荣耀手机屏蔽内置 DNS
最近备用的荣耀手机升级了 MagicOS 10,发现连接 Wi-Fi 后,海外应用(如 X、Reddit、In […]
如果大家对目前中国大陆境内的网络环境足够了解,应该就会知道 dl.google.com 在很多情况下是可以直连访问的。比如,你可以通过 google.cn/chrome/?standalone=1 这个 URL 直接在境内的网络环境下下载 Chrome 的离线安装包,最终的下载域名就是 dl.google.com。
我平常的使用习惯是 24 小时开启代理工具的 TUN,让所有流量先经过一张虚拟网卡,再根据分流规则自动判断要不要走代理。这个习惯大部分时候都挺省心的——直到最近我用 yay 滚 Arch 的时候,突然遇到了 dl.google.com 的 SSL 连接建立失败。

而且不止是 yay,我的浏览器也返回了相同的结果:

当时我的第一反应是:是不是我那套分流规则又抽风了?(毕竟不是我自己写的,出事先甩锅很合理。)
我特意去查了分流规则,针对 SNI 为 dl.google.com 的流量是直连访问的。

这就很奇怪了。按理说:
dl.google.com 本身在国内网络环境里经常是能直连的说实话,这个问题我之前也遇到过,但那时手上有优先级更高的事,就直接关掉代理工具绕过了它完成更新。好在我现在刚处理完手头事情,正处于无事可做的状态,于是决定认真把这个坑填了。
我先把代理工具的 fake-ip 关掉,换成真实 IP 解析(避免再引入额外变量),然后用 curl -vv 去访问 dl.google.com 的下载链接,看看它到底要连到哪里去。

现在回头看我能很笃定地说:这里解析出来的这个 IP 来自 Google 的海外 CDN,而不是国内机房/国内可达的那一类。

如果大家不清楚的话:dl.google.com 针对国内访客的 DNS 解析结果,很多时候会返回国内可达的 IP(否则你也没法在境内直连下载)。而这里返回的这个海外 IP 在我这条网络上是不可达的;再加上我在喵喵工具里给 dl.google.com 配的是直连,于是就变成了:
DNS 给了一个「海外 IP」
- 规则要求 DIRECT = 直连到一个我连不上的地方 = TLS 握手失败
所以这并不是「直连规则没生效」,而更像是:规则生效得非常彻底,但 DNS 把我带沟里了。
Mihomo 内核目前的 DNS 配置项主要是下面四个:
nameserver: 默认解析服务器(大部分域名都走这里)direct-nameserver: 直连域名的解析服务器(较新版本才有)proxy-server-nameserver: 节点域名解析(跟这次没啥关系)default-nameserver: 用来解析 DNS 配置里「域名形式」的 nameserver(也先不展开)dl.google.com 被规则指定为直连域名,所以 Mihomo 理论上应该优先参考 direct-nameserver;如果没设置,就回落到 nameserver。
而我当时的 nameserver 配置是:
https://dns.alidns.com/dns-query我当时的直觉很简单:既然解析结果像是从海外 CDN 池里出来的,那就先验证一下是不是这条阿里 DNS(DoH)返回的就是海外 IP。
阿里 DoH 提供了一个 JSON 查询接口,所以我直接用 curl 去请求:
curl -s 'https://dns.alidns.com/resolve?name=dl.google.com&type=A'

返回的 IP 就是我之前遇到的那个海外 IP。到这一步我基本可以确认:至少在我当前这条网络出口下,阿里 DNS 对 dl.google.com 的解析结果就是“那一类”我访问不到的 IP。
写到这里必须强调一下:这事并不是「阿里 DNS 永远解析错」这么简单,我后来做了一圈对照,发现它其实很“苛刻”:
**只有在「移动宽带」+「阿里 DNS(包括 223.5.5.5 或 alidns 的 DoH)」这两个条件同时成立时,问题才可能稳定复现。**两个条件缺一不可。
更具体一点就是:
dl.google.com 的解析结果通常就正常我也用 itdog 做了下全国解析测试,移动网络下的复现比例确实更高。

为什么会这样?老实说我没有能力给一个“全网唯一真相”的解释,我只能说现象非常一致,而且足够让我下结论:问题不是 TUN 本身,而是 TUN 下我的 DNS 选择把 dl.google.com 导向了一个在移动网络里不可达的地址池。
既然问题出在「移动宽带 + 阿里 DNS」这个组合上,那解决方式也就很朴素了:别让 dl.google.com 继续走阿里 DNS 解析。
可以配置 direct-nameserver 或者 nameserver-policy,可以配置 119.29.29.29 等其他公共 DNS,或者干脆把 DNS 解析交给家里的路由器。
direct-nameserver:
- 192.168.8.1
nameserver-policy:
"dl.google.com": [119.29.29.29]
这么搞完之后,yay 更新恢复正常,浏览器也能直连访问 dl.google.com。
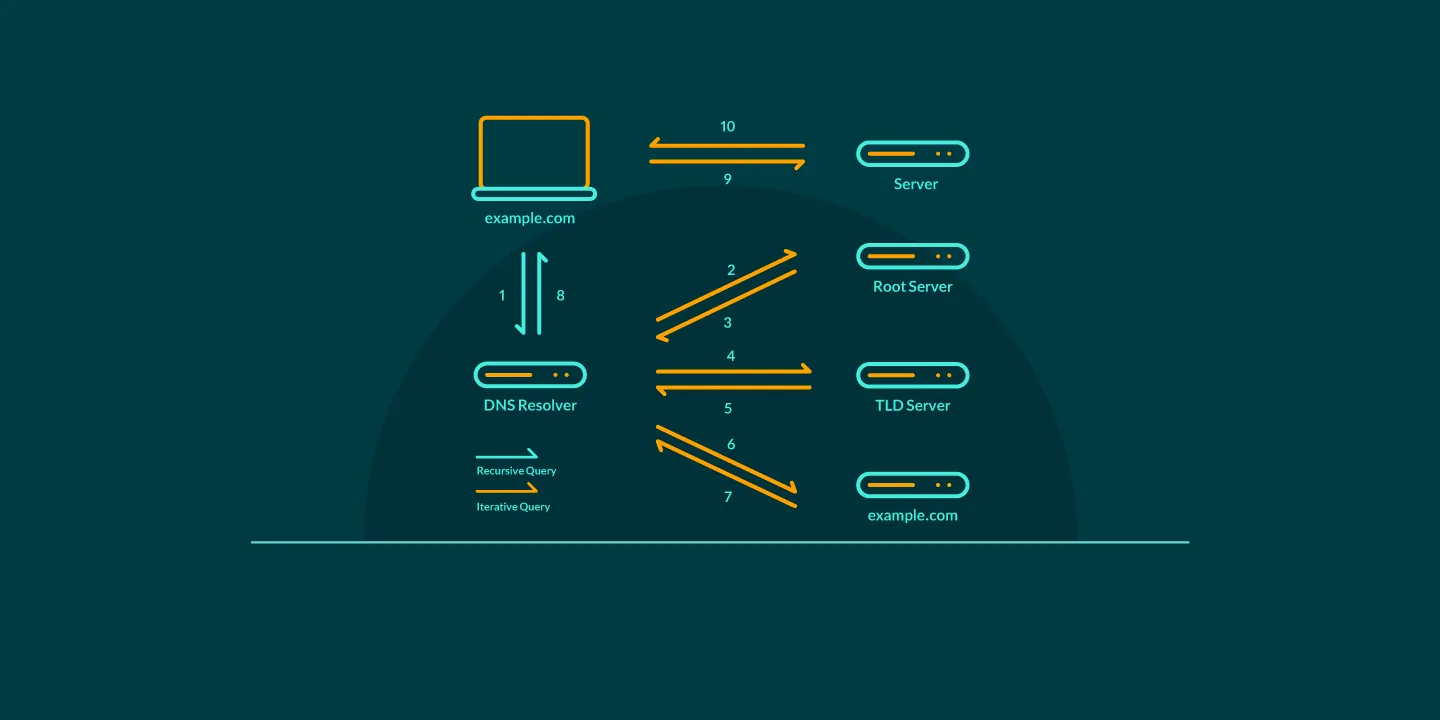
在上一篇博客中,我提到过一个核心观点——对于流量少、访客的地理位置不集中的小型站点,DNS 冷启动不是偶发的“意外”,而是一种被动的“常态”。
对于大多数站长而言,自己的站点流量不是一时半刻就能提上去的,因此我们的访客大概率都要走完一遍完整的 DNS 解析过程。上一篇博客中我提到过更改为距离访客物理位置更近的权威 DNS 服务器来提升速度,但 TLD(域名后缀)的 Nameservers 是我们无法改变的,也就是下图中红色背景的那一段解析过程。
sequenceDiagram
autonumber
participant User as 用户/浏览器
participant Local as 本地DNS<br>递归解析器
participant Root as 根域名服务器
participant TLD as 顶级域服务器<br>(TLD Server)
participant Auth as 权威DNS服务器
Note over User,Auth: DNS 递归查询完整流程
User->>Local: 查询域名 www.example.com
Note over Local: 检查缓存 (MISS)
Local->>Root: 查询 .com 的 TLD 服务器
Root-->>Local: 返回 .com TLD 服务器地址
%% --- 重点高亮区域开始 ---
rect rgb(255, 235, 235)
Note right of Local: ⚠️ 本文核心讨论区域 <br> (TLD 解析时延)
Local->>TLD: 查询 example.com 的权威服务器
Note left of TLD: 这里的物理距离与 Anycast 能力<br>决定了是否存在数百毫秒的延迟
TLD-->>Local: 返回 example.com 的权威服务器地址
end
%% --- 重点高亮区域结束 ---
Local->>Auth: 查询 www.example.com 的 A 记录
Auth-->>Local: 返回 IP 地址 (e.g., 1.1.1.1)
Note over Local: 缓存结果 (TTL)
Local-->>User: 返回最终 IP 地址
User->>Auth: 建立 TCP 连接 / HTTP 请求
所以,如果你还没有购买域名,但想要像个 geeker 一样追求极致的首屏加载(哪怕你并没有多少访客),你该选择哪个 TLD 呢?
一个简单的方法是,直接去 ping TLD 的 nameserver,看看访客所请求的公共 DNS 服务器在这一段解析中所花费的时常。
以我的域名 zhul.in 为例,在 Linux 下,可以通过 dig 命令拿到 in 这个 TLD 的 Nameserver
dig NS in.

