the cache line.
3. The “Search and Match” Process
When our simulator receives an address (e.g., from an L or S operation in the trace file), it follows these steps:
Find the Set: Use the set index bits to jump to the correct set in our cache structure.
Search the Lines: Look through all the lines in that set.
Hit: If a line has valid == trueAND the tag matches the address tag.
Miss: If no line matches.
Handle the Miss:
Cold Start: If there is an empty line (valid == false), fill it with the new tag and set valid = true.
Eviction: If all lines are full, we must kick one out. This is where the LRU (Least Recently Used) policy comes in: we find the line that hasn’t been touched for the longest time and replace it.
Lab Requirements
For this Lab Project, we will write a cache simulator that takes a valgrind memory trace as an input.
Input
The input looks like:
1 2 3 4
I0400d7d4,8 M0421c7f0,4 L04f6b868,8 S7ff0005c8,8
Each line denotes one or two memory accesses. The format of each line is
1
[space]operation address,size
The operation field denotes the type of memory access:
“I” denotes an instruction load, “L” a data load,
“S” a data store
“M” a data modify (i.e., a data load followed by a data store).
Mind you: There is never a space before each “I”. There is always a space before each “M”, “L”, and “S”.
The address field specifies a 64-bit hexadecimal memory address. The size field specifies the number of bytes accessed by the operation.
CLI
Our program should take the following command line arguments:
getopt comes in unistd.h, but the compiler option is set to -std=c99, which hides all POSIX extensions. GNU systems provide a standalone <getopt.h> header. So we include getopt.h instead.
1
opt = getopt(argc, argv, "hvs:E:b:t:")
h and v: These are boolean flags.
s:, E:, b:, and t:: These are required arguments. The colon tells getopt that these flags must be followed by a value (e.g., -s 4).
After parsing the arguments, we set the initial value of our Cache Data Model.
fscanf does not skip spaces before %c, so we add a space before %c in the format string.
!feof(traceFile) does not work correctly here.It only returns true after a read operation has already attempted to go past the end of the file and failed. Using it as a loop condition (e.g., while (!feof(p))) causes an “off-by-one” error, where the loop executes one extra time with garbage data from the last successful read.
voidloadData(longlong address, int size) { // Simulate accessing data at the given address int s = getSetIndex(address); longlong t = getTag(address); global_timer++;
for (int i = 0; i < associativity; i++) { if (cache[s][i].valid && cache[s][i].tag == t) { hit_count++; cache[s][i].lru_counter = global_timer; if (verboseMode) printf(" hit"); return; } }
miss_count++; if (verboseMode) printf(" miss");
for (int i = 0; i < associativity; i++) { if (!cache[s][i].valid) { cache[s][i].valid = true; cache[s][i].tag = t; cache[s][i].lru_counter = global_timer; return; } }
eviction_count++; if (verboseMode) printf(" eviction");
int victim_index = 0; int min_lru = cache[s][0].lru_counter;
for (int i = 1; i < associativity; i++) { if (cache[s][i].lru_counter < min_lru) { min_lru = cache[s][i].lru_counter; victim_index = i; } }
We first check if the data already exists in the cache.
If it doesn’t exist, we have to scan for blank lines to load the data.
If blank lines don’t exist, we need to evict a line using the LRU strategy. We replace the victim line with the new line.
Other Operations
1 2 3 4 5 6 7 8 9 10 11
voidstoreData(longlong address, int size) { // Simulate storing data at the given address loadData(address, size); }
voidmodifyData(longlong address, int size) { // Simulate modifying data at the given address loadData(address, size); hit_count++; if (verboseMode) printf(" hit\n"); }
For this simulator, storing data and modifying data are basically the same thing as loading data.
Print Summary
We are asked to output the answer using the printSummary function.
In this project, we moved from the theory of hierarchy to the practical reality of memory management. By building this simulator, we reinforced several core concepts of computer systems.
With our simulator passing all the trace tests, we’ve effectively mirrored how a CPU “thinks” about memory. The next step is applying these insights to optimize actual code, ensuring our algorithms play nicely with the hardware we’ve just simulated.