随后可以挑选任何一个 Nameserver(公共 DNS 服务器其实有一套基于历史性能的选择策略),直接去 ping 这个域名

我这里的网络环境是杭州移动,如果我在我的局域网开一台 DNS 递归服务器,这个结果就是在上面那张时序图中红色部分所需要时长的最小值(DNS 服务器还需要额外的时长去处理请求)。
借助一些网站提供的多个地点 ping 延迟测试,我们可以推测这个 TLD 在全球哪些国家或地区部署了 Anycast(泛播)节点,下图为 iplark.com 提供的结果。

可以推测,in 的 TLD Nameserver 起码在日本、香港、美国、加拿大、欧洲、澳大利亚、巴西、印度、南非等多地部署了 Anycast 节点,而在中国大陆境内的延迟较高。
作为对比,我们可以通过同样的方法再看看 cn 域名的 TLD Nameserver 的 Anycast 节点。

经过 itdog.cn 的测试,推测 cn 域名的 TLD Nameserver 可能仅在北京有节点。
上面的测试方法只是一个简易的判断方法,在现实中会有很多的外部因素影响 DNS 冷启动的解析时长:
所以,我们需要有一个基于真实的 DNS 解析请求的测试方案
对于 DNS 冷启动相关的测试一直以来存在一个困境——公共 DNS 服务器不归我们管,我们无法登陆上去手动清除它的缓存,因此所有的测试都只有第一次结果才可能有效,后续的请求会直接打到缓存上。但这一次我们测试的是公共 DNS 服务器到 TLD Nameserver 这一段的延迟,在 Gemini 的提醒下,我意识到可以在不同地区测试公共 DNS 对随机的、不存在的域名的解析时长,这能够反应不同 TLD 之间的差异。
所以,测试代码在下面,你可以使用常见的 Linux 使用 bash 执行这段代码,需要确保装有 dig 和 shasum 命令,并且推荐使用 screen / tmux 等工具挂在后台,因为整个测试过程可能会持续十几分钟。如果你所采用的网络环境在中国大陆境内,我建议你把代码中的公共 DNS 服务器换成 223.5.5.5 / 119.29.29.29 ,应该会更符合境内访客的使用环境。
#!/bin/bash
# ================= 配置区域 =================
# CSV 文件名
OUTPUT_FILE="dns_benchmark_results.csv"
# DNS 服务器
DNS_SERVER="8.8.8.8"
# 待测试的 TLD 列表
# 包含:全球通用(com), 国别(cn, de), 热门技术(io, xyz), 以及可能较慢的后缀
TLDS_TO_TEST=("com" "net" "org" "cn" "in" "de" "cc" "site" "ai" "io" "xyz" "top")
# 每个 TLD 测试次数
SAMPLES=1000
# 每次查询间隔 (秒),防止被 DNS 服务器判定为攻击
# 1000次 * 0.1s = 100秒/TLD,总耗时约 15-20 分钟
SLEEP_INTERVAL=0.1
# ===========================================
# 初始化 CSV 文件头
echo "TLD,Domain,QueryTime_ms,Status,Timestamp" > "$OUTPUT_FILE"
echo "============================================="
echo " DNS TLD Latency Benchmark Tool"
echo " Target DNS: $DNS_SERVER"
echo " Samples per TLD: $SAMPLES"
echo " Output File: $OUTPUT_FILE"
echo "============================================="
echo ""
# 定义进度条函数
function show_progress {
# 参数: $1=当前进度, $2=总数, $3=当前TLD, $4=当前平均耗时
let _progress=(${1}*100/${2})
let _done=(${_progress}*4)/10
let _left=40-$_done
# 构建填充字符串
_fill=$(printf "%${_done}s")
_empty=$(printf "%${_left}s")
# \r 让光标回到行首,实现刷新效果
printf "\rProgress [${_fill// /#}${_empty// /-}] ${_progress}%% - Testing .${3} (Avg: ${4}ms) "
}
# 主循环
for tld in "${TLDS_TO_TEST[@]}"; do
# 统计变量初始化
total_time_accum=0
valid_count=0
for (( i=1; i<=${SAMPLES}; i++ )); do
# 1. 生成随机域名 (防止缓存命中)
# 使用 date +%N (纳秒) 确保足够随机,兼容 Linux/macOS
RAND_PART=$(date +%s%N | shasum | head -c 10)
DOMAIN="test-${RAND_PART}.${tld}"
TIMESTAMP=$(date "+%Y-%m-%d %H:%M:%S")
# 2. 执行查询
# +tries=1 +time=2: 尝试1次,超时2秒,避免脚本卡死
result=$(dig @${DNS_SERVER} ${DOMAIN} A +noall +stats +time=2 +tries=1)
# 提取时间 (Query time: 12 msec)
query_time=$(echo "$result" | grep "Query time" | awk '{print $4}')
# 提取状态 (status: NXDOMAIN, NOERROR, etc.)
status=$(echo "$result" | grep "status:" | awk '{print $6}' | tr -d ',')
# 3. 数据清洗与记录
if [[ -n "$query_time" && "$query_time" =~ ^[0-9]+$ ]]; then
# 写入 CSV
echo "${tld},${DOMAIN},${query_time},${status},${TIMESTAMP}" >> "$OUTPUT_FILE"
# 更新统计
total_time_accum=$((total_time_accum + query_time))
valid_count=$((valid_count + 1))
current_avg=$((total_time_accum / valid_count))
else
# 记录失败/超时
echo "${tld},${DOMAIN},-1,TIMEOUT,${TIMESTAMP}" >> "$OUTPUT_FILE"
current_avg="N/A"
fi
# 4. 显示进度条
show_progress $i $SAMPLES $tld $current_avg
sleep $SLEEP_INTERVAL
done
# 每个 TLD 完成后换行
echo ""
echo "✅ Completed .${tld} | Final Avg: ${current_avg} ms"
echo "---------------------------------------------"
done
echo "🎉 All Done! Results saved to $OUTPUT_FILE"
免责声明:以下测试结果仅供参考,不构成任何购买推荐,且仅代表测试当日(2025.11.24)的网络情况,后续不会进行跟进。DNS 冷启动对于大型站点几乎没有影响,仅小站需要关注。本次测试中,所有境内检测点使用 223.5.5.5 作为 DNS 服务器,境外检测点使用 8.8.8.8。
| 测试点/延迟(ms) | .com | .net | .org | .cn | .in | .de | .cc | .site | .ai | .io | .xyz | .top |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 🇨🇳 上海腾讯云 | 438 | 429 | 470 | 30 | 535 | 353 | 476 | 454 | 367 | 485 | 444 | 43 |
| 🇨🇳 北京腾讯云 | 425 | 443 | 469 | 17 | 350 | 420 | 466 | 647 | 582 | 461 | 559 | 9 |
| 🇭🇰 香港 Yxvm | 75 | 75 | 363 | 227 | 6 | 11 | 61 | 6 | 33 | 126 | 5 | 7 |
| 🇨🇳 彰化(台湾) Hinet | 90 | 87 | 128 | 213 | 59 | 38 | 76 | 37 | 73 | 94 | 36 | 47 |
| 🇯🇵 大阪 Vmiss | 20 | 19 | 244 | 309 | 15 | 24 | 17 | 35 | 19 | 65 | 37 | 90 |
| 🇸🇬 新加坡 Wap | 6 | 9 | 139 | 398 | 6 | 10 | 7 | 17 | 7 | 110 | 17 | 66 |
| 🇺🇸 洛杉矶 ColoCrossing | 7 | 7 | 307 | 137 | 4 | 64 | 5 | 62 | 5 | 49 | 47 | 231 |
| 🇩🇪 杜塞尔多夫 WIIT AG | 16 | 17 | 288 | 82 | 75 | 15 | 14 | 24 | 66 | 73 | 24 | 306 |
| 🇦🇺 悉尼 Oracle | 33 | 31 | 12 | 338 | 7 | 13 | 121 | 7 | 10 | 9 | 7 | 191 |
通过上面的数据,我们可以看到 .cn 和 .top 是所有测试的域名后缀中在中国大陆境内解析速度最快的,但选择 .cn 和 .top 意味着你需要牺牲其他地区访客的解析速度。而像 .com、.net、.org 这些通用的域名后缀在全球绝大部分地区表现良好,而在中国大陆境内的解析速度则相对较慢,因为他们没有在大陆境内部署 Anycast 节点。在 DNS 冷启动的场景下(如果你的站点访客少,那几乎每次访问都是冷启动),首屏加载时间会因此增加 500ms 甚至更多。
经 v2ex 的网友 Showfom 提醒,GoDaddy 作为注册局掌握的部分 TLD 的 Nameserver 同样在中国大路境内拥有 Anycast 节点,比如 .one、.tv、.moe 等。另, Amazon Registry Services 旗下的 .you 域名经我测试也有境内的 Anycast 节点。其他域名后缀可自行测试。
你可以点击这里下载完整的测试结果 CSV 文件进行进一步的分析。
最近使用openWRT实现了一套几乎终极效果的内网域名管理+DNS加速+DNS去广告+魔法上网的系统,极致的复杂配置之后,就是最简单的无感使用方式。本文将讲述其构架和实现细节,现在任何人都可以无需任何配置就可以直接域名访问 nas 中部署的内网各种服务,加访问 google openai 等服务。
TIPS: 本文不是写给小白的,而是给懂技术的用户的。可能不会说的很细,但能看懂的自然能看懂,看不懂的,写得再细致看了还是白看。

首先让我们简单了解什么是 DNS,为什么要配置 DNS
DNS 解析器(也称解析器)将域名转换为互联网上的 IP 地址。
每次您的计算机使用域名(例如example.com)连接到网站时,它都需要知道该网站的 IP 地址,即一组唯一的数字。因此,它会联系 DNS 解析器并获取网站的当前 IP 地址。
一般来说,DNS解析器是去中心化DNS系统的一部分。当你向解析器发送请求时,它会联系其他DNS服务器来获取地址。
您计算机使用的 DNS 解析器通常由您的互联网服务提供商 (ISP) 选择。如果您想为您的网络使用其他 DNS 解析器,您可以自行配置网络以启用它。您可以在操作系统的网络设置或家用路由器的管理界面中更改此配置。
开胃小菜的配置

和nginx 配合使用。 简单的可以直接修改/etc/hosts。
DNSCrypt Proxy: 作为DNS前端访问DOH的DNS
DNSMasq: 作为DNS后端,连接到DNSCrypt Proxy,并配置本地域名。还可以添加DNS去广告功能,浏览器插件去广告非常消耗CPU和内存,但是在DNS前端去广告,资源消耗低,并一次性解决所有的访问终端(pc,手机,平板)广告问题。
配置一个去广告,本地域名管理工具。
TIPS: 使用时需要手动设置本机dns指向nas 的 DNS
直接接管路由器下游所有设备的DNS,直接无感访问私有域名!
最推荐的使用方式!用户不需要任何配置,任何软件的安装,真正的无感使用!
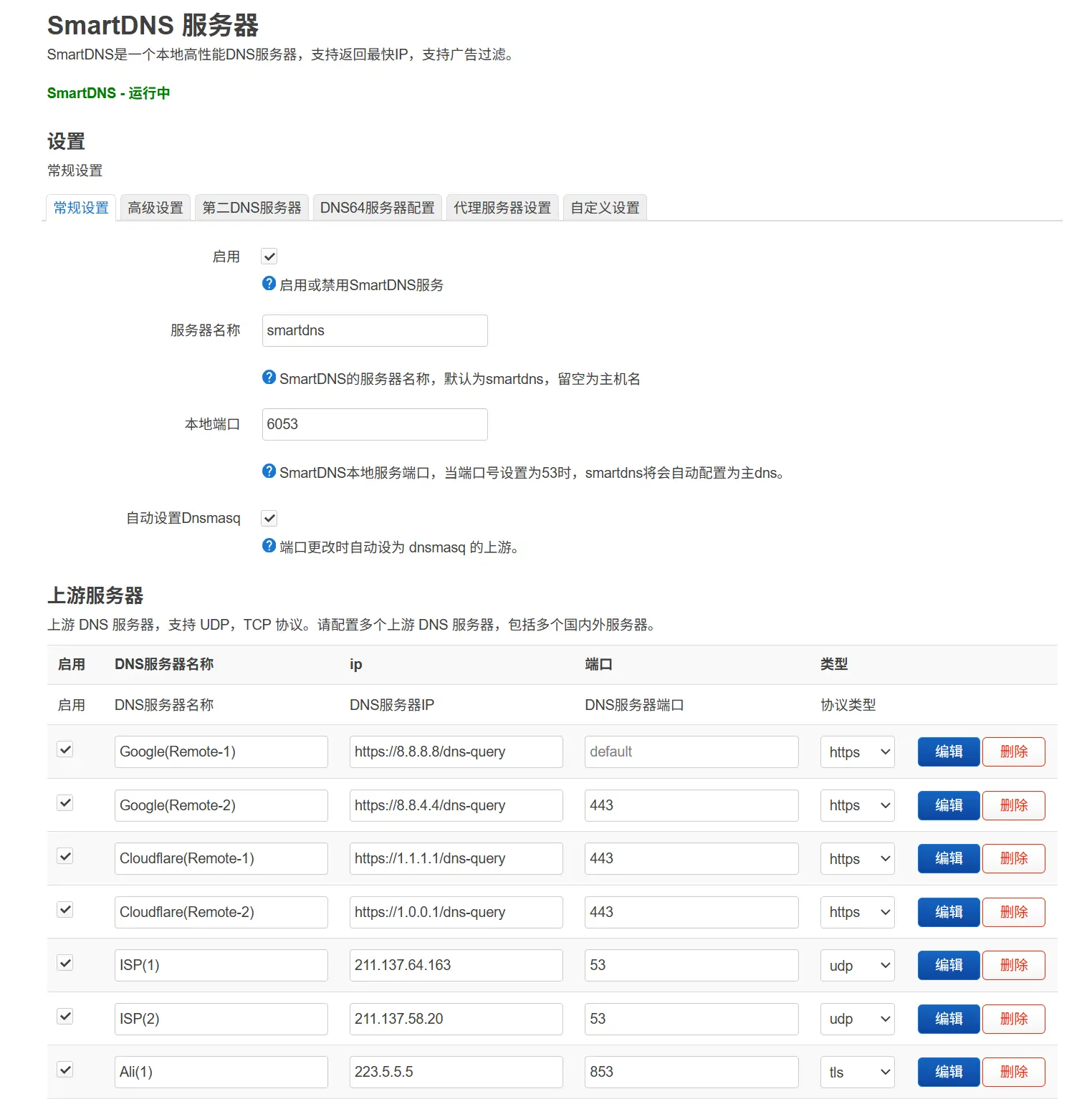
graph LR
subgraph 用户网络访问
User[用户] -->|域名访问| Router[OpenWrt路由器]
end
subgraph OpenWrt路由器
Router --> |DNS请求| DNSMASQ[dnsmasq]
DNSMASQ -->|上游查询| SmartDNS[smartdns<br>加速/去广告]
Router -->|内网访问| NAS(域名管理)
SmartDNS -->|国外域名<br>DOH/DOT<br>流量代理| DNS
SmartDNS -->|国外域名<br>DOH/DOT<br>流量代理| DNS...
SmartDNS --> |国内域名| 国内DNS
SmartDNS --> |国内域名| 国内DNS...
passwall[passwall<br>透明代理] --> xray
OpenWrt_Script -->|更新配置| DNSMASQ
OpenWrt_Script -->|更新配置| SmartDNS
end
subgraph NAS服务器
NAS --> |内网域名| Nginx[Nginx<br>反向代理]
Nginx --> Emby[emby服务]
Nginx --> Iyuu[iyuu服务]
Nginx --> Other[其他服务]
Script[配置生成脚本<br>内网域名:IPv4/Ipv6] --> HTTP[HTTP配置服务]
HTTP -->|提供配置| OpenWrt_Script[OpenWrt更新脚本<br>内网域名]
end
subgraph 外网域名
Router -->|外网域名<br>代理访问| PROXYDOMAIN[被墙域名<br>Google openAI etc]
Router -->|外网域名<br>直接访问| DOMAIN[外网域名]
end
dnsmasq:本地 DNS 服务器,处理客户端 DNS 请求smartdns:智能 DNS 解析服务,作为 dnsmasq 的上游Nginx:反向代理所有服务(emby/iyuu等)sequenceDiagram
participant NAS_Script as NAS 配置脚本
participant HTTP_Server as HTTP 服务
participant OpenWrt_Script as OpenWrt 更新脚本
participant DNSMASQ
participant SmartDNS
loop 定期执行
NAS_Script->>NAS_Script: 获取本机 IPv4/IPv6
NAS_Script->>NAS_Script: 生成配置文件
Note right of NAS_Script: dnsmasq.conf<br>smartdns.conf
NAS_Script->>HTTP_Server: 上传配置文件
end
loop 每小时执行
OpenWrt_Script->>HTTP_Server: 请求最新配置
HTTP_Server-->>OpenWrt_Script: 返回配置文件
OpenWrt_Script->>DNSMASQ: 应用新配置
OpenWrt_Script->>SmartDNS: 应用新配置
OpenWrt_Script->>DNSMASQ: 重启服务
OpenWrt_Script->>SmartDNS: 重启服务
endflowchart TD
Start[开始] --> GetIP{获取IP}
GetIP --> |命令| IPv4[ip -4 addr show]
GetIP --> |命令| IPv6[ip -6 addr show]
IPv4 --> Parse[解析有效IP]
IPv6 --> Parse
Parse --> GenConfig[生成配置文件]
subgraph 配置文件内容
GenConfig --> DnsmasqConf[address=/mydomain.com/NAS_IP]
GenConfig --> SmartDNSConf[domain-rules /mydomain.com/ -c NAS_IP]
end
GenConfig --> Save[保存到HTTP目录]
Save --> End[结束]| 组件 | 功能描述 |
|---|---|
| dnsmasq | 本地DNS缓存,将特定域名直接解析为NAS内网IP,绕过公网解析 |
| smartdns | 智能DNS解析,过滤广告/恶意域名,作为dnsmasq的上游提供纯净DNS结果 |
| Nginx | 反向代理服务,通过不同子路径转发到NAS上的不同服务(emby:8096, iyuu:8787等) |
| 更新脚本 | 双端协同工作保持DNS配置与NAS实际IP同步,解决动态IP变化导致的服务中断问题 |
pie
title DNS解析分层
"dnsmasq本地解析" : 40
"smartdns智能过滤/加速" : 30
"上游DNS服务" : 30服务高可用:
安全隔离:
提示:建议将OpenWrt更新脚本设置为开机启动运行一次 + 每小时(或者时间更短)执行,NAS配置脚本在系统启动和网络变化时触发,实现无缝切换。
这个可以很简单,也可以很复杂。
个人使用了一套集成了几十个DNS分线路解析的配置,配置说明很麻烦,写起来很长。
这部分内容暂略,后期再补充。各位用户可以先简单配置,后期看我这里的更新。
考虑在不触碰某条线的情况下,怎么编写本文。有兴趣的过段时间再查看本文。
当我们谈论网站性能时,我们通常关注前端渲染、资源懒加载、服务器响应时间(TTFB)等。然而,在用户浏览器真正开始请求内容之前,有一个至关重要却鲜少在性能优化方面被提及的部分—— DNS 解析。对于默默无闻的小型站点而言,“DNS Cache Miss”(缓存未命中)或我称之为“DNS 冷启动”,会成为绕不过去的性能瓶颈,也就是本文标题所提到的“西西弗斯之石”。
要理解这块“石头”的重量,我们必须重温 DNS 解析的完整路径。这并非一次简单的查找,而是一场跨越全球的接力赛:
.com)的顶级域名服务器。sequenceDiagram
participant User as 用户/浏览器
participant Local as 本地DNS<br>递归解析器
participant Root as 根域名服务器
participant TLD as 顶级域服务器<br>(.com, .org等)
participant Auth as 权威DNS服务器
Note over User,Auth: DNS递归查询完整流程
User->>Local: 1. 查询域名<br>www.example.com
Note over Local: 检查缓存<br>未找到记录
Local->>Root: 2. 查询 .com 的TLD服务器
Root-->>Local: 3. 返回 .com TLD服务器地址
Local->>TLD: 4. 查询 example.com 的权威服务器
TLD-->>Local: 5. 返回 example.com 的权威服务器地址
Local->>Auth: 6. 查询 www.example.com 的A记录
Auth-->>Local: 7. 返回 IP地址 (e.g., 1.1.1.1)
Note over Local: 缓存结果<br>(根据TTL设置)
Local-->>User: 8. 返回最终IP地址
Note over User,Auth: 后续流程
User->>Auth: 9. 使用IP地址建立TCP连接<br>开始HTTP请求
对于首次或长时间未访问的请求,这个过程意味着至少 4 次网络往返(RTT),而在涉及到 CNAME 等情况时则会更多。对于那些拥有完美缓存的大型网站来说,这块石头可能已被别人推到了山顶;但对小型站点,它总是在山脚等待它的西西弗斯。
“既然 DNS 冷启动的代价如此之高,那我能否使用脚本定时访问自己的网站,提前让公共 DNS 缓存预热起来呢?”——这是我曾经设想的解题思路。
然而,这一思路在现代互联网的 Anycast(泛播)架构下,往往徒劳无功。
Anycast 的核心理念是:同一个 IP 地址在全球多个节点同时存在,用户请求会被路由到“距离最近”或“网络路径最优”的节点。
这意味着,Google DNS (8.8.8.8) 、Cloudflare DNS (1.1.1.1)、阿里 DNS (223.5.5.5)、腾讯 DNS (119.29.29.29) 等公共 DNS 服务器背后并不是一台中心化的服务器,而是一组分布在世界各地、动态路由的节点集群。
于是问题出现了:
从站长的视角来看,DNS 缓存不再是一个可预测的实体,而是分裂成一片片地理隔离、随时可变的“镜像迷宫”。
每个访客都在不同的山脚下推着自己的那块石头,仿佛世界上有成千上万个西西弗斯,孤独地在各自的路径上前行。
这也解释了为什么即便一个小型网站有规律地被脚本访问,仍可能在真实访客那里出现明显的 DNS 延迟。因为「预热」只是局部生效 —— 它温暖的是某一个任播节点的缓存,而不是整个网络的全貌。而当 TTL 到期或缓存被公共 DNS 服务器采用 LRU 等算法清理时,这份温度也会悄然散去。
从宏观上看,这让“小流量站点”陷入了某种宿命循环:
冷启动不再是偶发的“意外”,而是一种被动的“常态”。
西西弗斯的困境看似无解,但我们并非完全无能为力。虽然无法彻底消除 DNS 冷启动,但通过一系列策略,我们可以显著减轻这块石头的重量,缩短它每次滚落后被推上山顶的时间。
TTL(生存时间)是 DNS 记录中的一个关键值,它告知递归解析器(如公共 DNS、本地缓存)可以将一条解析记录缓存多久,尽管他们可能会被 LRU 算法淘汰。
拉长 TTL 可以有效提高缓存的命中率,减少 DNS 冷启动的情况,尽可能让西西弗斯之石保留在山顶上。
但拉长 TTL 是以牺牲灵活性作为代价的:如果你因为某些原因需要更换域名做对应的 IP 地址,过长的 TTL 可能会导致访客在很长一段时间内取得的都是已经失效的 IP 地址。
DNS 解析的最后一公里——从公共 DNS 服务器到你的权威 DNS 服务器——的耗时同样至关重要。如果你的域名所采用的 Nameserver 服务响应缓慢、全球节点稀少、又或者距离访客所请求的公共 DNS 服务器距离太远,那么即使用户的公共 DNS 节点就在身边,整个解析链条依然会被这最后一环拖慢。