// edx = 14, esi = 0, edi = a intfunc4(int edi, int esi, int edx){ int mid = l + ((r-l)>>1); if(mid <= a){ if(mid==a){ return0; } l = mid + 1; return2*func4(a, l, r) + 1; }else{ r = mid - 1; return2*func4(a, l, r); } }
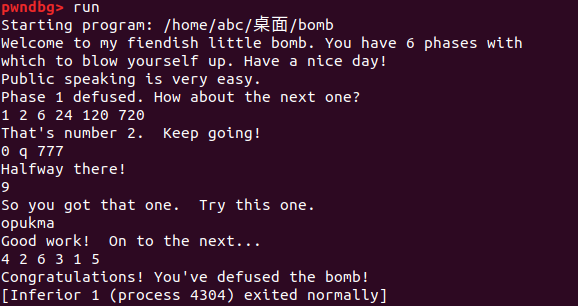
/* Hmm... Six phases must be more secure than one phase! */ input = read_line(); /* Get input */ phase_1(input); /* Run the phase */ phase_defused(); /* Drat! They figured it out! * Let me know how they did it. */ printf("Phase 1 defused. How about the next one?\n");
/* The second phase is harder. No one will ever figure out * how to defuse this... */ input = read_line(); phase_2(input); phase_defused(); printf("That's number 2. Keep going!\n");
/* I guess this is too easy so far. Some more complex code will * confuse people. */ input = read_line(); phase_3(input); phase_defused(); printf("Halfway there!\n");
/* Oh yeah? Well, how good is your math? Try on this saucy problem! */ input = read_line(); phase_4(input); phase_defused(); printf("So you got that one. Try this one.\n");
/* Round and 'round in memory we go, where we stop, the bomb blows! */ input = read_line(); phase_5(input); phase_defused(); printf("Good work! On to the next...\n");
/* This phase will never be used, since no one will get past the * earlier ones. But just in case, make this one extra hard. */ input = read_line(); phase_6(input); phase_defused();
undefined behavior - There are no restrictions on the behavior of the program.
有符號整數溢位是一種常見的未定義行為。
Because correct C++ programs are free of undefined behavior, compilers may produce unexpected results when a program that actually has UB is compiled with optimization enabled.
也就是說,編譯器最佳化會對未定義行為產生意料之外的結果
cppreference 給出了一個整數溢位的例子:
1 2 3 4 5
intfoo(int x) { return x + 1 > x; // either true or UB due to signed overflow }
編譯之後卻變成了
1 2 3
foo(int): mov eax, 1 ret
意思是,不管怎麼樣都輸出 1
觀察出錯程式碼
我們透過 gcc -S 輸出編譯後的彙編程式碼
1 2 3 4 5 6 7
_Z6isTmaxi: .LFB2: .cfi_startproc endbr64 movl$0, %eax ret .cfi_endproc
In this part of the Cache Lab, the mission is simple yet devious: optimize matrix transposition for three specific sizes: 32x32, 64x64, and 61x67. Our primary enemy? Cache misses.
Matrix Transposition
A standard transposition swaps rows and columns directly:
1 2 3 4 5 6 7 8 9 10 11 12
voidtrans(int M, int N, int A[N][M], int B[M][N]) { int i, j, tmp;
for (i = 0; i < N; i++) { for (j = 0; j < M; j++) { tmp = A[i][j]; B[j][i] = tmp; } }
}
While correct, this approach is a cache-miss nightmare because it ignores how data is actually stored in memory.
Cache Overview
To optimize effectively, we first have to understand our hardware constraints. The lab specifies a directly mapped cache with the following parameters:
Parameter
Value
Sets (S)
32
Block Size (B)
32 bytes
Associativity (E)
1 (Direct-mapped)
Integer Size
4 bytes
Capacity per line
8 integers
We will use Matrix Tiling and Loop Unrolling to optimize the codes.
32x32 Case
In this case, a row of the matrix needs 32/8 = 4 sets of cache to store. And cache conflicts occur every 32/4 = 8 rows. This makes 8x8 tiling the sweet spot.
By processing the matrix in 8×8 blocks, we ensure that once a line of A is loaded, we use all 8 integers before it gets evicted. We also use loop unrolling with 8 local variables to minimize the overhead of accessing B.
Since 61 and 67 are not powers of two, the conflict misses don’t occur in a regular pattern like they do in the square matrices. This “irregularity” is actually a blessing. We can get away with simple tiling. A 16x16 block size typically yields enough performance to pass the miss-count threshold.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
int BLOCK_SIZE = 16; int i,j,k,l,tmp; int a,b; for(i = 0; i<N; i+=BLOCK_SIZE){ for(j = 0; j<M; j+=BLOCK_SIZE){ a = i+BLOCK_SIZE; b = j+BLOCK_SIZE; for(k = i; k<N && k<a; k++) { for(l = j; l<M && l<b; l++){ tmp = A[k][l]; B[l][k] = tmp; } } } }
64x64 Case
This is the hardest part. In a 64x64 matrix, a row needs 8 sets, but conflict misses occur every 32/8=4 rows. If we use 8x8 tiling, the bottom half of the block will evict the top half.