如果我正在写的是一篇英文博客,那么我只需要说把 Nameserver 换成 Cloudflare、Google 等一线大厂就完事了。这些大厂提供免费的权威 DNS 托管业务,且在全球各地拥有大量节点,在这方面是非常专业且值得信赖的。
但我现在正在使用简体中文,根据我的博客统计数据,我的读者大多来自中国大陆,他们的站点访客大多也来自中国大陆,他们请求的公共 DNS 服务器大概率也都部署在中国大陆,而 Cloudflare/Google Cloud DNS 完全没有权威 DNS 服务器的中国大陆节点,这会拖慢速度。所以如果你的访客主要来自中国大陆境内,或许可以试试阿里云或者 Dnspod,他们主要的权威 DNS 服务器节点都在中国大陆境内,这在理论上可以减少公共 DNS 服务器与 权威 DNS 服务器之间的通信时长。
DNS 冷启动的问题,从未有完美的解决方案。它像是互联网架构中注定存在的一段“延迟的诗意”——每个访问者都从自己的网络拓扑出发,沿着看不见的路径,一步步推着那块属于自己的石头,直到抵达你的服务器山顶,换得屏幕上第一个像素的亮起。
对小型站点而言,这或许是命运的重量;但理解它、优化它、监测它,便是我们在这条漫长上坡路上,为石头磨出更光滑的棱角。
在 Homelab 中折腾了一段时间后,我发现自己陷入了一个困境:随着设备数量的增加,管理 IP 地址变得越来越痛苦。
典型的场景是这样的:
– SSH 到某台服务器:ssh user@192.168.1.101,等等,101 是哪台机器来着?
– 访问某个服务:`http://192.168.2.88:8080`,这个 88 又是什么?
– 更糟糕的是,DHCP 租约过期后 IP 变了,所有的配置都要改一遍
我尝试过给每台设备绑定静态 IP,但这种方案有几个问题:
后来我发现了 mDNS(多播域名系统),它完美地解决了这些问题。配置完成后,我可以直接使用 server3.local、pfsense.local 这样的域名来访问设备,再也不用记 IP 地址了。
这篇文章记录了我在 OpenWrt + pfSense 双层路由环境下配置 mDNS 的完整过程,包括踩过的坑和解决方案。
我的网络是两层路由结构:
– 一级路由:OpenWrt,家庭主路由器,网段 192.168.1.0/24
– 二级路由:pfSense,虚拟机网络路由器,网段 192.168.2.0/24
这样设置的目的是将虚拟机网络与主网络解耦,让 VM 可以独立运行并组成一个独立的集群。但这也带来了跨网段访问的问题,mDNS 的 reflector 功能正好可以解决这个问题。
我的一级路由用的是 OpenWrt,二级路由用的是 pfSense。虽然系统不同,但配置思路是类似的。
核心组件是 Avahi,一个开源的 mDNS/DNS-SD 实现。OpenWrt 和 pfSense 都可以直接安装。
安装 Avahi
opkg update
opkg install avahi-daemon-service-ssh avahi-daemon-service-http
修改配置文件
编辑 /etc/avahi/avahi-daemon.conf:
[server]
use-ipv4=yes
use-ipv6=yes
check-response-ttl=no
use-iff-running=no
allow-interfaces=br-lan # 指定监听的网络接口
[publish]
publish-addresses=yes
publish-hinfo=yes
publish-workstation=no
publish-domain=yes
[reflector]
enable-reflector=yes # 关键:启用 reflector 功能,用于跨网段转发
reflect-ipv=no
[rlimits]
rlimit-core=0
rlimit-data=4194304
rlimit-fsize=0
rlimit-nofile=30
rlimit-stack=4194304
rlimit-nproc=3
关键配置说明
– allow-interfaces=br-lan:指定 Avahi 监听的网络接口
– enable-reflector=yes:启用 reflector 功能,这是实现跨网段 mDNS 的核心
参考:
https://openwrt.org/docs/guide-user/network/zeroconfig/zeroconf
安装插件
在 pfSense 的 Package Manager 中搜索并安装 avahi 插件。
关键问题:WAN 接口配置
这里我踩了个坑。pfSense 默认不允许在 WAN 接口启用 mDNS,这是出于安全考虑(如果 WAN 是公网,确实不应该暴露 mDNS)。
但在我的两层路由场景下,二级路由的 WAN 接口连接的是一级路由的 LAN,需要在 WAN 接口启用 mDNS 才能实现跨网段通信。
解决方法:修改插件源码
编辑 /usr/local/www/avahi_settings.php,找到并注释掉 WAN 过滤代码:
// vi /usr/local/www/avahi_settings.php
// 找到两处 wan 的过滤代码,注释掉:
// unset($available_interfaces['wan']);
修改后,在 Web 控制台就可以看到 WAN 选项了,同时选中 WAN 和 LAN 启用。
生成的配置文件
修改后 pfSense 会自动生成配置文件(位于 /usr/local/etc/avahi/avahi-daemon.conf):
这里需要注意:不推荐直接手动修改这个配置文件,因为它会被 GUI 覆盖。建议通过修改 PHP 源码让 GUI 支持 WAN 配置。
参考配置内容
# /usr/local/etc/avahi/avahi-daemon.conf
[server]
allow-interfaces=em0,em1 # WAN 和 LAN 接口
use-ipv4=yes
use-ipv6=no
[publish]
publish-addresses=yes
publish-domain=yes
[reflector]
enable-reflector=yes # 启用跨网段转发
可选:启用 D-Bus
某些情况下可能需要启用 D-Bus:
mkdir -p /var/run/dbus/
dbus-daemon --system
至此 pfSense 的配置就完成了。
重要:mDNS 使用 UDP 5353 端口,需要在防火墙中开放此端口。
确保允许以下流量:
– 源:LAN 主机
– 目标:路由器本机(224.0.0.251,mDNS 组播地址)
– 端口:UDP 5353
具体配置方法因路由器而异,在 OpenWrt 或 pfSense 的防火墙规则中添加即可。
路由器配置完成后,还需要配置各个主机才能使用 mDNS。我这里以 Ubuntu Server 为例。
首先给主机设置一个有意义的 hostname:
sudo hostnamectl set-hostname server3
之后就可以通过 server3.local 访问这台主机了。
mDNS 的一大优势是不需要静态 IP,所以把网络配置改为 DHCP:
# 编辑 netplan 配置
vim /etc/netplan/00-installer-config.yaml
network:
ethernets:
ens34:
dhcp4: true
version: 2
# 应用配置
netplan apply
Ubuntu 新版本使用 systemd-resolved 管理 DNS,需要在这里启用 mDNS:
# 编辑配置文件
vim /etc/systemd/resolved.conf
[Resolve]
MulticastDNS=yes
LLMNR=yes
或者用命令一键修改:
sed -i "s|#MulticastDNS=no|MulticastDNS=yes|g" /etc/systemd/resolved.conf
sed -i "s|#LLMNR=no|LLMNR=yes|g" /etc/systemd/resolved.conf
systemctl restart systemd-resolved
这里有个大坑。即使修改了 resolved.conf,mDNS 在网络接口上仍然是关闭的:
# 检查接口的 mDNS 状态
resolvectl mdns ens34
# 输出:Link 2 (ens34): no
# 手动启用
resolvectl mdns ens34 yes
但这个设置重启后会失效,因为 Netplan 不支持 mDNS 配置(相关 Bug,2019 年提出至今未修复)。
Netplan 会在
/run目录下生成配置文件,优先级高于/etc,导致手动修改无效。
解决方案:创建 systemd 服务
既然是开机自启动的问题,那就用 systemd 来解决:
创建 systemd 服务文件:
cat << EOF > /etc/systemd/system/user-set-mdns@.service
[Unit]
Description=Enable MulticastDNS on network interface
After=systemd-resolved.service
[Service]
ExecStart=resolvectl mdns %i yes
[Install]
WantedBy=multi-user.target
EOF
启用服务(替换 ens34 为你的网卡名称):
sudo systemctl enable user-set-mdns@ens34
sudo systemctl start user-set-mdns@ens34
sudo systemctl status user-set-mdns@ens34
至此,主机的 mDNS 配置就完成了,重启后也会自动生效。
如果你的系统没有使用 systemd-resolved(比如老版本的 Ubuntu 或 Debian),可以直接安装 Avahi:
sudo apt-get install avahi-daemon libnss-mdns libnss-mymachines
安装后 Avahi 会自动启动,无需额外配置。
配置完成后,让我们测试一下效果。
现在可以抛弃 IP 地址,直接使用 .local 域名访问设备:
ping server3.local
ping code-env.local
ping vm-proxy.local
ping pfsense.local
ping openwrt.local
SSH 连接
# 以前
ssh user@192.168.2.101
# 现在
ssh user@server3.local
访问 Web 服务
# 以前
http://192.168.2.88:8080
# 现在
http://vm-proxy.local:8080
容器配置
# docker-compose.yml
services:
app:
environment:
- DATABASE_URL=postgresql://postgres@db-server.local:5432/mydb
最重要的是测试跨网段访问,确认 reflector 功能正常工作:
# 从一级网络(192.168.1.x)访问二级网络设备
ping vm-server.local # 这台设备在 192.168.2.x 网段
# 从二级网络访问一级网络设备
ping openwrt.local # 这台设备在 192.168.1.x 网段
如果能 ping 通,说明 mDNS reflector 配置成功!
后续重新部署时发现一个问题:如果 pfSense 二级路由使用静态 IP,会导致一级路由无法获取二级的 mDNS 记录。
解决方法
– 在一级路由(OpenWrt)上通过 DHCP 静态绑定给二级路由分配 IP
– 不要在二级路由上直接配置静态 IP
– 配置好后重启二级路由
如果你习惯用命令行配置 OpenWrt 防火墙,可以使用以下命令:
uci -q delete firewall.mdns
uci set firewall.mdns="rule"
uci set firewall.mdns.name="Allow-mDNS"
uci set firewall.mdns.src="*"
uci set firewall.mdns.src_port="5353"
uci set firewall.mdns.dest_ip="224.0.0.251"
uci set firewall.mdns.dest_port="5353"
uci set firewall.mdns.proto="udp"
uci set firewall.mdns.target="ACCEPT"
uci commit firewall
/etc/init.d/firewall restart
配置完 mDNS 已经几个月了,现在回想起来,这是我在 Homelab 中做的最有价值的优化之一。
管理效率提升
– 不再需要维护一个 IP 地址清单
– 设备迁移或重启后不用担心 IP 变化
– 写配置文件时直接用域名,可读性大大提升
实际案例
最近我重装了一台服务器,以前的流程是:
1. 安装系统
2. 登录路由器配置静态 IP 绑定
3. 更新所有相关配置文件中的 IP
4. 重启依赖这台服务器的其他服务
现在的流程:
1. 安装系统
2. 设置 hostname
3. 完事
其他服务根本不需要改配置,因为它们用的是 server3.local 这样的域名,自动就能找到新的 IP。
命名规范很重要
建议给设备起一个有意义的 hostname:
– nas.local 而不是 server1.local
– pve-node1.local 而不是 vm1.local
– k8s-master.local 而不是 ubuntu-001.local
好的命名可以让你半年后还记得这台设备是干什么的。
文档还是要有的
虽然不用记 IP 了,但建议维护一个简单的设备清单:
– 设备名称和 hostname
– 主要用途和运行的服务
– 重要配置文件位置
安全性考虑
mDNS 只适合内网使用,不要在公网暴露:
– 路由器 WAN 口不要启用 mDNS
– 如果有公网 IP,确保防火墙规则正确
– mDNS 流量不应该离开你的局域网
mDNS 确实是 Homelab 的良药。它解决了 IP 地址管理的痛点,让网络配置更加灵活和优雅。虽然配置过程有一些坑(特别是 Netplan 的问题),但一旦配置好,体验提升是显著的。
如果你也在运营 Homelab,强烈建议试试 mDNS。配置时间不会超过一个下午,但带来的便利是长期的。
希望这篇文章能够帮助你顺利配置 mDNS,少走一些弯路。
AI 创作声明:本系列文章由笔者借助 ChatGPT, Kimi K2, 豆包和 Cursor 等 AI 工具创作,有很大篇幅的内容完全由 AI 在我的指导下生成。如有错误,还请指正。
网络连接是现代桌面的基础功能,涉及硬件驱动、固件加载、网络管理和 DNS 解析等多个环节。
本文将从网卡驱动开始,经过内核网络栈,到达应用层,了解 Linux 网络系统的完整架构,包括如何配置网络连接,如何设置防火墙规则,以及如何诊断各种网络问题。
网络连接是现代桌面的基础功能,涉及硬件驱动、固件加载、网络管理和 DNS 解析等多个环节。网络故障是最常见的桌面问题之一,理解其工作原理有助于快速定位和解决连接问题。
现代 Linux 桌面大多使用 systemd-networkd 配合 iwd 进行网络管理,形成完整的网络解决方案。
虽然目前仍有部分系统默认使用 NetworkManager 管理网络,用 wpa_supplicant 管理 WiFi, 但这已经不够「现代」了(逃
网络协议栈:
主要组件:
有线网络:
无线网络:
网络管理命令:
# 查看接口状态
ip link show
ip addr show
# 无线网络管理(iwd)
iwctl station wlan0 scan
iwctl station wlan0 connect "SSID"
# 网络服务状态
systemctl status systemd-networkd iwd
# DNS 解析测试
resolvectl query example.com
resolvectl status现代网络正在往 IPv6 迁移的过程中,目前仍有许多站点都只支持 IPv6,因此 IPv4+IPv6 双栈成为一个过渡方案,systemd-networkd 提供完整的双栈支持。
双栈特点:
getaddrinfo() 来实现该逻辑,可通过 /etc/gai.conf 调整该函数的地址排序算法。因为 APP 通常直接使用第一条记录发起连接,所以 /etc/gai.conf 通常能直接决定系统中是 IPv6 优先还是 IPv4 优先。双栈验证:
# 查看 IPv4 配置
ip -4 addr show
ip -4 route
# 查看 IPv6 配置
ip -6 addr show
ping -6 2001:4860:4860::8888
# DNS 双栈测试
nslookup -type=A google.com
nslookup -type=AAAA google.com连接问题诊断流程:
# 检查接口存在
ip link show
# 查看驱动加载
dmesg | grep -i firmware
lspci | grep -i network# 有线:检查链路状态
ethtool eth0
# 无线:扫描网络
iw dev wlan0 scan | grep SSID# DHCP 状态
journalctl -u systemd-networkd
# IP 配置检查
ip addr show dev eth0
# 路由表
ip route# DNS 配置
resolvectl status
cat /etc/resolv.conf
# 解析测试
dig @8.8.8.8 example.com
nslookup example.com常见问题与解决:
IPv6AcceptRA 配置nftables 是现代 Linux 的防火墙解决方案,它提供比 iptables 更简洁的语法和更好的性能。
基本概念:
nftables 的四表五链、规则等概念跟 iptables 是完全一致的,这一部分可以参考我之前的文章iptables 及 docker 容器网络分析, 这里不再赘述。
NixOS 配置示例:
# configuration.nix
networking.nftables = {
enable = true;
ruleset = ''
# 定义表
table inet filter {
# 定义链
chain input {
type filter hook input priority 0; policy drop;
# 允许回环接口
if lo accept
# 允许已建立的连接
ct state established,related accept
# 允许 SSH
tcp dport 22 accept
# 允许 HTTP/HTTPS
tcp dport {80, 443} accept
# 允许 DNS
udp dport 53 accept
tcp dport 53 accept
# 允许 DHCP
udp dport 67 accept
udp dport 68 accept
# 允许 ICMP
icmp type {echo-request, echo-reply, destination-unreachable} accept
ip6 nexthdr icmpv6 icmpv6 type {echo-request, echo-reply, destination-unreachable} accept
}
chain forward {
type filter hook forward priority 0; policy drop;
}
chain output {
type filter hook output priority 0; policy accept;
}
}
'';
};常用 nftables 命令:
# 查看当前规则
nft list ruleset
# 查看特定表
nft list table inet filter
# 临时添加规则
nft add rule inet filter input tcp dport 8080 accept
# 删除规则
nft delete rule inet filter input handle <handle>
# 清空表
nft flush table inet filter端口转发配置:
networking.nftables.ruleset = ''
table inet nat {
chain prerouting {
type nat hook prerouting priority 0;
# 端口转发:将外部 8080 端口转发到内网 192.168.1.100:80
tcp dport 8080 dnat to 192.168.1.100:80
}
chain postrouting {
type nat hook postrouting priority 100;
# 源地址转换(SNAT)
oifname "eth0" masquerade
}
}
'';WireGuard 配置:
# configuration.nix
networking.wireguard.interfaces = {
wg0 = {
ips = [ "10.0.0.2/24" ];
privateKeyFile = "/etc/wireguard/private.key";
peers = [
{
publicKey = "peer-public-key";
allowedIPs = [ "0.0.0.0/0" ];
endpoint = "vpn.example.com:51820";
persistentKeepalive = 25;
}
];
};
};TUN/TAP 接口:
# 创建 TUN 接口
ip tuntap add dev tun0 mode tun
ip addr add 10.0.0.1/24 dev tun0
ip link set tun0 up
# 创建 TAP 接口
ip tuntap add dev tap0 mode tap
ip addr add 192.168.100.1/24 dev tap0
ip link set tap0 up桥接网络:
# 创建网桥
ip link add name br0 type bridge
ip link set dev br0 up
# 添加接口到网桥
ip link set dev eth1 master br0
ip link set dev tap0 master br0
# 配置网桥 IP
ip addr add 192.168.1.1/24 dev br0Docker 网络管理:
# 查看网络
docker network ls
# 创建自定义网络
docker network create --driver bridge --subnet=172.20.0.0/16 mynetwork
# 连接容器到网络
docker network connect mynetwork container_name
# 查看网络详情
docker network inspect mynetworkPodman 网络配置:
# 创建网络
podman network create mynet
# 运行容器
podman run --network mynet -d nginx
# 查看网络
podman network ls内核网络参数:
# configuration.nix
boot.kernel.sysctl = {
# TCP 缓冲区大小
"net.core.rmem_max" = 134217728;
"net.core.wmem_max" = 134217728;
"net.ipv4.tcp_rmem" = "4096 87380 134217728";
"net.ipv4.tcp_wmem" = "4096 65536 134217728";
# TCP 拥塞控制
"net.ipv4.tcp_congestion_control" = "bbr";
# 连接跟踪
"net.netfilter.nf_conntrack_max" = 1048576;
"net.netfilter.nf_conntrack_tcp_timeout_established" = 3600;
# 网络队列
"net.core.netdev_max_backlog" = 5000;
"net.core.netdev_budget" = 600;
};网络参数调优:
TCP 缓冲区优化:
net.core.rmem_max = 134217728 设置 TCP 接收缓冲区的最大值为 128MB。更大的接收缓冲区可以处理突发的高流量,减少丢包,提高网络吞吐量,特别适合高带宽网络环境,适用于高带宽、高延迟网络,如光纤网络、VPN 连接。
net.core.wmem_max = 134217728 设置 TCP 发送缓冲区的最大值为 128MB。更大的发送缓冲区可以缓存更多待发送数据,提高发送效率,减少发送阻塞,提高网络传输效率,适用于大文件传输、流媒体上传、高并发网络应用。
net.ipv4.tcp_rmem = "4096 87380 134217728" 设置 TCP 接收缓冲区的初始值、默认值和最大值。参数说明:初始值 4KB,默认值 87KB,最大值 128MB。动态调整接收缓冲区大小,根据网络条件自动优化,在低延迟和高吞吐量之间自动平衡。
net.ipv4.tcp_wmem = "4096 65536 134217728" 设置 TCP 发送缓冲区的初始值、默认值和最大值。参数说明:初始值 4KB,默认值 64KB,最大值 128MB。动态调整发送缓冲区大小,适应不同的网络负载,在内存使用和网络性能之间找到最佳平衡点。
TCP 拥塞控制优化:
net.ipv4.tcp_congestion_control = "bbr" 使用 BBR(Bottleneck Bandwidth and RTT)拥塞控制算法。BBR 是 Google 开发的现代拥塞控制算法,基于带宽和延迟测量,在高带宽、高延迟网络环境下性能更好,减少延迟和丢包,适用于现代网络环境,特别是高带宽网络和长距离连接。
连接跟踪优化:
net.netfilter.nf_conntrack_max = 1048576 增加连接跟踪表大小到 100 万条记录。支持更多并发网络连接,避免连接跟踪表溢出,支持高并发网络应用,如 P2P 下载、多用户服务,适用于服务器环境、高并发网络应用。
net.netfilter.nf_conntrack_tcp_timeout_established = 3600 设置已建立连接的超时时间为 1
小时。延长连接跟踪时间,减少连接重建的频率,减少连接重建开销,提高长连接应用的性能,适用于长连接应用,如数据库连接、WebSocket 连接。
网络队列优化:
net.core.netdev_max_backlog = 5000 增加网络设备接收队列大小到 5000 个数据包。更大的接收队列可以处理突发流量,减少丢包,提高网络处理能力,减少因队列满而导致的丢包,适用于高流量网络环境,如服务器、网络设备。
net.core.netdev_budget = 600 增加每次网络处理的数据包数量到 600 个。提高网络处理效率,减少处理开销,提高网络吞吐量,减少 CPU 使用率,适用于高负载网络环境,需要优化网络处理性能。
优化效果评估:通过缓冲区优化,网络吞吐量可提升 20-50%;BBR 拥塞控制算法可显著减少网络延迟;连接跟踪优化支持更多并发连接;队列优化减少丢包,提高网络稳定性。
网络流量监控:
# 实时流量监控
iftop -i eth0
# 网络连接监控
netstat -tuln
ss -tuln
# 网络统计
cat /proc/net/dev
cat /proc/net/snmp
# 带宽测试
iperf3 -s # 服务器端
iperf3 -c server_ip # 客户端网络延迟分析:
# ping 测试
ping -c 10 8.8.8.8
# 路由跟踪
traceroute 8.8.8.8
mtr 8.8.8.8
# 网络质量测试
qperf server_ip tcp_bw tcp_lat连接问题排查:
# 检查网络接口状态
ip link show
ip addr show
# 检查路由表
ip route show
ip route get 8.8.8.8
# 检查 ARP 表
ip neigh show
# 检查网络统计
cat /proc/net/dev
cat /proc/net/snmpDNS 问题排查:
# 测试 DNS 解析
dig @8.8.8.8 example.com
nslookup example.com
# 检查 DNS 配置
resolvectl status
cat /etc/resolv.conf
# 测试 DNS 性能
dig @8.8.8.8 example.com +stats防火墙问题排查:
# 检查防火墙规则
nft list ruleset
iptables -L -v -n
# 测试端口连通性
telnet server_ip port
nc -zv server_ip port
# 检查连接跟踪
cat /proc/net/nf_conntrack网卡绑定配置:
# configuration.nix
networking.bonds = {
bond0 = {
interfaces = [ "eth0" "eth1" ];
driverOptions = {
mode = "802.3ad";
lacp_rate = "fast";
xmit_hash_policy = "layer3+4";
};
};
};
networking.interfaces.bond0.ipv4.addresses = [{
address = "192.168.1.100";
prefixLength = 24;
}];VLAN 网络配置:
# configuration.nix
networking.vlans = {
vlan100 = { id = 100; interface = "eth0"; };
vlan200 = { id = 200; interface = "eth0"; };
};
networking.interfaces.vlan100.ipv4.addresses = [{
address = "192.168.100.1";
prefixLength = 24;
}];
networking.interfaces.vlan200.ipv4.addresses = [{
address = "192.168.200.1";
prefixLength = 24;
}];创建网络命名空间:
# 创建命名空间
ip netns add ns1
ip netns add ns2
# 创建 veth 对
ip link add veth1 type veth peer name veth2
# 将接口移到命名空间
ip link set veth1 netns ns1
ip link set veth2 netns ns2
# 配置命名空间内的网络
ip netns exec ns1 ip addr add 10.0.1.1/24 dev veth1
ip netns exec ns1 ip link set veth1 up
ip netns exec ns2 ip addr add 10.0.1.2/24 dev veth2
ip netns exec ns2 ip link set veth2 up
# 测试连通性
ip netns exec ns1 ping 10.0.1.2网络是计算机科学中最复杂的技术之一,数据在互联网中的流动造就了现代信息社会,现代 AI 的发展也与现代网络中产生的超大规模数据密不可分。
本文只是对 Linux 网络的一个简单介绍,下一篇文章我们会聊聊系统关机和故障排查,看看系统是如何优雅地关机的,以及遇到问题时该如何处理。
# 网络接口管理
ip link show # 查看网络接口
ip addr show # 查看 IP 地址
ip route show # 查看路由表
ip neigh show # 查看 ARP 表
# 网络连接管理
ss -tuln # 查看网络连接
netstat -tuln # 传统网络连接查看
lsof -i # 查看端口占用
# 网络测试
ping -c 4 8.8.8.8 # ping 测试
traceroute 8.8.8.8 # 路由跟踪
mtr 8.8.8.8 # 网络质量测试# nftables 管理
nft list ruleset # 查看所有规则
nft list table inet filter # 查看特定表
nft add rule inet filter input tcp dport 8080 accept # 添加规则
nft delete rule inet filter input handle <handle> # 删除规则
# iptables 管理(传统)
iptables -L -v -n # 查看规则
iptables -A INPUT -p tcp --dport 22 -j ACCEPT # 添加规则
iptables -D INPUT -p tcp --dport 22 -j ACCEPT # 删除规则# DNS 解析测试
dig @8.8.8.8 example.com # DNS 查询
nslookup example.com # 传统 DNS 查询
resolvectl query example.com # systemd-resolved 查询
# 网络监控
iftop -i eth0 # 实时流量监控
tcpdump -i eth0 # 网络包捕获
wireshark # 图形化网络分析
# 带宽测试
iperf3 -s # 启动 iperf3 服务器
iperf3 -c server_ip # 客户端测试# 网络配置
/etc/systemd/network/ # systemd-networkd 配置
/etc/nftables.conf # nftables 配置
/etc/resolv.conf # DNS 配置
# 网络服务
/etc/systemd/system/ # systemd 服务配置
/etc/wireguard/ # WireGuard 配置
/etc/openvpn/ # OpenVPN 配置
# 网络状态
/proc/net/dev # 网络接口统计
/proc/net/snmp # 网络协议统计
/proc/net/nf_conntrack # 连接跟踪表去年夏天,我花了不少时间搭建博客图床,核心目标是分地区解析 DNS,让国内外访客都能快速加载图片。技术方案看起来完美无缺,直到最近群友反馈首次访问时图片加载很慢,我才发现问题所在。