We can try a 4x4 matrix tiling first.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
int BLOCK_SIZE = 4; int i,j,k,l,tmp; int a,b; for(i = 0; i<N; i+=BLOCK_SIZE){ for(j = 0; j<M; j+=BLOCK_SIZE){ a = i+BLOCK_SIZE; b = j+BLOCK_SIZE; for(k = i; k<N && k<a; k++) { for(l = j; l<M && l<b; l++){ tmp = A[k][l]; B[l][k] = tmp; } } } }
But this isn’t enough to pass the miss-count threshold.
We try a 8x8 matrix tiling. We solve this by partitioning the 8×8 block into four 4×4 sub-blocks and using the upper-right corner of B as a “buffer” to store data temporarily.
int i, j, k; int tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7, tmp8;
// Iterate through the matrix in 8x8 blocks to improve spatial locality for (i = 0; i < N; i += 8) { for (j = 0; j < M; j += 8) { /** * STEP 1: Handle the top half of the 8x8 block (rows i to i+3) */ for (k = 0; k < 4; k++) { // Read 8 elements from row i+k of matrix A into registers tmp1 = A[i + k][j]; tmp2 = A[i + k][j + 1]; tmp3 = A[i + k][j + 2]; tmp4 = A[i + k][j + 3]; // Top-left 4x4 tmp5 = A[i + k][j + 4]; tmp6 = A[i + k][j + 5]; tmp7 = A[i + k][j + 6]; tmp8 = A[i + k][j + 7]; // Top-right 4x4
// Transpose top-left 4x4 from A directly into top-left of B B[j][i + k] = tmp1; B[j + 1][i + k] = tmp2; B[j + 2][i + k] = tmp3; B[j + 3][i + k] = tmp4;
// Temporarily store top-right 4x4 of A in the top-right of B // This avoids cache misses by using the already-loaded cache line in B B[j][i + k + 4] = tmp5; B[j + 1][i + k + 4] = tmp6; B[j + 2][i + k + 4] = tmp7; B[j + 3][i + k + 4] = tmp8; }
/** * STEP 2: Handle the bottom half and fix the temporary placement */ for (k = 0; k < 4; k++) { // Read bottom-left 4x4 column-wise from A tmp1 = A[i + 4][j + k]; tmp2 = A[i + 5][j + k]; tmp3 = A[i + 6][j + k]; tmp4 = A[i + 7][j + k]; // Read bottom-right 4x4 column-wise from A tmp5 = A[i + 4][j + k + 4]; tmp6 = A[i + 5][j + k + 4]; tmp7 = A[i + 6][j + k + 4]; tmp8 = A[i + 7][j + k + 4];
// Retrieve the top-right elements we temporarily stored in B in Step 1 int t1 = B[j + k][i + 4]; int t2 = B[j + k][i + 5]; int t3 = B[j + k][i + 6]; int t4 = B[j + k][i + 7];
// Move bottom-left of A into the top-right of B B[j + k][i + 4] = tmp1; B[j + k][i + 5] = tmp2; B[j + k][i + 6] = tmp3; B[j + k][i + 7] = tmp4;
// Move the retrieved temporary values into the bottom-left of B B[j + k + 4][i] = t1; B[j + k + 4][i + 1] = t2; B[j + k + 4][i + 2] = t3; B[j + k + 4][i + 3] = t4;
// Place bottom-right of A into the bottom-right of B B[j + k + 4][i + 4] = tmp5; B[j + k + 4][i + 5] = tmp6; B[j + k + 4][i + 6] = tmp7; B[j + k + 4][i + 7] = tmp8; } } }
Note: The key trick here is traversing B by columns where possible (so B stays right in the cache) and utilizing local registers (temporary variables) to bridge the gap between conflicting cache lines.
Conclusion
Optimizing matrix transposition is less about the math and more about mechanical sympathy—understanding the underlying hardware to write code that plays nice with the CPU’s cache.