955 毫秒的 DNS 解析时长! 这个数字让我大吃一惊。访客点开博客后,光是确定图片服务器位置就要等将近一秒,这完全抵消了 CDN 优化的效果。
主要是 DNS 缓存的"功劳"。它会为后续访问记住解析结果,让我的本地测试和复访测试看起来都很正常。直到用户反馈,结合最近准备秋招复习的 DNS 解析流程(递归查询、权威查询、根域名、顶级域名等),我才定位到问题:首次访问时的 DNS 解析延迟。
让我们看看访客访问 static.031130.xyz 时,DNS 是如何工作的:
sequenceDiagram
participant User as 访客浏览器
participant Local as 本地 DNS
participant CF as Cloudflare<br/>(国外权威)
participant DP as DNSPod<br/>(国内权威)
participant CDN as CDN 节点
User->>Local: 请求 static.031130.xyz
Local->>CF: 查询 031130.xyz 权威
Note over Local,CF: 跨国查询,延迟高
CF->>Local: CNAME: cdn-cname.zhul.in
Local->>DP: 查询 zhul.in 权威
DP->>Local: CNAME: small-storage-cdn.b0.aicdn.com
Local->>DP: 查询 aicdn.com
DP->>Local: CNAME: nm.aicdn.com
Local->>DP: 查询最终 IP
DP->>Local: 返回 CDN IP
Local->>User: 返回解析结果
User->>CDN: 连接并下载图片
问题就在这里:前两步查询指向了国外的 Cloudflare 权威服务器。对于国内用户,虽然最终解析到的 CDN 节点是国内的,但跨国 DNS 查询就足以拖垮首次访问体验。那 955ms 的延迟,基本都耗在与国外 DNS 服务器的通信上了。
针对这个问题,我采取了三个措施:
在博客 HTML 的 <head> 中添加:
<link rel="dns-prefetch" href="//static.031130.xyz">
这样浏览器在渲染页面时就会提前解析图床域名,等真正需要加载图片时,DNS 结果可能已经准备好了。
将 static.031130.xyz 的 CNAME 记录 TTL 值调大(从几分钟延长到几小时甚至一天)。这样本地 DNS 服务器会缓存更久,后续用户可以直接使用缓存结果,省掉权威查询。
将 031130.xyz 域名的权威 DNS 服务器从 Cloudflare 迁移到国内的 DNSPod:
graph TB
subgraph "优化前"
A1[访客] --> B1[本地 DNS]
B1 --> C1[Cloudflare 权威<br/>国外]
C1 --> D1[DNSPod 权威<br/>国内]
D1 --> E1[CDN 节点]
style C1 fill:#ffcccc
end
graph TB
subgraph "优化后"
A2[访客] --> B2[本地 DNS]
B2 --> D2[DNSPod 权威<br/>国内]
D2 --> E2[CDN 节点]
style D2 fill:#ccffcc
end
迁移后的好处:
031130.xyz 时,直接找到国内的 DNSPod,响应快static.031130.xyz -> small-storage-cdn.b0.aicdn.com,无需中间跳转虽然 DNS 缓存给测试带来了困难,但迁移权威 DNS + 调整 TTL + 添加预取后,首次访问的 DNS 解析时间降到了可接受的范围。
DNS 位置很重要:涉及多地优化时,权威 DNS 的地理位置对首次访问延迟影响很大。优先使用国内权威服务器。
首次访问是关键:虽然缓存能帮助后续访问,但首次访问体验直接影响用户印象。善用 dns-prefetch 和合理的 TTL 设置。
监控和反馈重要:本地测试环境往往有缓存加持,真实的首次访问体验需要通过监控和用户反馈来发现。
如果你需要分地区解析来让访客连接到最近的 CDN 节点,务必避开 CNAME Flattening(CNAME 拉平)。
权威 DNS 服务器(如 Cloudflare)看到 CNAME 记录后,会主动查询目标域名的最终 IP 地址,然后直接返回 IP 而不是 CNAME。
分地区解析(GeoDNS)在权威 DNS 服务器层面实现。当权威服务器执行 CNAME 拉平时,它会在自己的位置查询目标域名的 IP。如果权威 DNS 在美国,它获取的 IP 就是美国最优节点,然后把这个 IP 返回给所有地区的查询者,包括中国用户。这样,你为中国用户配置的国内 CDN IP 策略就完全失效了。
graph LR
subgraph "启用 CNAME 拉平的问题"
A[中国用户] --> B[Cloudflare 权威<br/>美国节点]
B --> C[查询目标 CNAME]
C --> D[返回美国 CDN IP]
D --> A
style D fill:#ffcccc
end
老实使用 CNAME 指向另一个支持 GeoDNS 的域名(如 static.031130.xyz -> cdn-cname.zhul.in,后者在 DNSPod 上做分地区解析),才能保证分流策略正确执行。
如果需要分地区解析功能,不要在相关域名上启用 CNAME Flattening(或 ALIAS、ANAME 等类似功能)。
因为博客域名是在阿里云购买的,先前一直顺理成章地用着阿里云的 DNS 解析。阿里云的 DNS 解析在各方面的体验都很不错,例如修改配置后就能很快更新、配置平台访问速度快、站点不会被国内的运营商污染等等,这些优点反过来可是说尽是 Cloudflare 的缺点。
但由于 Cloudflare 为网站提供的各种免费服务十分诱人,加之我想利用 Cloudflare 的 CDN 搭建博客图床,终究是把站点交给了 Cloudflare 管理。本文记录了从阿里云迁移站点的过程和一些必要的 Nginx 配置。
打开 Cloudflare 官网,注册帐号后选择添加站点,输入域名后点击继续。
按需选择计划,对于普通的小站点来说,Free 计划足矣。点击继续后,Cloudflare 会检测站点目前已有的部分 DNS 记录,其余未检测出的记录日后再手动添加,最关键的是检查域名指向服务器 IP 地址的 A 记录是否正确。
在「代理状态」一列可以选择该 DNS 记录是否使用 Cloudflare 的 CDN,激活后图标显示一朵黄色的云。Cloudflare 的 CDN 在国内速度很慢,一直被称为减速 CDN,所以我都选择「仅 DNS」。此前我也担心 Cloudflare 的 DNS 解析会不会也像其 CDN 一样龟速,幸好解析速度并不慢,我的担心是多虑了。
提交 DNS 记录后,Cloudflare 会提示删除阿里云的 DNS 服务器,以 Cloudflare 的 DNS 服务器代替之,接着就转到阿里云的控制中心操作。
登录阿里云,进入控制台。在云解析 DNS - 域名解析下找到迁移的域名,在解析设置中保存了站点的 DNS 记录。将记录备份,后续要将所有记录导入 Cloudflare。站点交由 Cloudflare 解析后,阿里云中的解析设置也会失效,所以也在解析设置中将所有解析都停用。
在阿里云控制台中来到域名控制台 - 域名列表,选择域名的管理 - DNS 管理 - DNS 修改 - 修改 DNS 服务器,将 Cloudflare 提供的两个 DNS 服务器地址填入其中。
修改 DNS 服务器一般需要 24-48 h 生效,生效后 Cloudflare 会发送邮件通知。如果迟迟没有收到邮件,也可以到 Cloudflare 手动验证网站。验证成功后 Cloudflare 会指引是否开启 Brotli 压缩等功能,按需选择即可。至此,站点已经交由 Cloudflare 托管。如果站点是由 Nginx 搭建的,那么就还需要考虑 Nginx 的 SSL 设置是否与 Cloudflare 兼容。
在 Cloudflare 的 SSL/TLS 设置界面可以看到,用户访问由 Cloudflare 托管的站点的过程中有 3 个实体,根据实体间通信安全等级的不同可以分为 4 种模式:
现在的站点一般都使用了 HTTPS,还在使用 HTTP 的站长快去申请个 SSL 证书吧,同时通过 Nginx 将访问 80 端口的 HTTP 流量强制重定向到 HTTPS 入口。若使用这样的 Nginx 配置又开启的「灵活」模式,用户发起访问请求后,Cloudflare 使用 HTTP 交由 Nginx,Nginx 告知用户重定向为 HTTPS,但Cloudflare 仍使用 HTTP 与 Nginx 通信,该过程无限循环,出现 301 重定向次数过多。
为了保证站点的安全性和避免以上问题,推荐配置好站点的 HTTPS 后,在 Cloudflare 的 SSL/TLS 中
最后附上我的 Nginx 配置供参考:
server {
listen 443 ssl http2;
server_name leonis.cc;
root /home/Leo/web/blog;
# SSL 配置
ssl_certificate /etc/nginx/cert/leonis.cc.cer;
ssl_certificate_key /etc/nginx/cert/leonis.cc.key;
ssl_session_timeout 5m;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
location / {
index index.html;
}
}
server {
listen 80;
server_name leonis.cc
# 重定向至 HTTPS,开启 Cloudflare 完全模式后不会访问 80 端口,也不会用上此处的重定向
rewrite ^/(.*)$ https://leonis.cc:443/$1 permanent;
}
Cloudflare 总体来说还是很好用的,提供了很多有意思的功能,很便利地就能体验,免去了自己动手配置的烦恼。Cloudflare 的不足仅在于在国内有时访问不畅,添加 DNS 记录后也要等比较长的时间才会更新到国内网络上,若能接受这两点,Cloudflare 的可玩性还是比其他平台更高的。
以前也尝试过在DNS上做手脚拦截广告,但因为误杀太多以及漏网之鱼太多,觉得还不如不折腾呢。
最近偶然发现了一组列表,又尝试了一番,发现效果挺不错的,手机开屏广告绝大多数不见,浏览网页时Google Ads也基本没有了,真是让我喜出望外。所以以前效果不好的原因只是因为使用的黑名单列表不好而已。
我是在路由器上的CoreDNS使用ads插件设置拦截的,所有接入的设备都可以享受到这个效果。用到3组黑名单源,分别是Anti-ad,AdGuard和EasyList,然后自己写了点代码将列表规整了一下,转成hosts文件的格式后合并为一个文件,ads插件可以直接通过http协议加载hosts格式的文件。CoreDNS的配置文件增加ads就行了:
1
2
3
4
5
#blocklist domains.txt
ads {
blacklist https://cdn.jsdelivr.net/gh/missdeer/blocklist@master/convert/alldomains.txt
nxdomain
}