The jump from the naive version to these optimized versions isn’t just a marginal gain; it’s often a 10x reduction in cache misses. It serves as a stark reminder that in systems programming, how you access your data is just as important as the algorithm itself.
A cache can be described with the following four parameters:
S=2s (Cache Sets): The cache is divided into sets.
E (Cache Lines per set): This is the “associativity.”
If E=1, it’s a direct-mapped cache. If E>1, it’s set-associative.
Each line contains a valid bit, a tag, and the actual data block.
B=2b (Block Size): The number of bytes stored in each line.
The b bits at the end of an address tell the cache the offset within that block.
m: The bits of the machine memory address.
2. Address Decomposition
When the CPU wants to access a 64-bit address, the cache doesn’t look at the whole number at once. It slices the address into three distinct fields:
Field
Purpose
Tag
Used to uniquely identify the memory block within a specific set. t = m - b - s
Set Index
Determines which set the address maps to.
Block Offset
Identifies the specific byte within the cache line.
3. The “Search and Match” Process
When our simulator receives an address (e.g., from an L or S operation in the trace file), it follows these steps:
Find the Set: Use the set index bits to jump to the correct set in our cache structure.
Search the Lines: Look through all the lines in that set.
Hit: If a line has valid == trueAND the tag matches the address tag.
Miss: If no line matches.
Handle the Miss:
Cold Start: If there is an empty line (valid == false), fill it with the new tag and set valid = true.
Eviction: If all lines are full, we must kick one out. This is where the LRU (Least Recently Used) policy comes in: we find the line that hasn’t been touched for the longest time and replace it.
Lab Requirements
For this Lab Project, we will write a cache simulator that takes a valgrind memory trace as an input.
Input
The input looks like:
1 2 3 4
I0400d7d4,8 M0421c7f0,4 L04f6b868,8 S7ff0005c8,8
Each line denotes one or two memory accesses. The format of each line is
1
[space]operation address,size
The operation field denotes the type of memory access:
“I” denotes an instruction load, “L” a data load,
“S” a data store
“M” a data modify (i.e., a data load followed by a data store).
Mind you: There is never a space before each “I”. There is always a space before each “M”, “L”, and “S”.
The address field specifies a 64-bit hexadecimal memory address. The size field specifies the number of bytes accessed by the operation.
CLI
Our program should take the following command line arguments:
getopt comes in unistd.h, but the compiler option is set to -std=c99, which hides all POSIX extensions. GNU systems provide a standalone <getopt.h> header. So we include getopt.h instead.
1
opt = getopt(argc, argv, "hvs:E:b:t:")
h and v: These are boolean flags.
s:, E:, b:, and t:: These are required arguments. The colon tells getopt that these flags must be followed by a value (e.g., -s 4).
After parsing the arguments, we set the initial value of our Cache Data Model.
fscanf does not skip spaces before %c, so we add a space before %c in the format string.
!feof(traceFile) does not work correctly here.It only returns true after a read operation has already attempted to go past the end of the file and failed. Using it as a loop condition (e.g., while (!feof(p))) causes an “off-by-one” error, where the loop executes one extra time with garbage data from the last successful read.
voidloadData(longlong address, int size) { // Simulate accessing data at the given address int s = getSetIndex(address); longlong t = getTag(address); global_timer++;
for (int i = 0; i < associativity; i++) { if (cache[s][i].valid && cache[s][i].tag == t) { hit_count++; cache[s][i].lru_counter = global_timer; if (verboseMode) printf(" hit"); return; } }
miss_count++; if (verboseMode) printf(" miss");
for (int i = 0; i < associativity; i++) { if (!cache[s][i].valid) { cache[s][i].valid = true; cache[s][i].tag = t; cache[s][i].lru_counter = global_timer; return; } }
eviction_count++; if (verboseMode) printf(" eviction");
int victim_index = 0; int min_lru = cache[s][0].lru_counter;
for (int i = 1; i < associativity; i++) { if (cache[s][i].lru_counter < min_lru) { min_lru = cache[s][i].lru_counter; victim_index = i; } }
We first check if the data already exists in the cache.
If it doesn’t exist, we have to scan for blank lines to load the data.
If blank lines don’t exist, we need to evict a line using the LRU strategy. We replace the victim line with the new line.
Other Operations
1 2 3 4 5 6 7 8 9 10 11
voidstoreData(longlong address, int size) { // Simulate storing data at the given address loadData(address, size); }
voidmodifyData(longlong address, int size) { // Simulate modifying data at the given address loadData(address, size); hit_count++; if (verboseMode) printf(" hit\n"); }
For this simulator, storing data and modifying data are basically the same thing as loading data.
Print Summary
We are asked to output the answer using the printSummary function.
In this project, we moved from the theory of hierarchy to the practical reality of memory management. By building this simulator, we reinforced several core concepts of computer systems.
With our simulator passing all the trace tests, we’ve effectively mirrored how a CPU “thinks” about memory. The next step is applying these insights to optimize actual code, ensuring our algorithms play nicely with the hardware we’ve just simulated.
// edx = 14, esi = 0, edi = a intfunc4(int edi, int esi, int edx){ int mid = l + ((r-l)>>1); if(mid <= a){ if(mid==a){ return0; } l = mid + 1; return2*func4(a, l, r) + 1; }else{ r = mid - 1; return2*func4(a, l, r); } }
/* Hmm... Six phases must be more secure than one phase! */ input = read_line(); /* Get input */ phase_1(input); /* Run the phase */ phase_defused(); /* Drat! They figured it out! * Let me know how they did it. */ printf("Phase 1 defused. How about the next one?\n");
/* The second phase is harder. No one will ever figure out * how to defuse this... */ input = read_line(); phase_2(input); phase_defused(); printf("That's number 2. Keep going!\n");
/* I guess this is too easy so far. Some more complex code will * confuse people. */ input = read_line(); phase_3(input); phase_defused(); printf("Halfway there!\n");
/* Oh yeah? Well, how good is your math? Try on this saucy problem! */ input = read_line(); phase_4(input); phase_defused(); printf("So you got that one. Try this one.\n");
/* Round and 'round in memory we go, where we stop, the bomb blows! */ input = read_line(); phase_5(input); phase_defused(); printf("Good work! On to the next...\n");
/* This phase will never be used, since no one will get past the * earlier ones. But just in case, make this one extra hard. */ input = read_line(); phase_6(input); phase_defused();
undefined behavior - There are no restrictions on the behavior of the program.
有符號整數溢位是一種常見的未定義行為。
Because correct C++ programs are free of undefined behavior, compilers may produce unexpected results when a program that actually has UB is compiled with optimization enabled.
也就是說,編譯器最佳化會對未定義行為產生意料之外的結果
cppreference 給出了一個整數溢位的例子:
1 2 3 4 5
intfoo(int x) { return x + 1 > x; // either true or UB due to signed overflow }
編譯之後卻變成了
1 2 3
foo(int): mov eax, 1 ret
意思是,不管怎麼樣都輸出 1
觀察出錯程式碼
我們透過 gcc -S 輸出編譯後的彙編程式碼
1 2 3 4 5 6 7
_Z6isTmaxi: .LFB2: .cfi_startproc endbr64 movl$0, %eax ret .cfi_endproc
/* * conditional - same as x ? y : z * Example: conditional(2,4,5) = 4 * Legal ops: ! ~ & ^ | + << >> * Max ops: 16 * Rating: 3 */ intconditional(int x, int y, int z){ int f = ~(!x) + 1; int of = ~f; return ((f ^ y) & of) | ((of ^ z) & f); }
这里我用 ~(!x) + 1 构造了 x 的类布尔表示,如果 x 为真,表达式结果为 0,反之表达式结果为 ~0。
isLessOrEqual
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/* * isLessOrEqual - if x <= y then return 1, else return 0 * Example: isLessOrEqual(4,5) = 1. * Legal ops: ! ~ & ^ | + << >> * Max ops: 24 * Rating: 3 */ intisLessOrEqual(int x, int y){ /* (y >=0 && x <0) || ((x * y >= 0) && (y + (-x) >= 0)) */ int signX = (x >> 31) & 1; int signY = (y >> 31) & 1; int signXSubY = ((y + ~x + 1) >> 31) & 1; return (signX & ~signY) | (!(signX ^ signY) & !signXSubY); }
核心是判断 y + (-x) >= 0。一开始我做题时被 0x80000000 边界条件烦到了,所以将其考虑进了判断条件。
具体做法是判断 Y 等于 TMIN 时返回 0,X 等于 TMIN 时返回 1。此外也考虑了若 x 为负 y 为 正返回 1,x 为正 y 为负返回 0。
这样想得太复杂了,使用的操作有点多,而题目对 ops 限制是 24,担心过不了 dlc 的语法检查。 所以又花更多时间想出更简单的方法。用逻辑操作可以写作 (y >=0 && x <0) || ((x * y >= 0) && (y + (-x) >= 0))。不过我后来在 linux 上运行了一下第一种方法,dlc 并没有报错。
logicalNeg
1 2 3 4 5 6 7 8 9 10 11 12 13
/* * logicalNeg - implement the ! operator, using all of * the legal operators except ! * Examples: logicalNeg(3) = 0, logicalNeg(0) = 1 * Legal ops: ~ & ^ | + << >> * Max ops: 12 * Rating: 4 */ intlogicalNeg(int x){ int sign = (x >> 31) & 1; int TMAX = ~(1 << 31); return (sign ^ 1) & ((((x + TMAX) >> 31) & 1) ^ 1); }
/* howManyBits - return the minimum number of bits required to represent x in * two's complement * Examples: howManyBits(12) = 5 * howManyBits(298) = 10 * howManyBits(-5) = 4 * howManyBits(0) = 1 * howManyBits(-1) = 1 * howManyBits(0x80000000) = 32 * Legal ops: ! ~ & ^ | + << >> * Max ops: 90 * Rating: 4 */ inthowManyBits(int x){ int sign = (x >> 31) & 1; int f = ~(!sign) + 1; int of = ~f; /* * NOTing x to remove the effect of the sign bit. * x = x < 0 ? ~x : x */ x = ((f ^ ~x) & of) | ((of ^ x) & f); /* * We need to get the index of the highest bit 1. * Easy to find that if it's even-numbered, `n` will lose the length of 1. * But the odd-numvered won't. * So let's left shift 1 (for the first 1) to fix this. */ x |= (x << 1); int n = 0; // Get index with bisection. n += (!!(x & (~0 << (n + 16)))) << 4; n += (!!(x & (~0 << (n + 8)))) << 3; n += (!!(x & (~0 << (n + 4)))) << 2; n += (!!(x & (~0 << (n + 2)))) << 1; n += !!(x & (~0 << (n + 1))); // Add one more for the sign bit. return n + 1; }
这里我利用了之前 conditional 的做法,讲 x 为负的情况排除掉,统一处理正整数。统计位数可以采取二分法查找最高位的 1,但做了几轮测试就会发现二分法存在漏位的问题。
/* * floatScale2 - Return bit-level equivalent of expression 2*f for * floating point argument f. * Both the argument and result are passed as unsigned int's, but * they are to be interpreted as the bit-level representation of * single-precision floating point values. * When argument is NaN, return argument * Legal ops: Any integer/unsigned operations incl. ||, &&. also if, while * Max ops: 30 * Rating: 4 */ unsignedfloatScale2(unsigned uf){ intexp = (uf >> 23) & 0xFF; // Special if (exp == 0xFF) return uf; // Denormalized if (exp == 0) return ((uf & 0x007fffff) << 1) | (uf & (1 << 31)); // Normalized return uf + (1 << 23); }
/* * floatFloat2Int - Return bit-level equivalent of expression (int) f * for floating point argument f. * Argument is passed as unsigned int, but * it is to be interpreted as the bit-level representation of a * single-precision floating point value. * Anything out of range (including NaN and infinity) should return * 0x80000000u. * Legal ops: Any integer/unsigned operations incl. ||, &&. also if, while * Max ops: 30 * Rating: 4 */ intfloatFloat2Int(unsigned uf){ int TMIN = 1 << 31; intexp = ((uf >> 23) & 0xFF) - 127; // Out of range if (exp > 31) return TMIN; if (exp < 0) return0; int frac = (uf & 0x007fffff) | 0x00800000; // Left shift or right shift int f = (exp > 23) ? (frac << (exp - 23)) : (frac >> (23 - exp)); // Sign return (uf & TMIN) ? -f : f; }
/* * floatPower2 - Return bit-level equivalent of the expression 2.0^x * (2.0 raised to the power x) for any 32-bit integer x. * * The unsigned value that is returned should have the identical bit * representation as the single-precision floating-point number 2.0^x. * If the result is too small to be represented as a denorm, return * 0. If too large, return +INF. * * Legal ops: Any integer/unsigned operations incl. ||, &&. Also if, while * Max ops: 30 * Rating: 4 */ unsignedfloatPower2(int x){ intexp = x + 127; // 0 if (exp <= 0) return0; // INF if (exp >= 0xFF) return0x7f800000; returnexp << 23; }