Dnsmasq是一个轻量级的DNS服务器和DHCP服务器软件。它通常用于小型局域网内的网络设备(如路由器、交换机等)。D…

TLS,全称 Transport Layer Security,安全传输层协议,前身为 SSL (Secure Socket Layer,安全套接层),位于 TCP 与应用层之间。HTTPS 相对于 HTTP 来说,协议本身并未改变,而是在 TCP 与 HTTP 间添加了一层 TLS 用作加密以保证信息安全。
从 TLS 的角度说起,它希望解决网络流量明文传输存在的几类风险:窃听、篡改、伪造,这里摘录 https://zinglix.xyz/2019/05/07/tls-handshake/ 对 TLS 解决三类风险的一段总结:
但这么做就完美了吗?TLS 在握手 Client Hello 阶段的数据包,包含客户端想访问的地址等信息,而这些信息是明文传输的,这使得第三方可以通过监听等手段知道你想访问哪些网址。
本文会按照加密方式的加工流程倒序介绍,先介绍关于 TLS 握手阶段的 SNI 相关信息,再谈谈 DNS 安全层,最后会介绍下 TLS 握手指纹,通过本文,你或许可以对以下信息有更深入的了解:
本文基于个人理解与学习进行整理,如有不准确的地方还望指出,所参考的资料均在文末参考一章中罗列。本文在最后一章节对全文整理的内容进行了概况总结,已经有相关基础的同学可以直接跳转查看。
当多个网站托管在一台服务器上并共享一个 IP 地址,并且每个网站都有自己的 SSL 证书,在客户端设备尝试安全地连接到其中一个网站时,服务器可能不知道显示哪个 SSL 证书。这是因为 SSL/TLS 握手发生在客户端设备通过 HTTP 指示连接到某个网站之前。
SNI (Server Name Indication,服务器名称指示) 是为了解决一个服务器使用多个域名和证书的 TLS扩展,主要解决一台服务器只能使用一个证书的缺点。SNI 是 TLS 协议(以前称为 SSL 协议)的扩展,该协议在 HTTPS 中使用。它包含在 TLS/SSL 握手流程中,以确保客户端设备能够看到他们尝试访问的网站的正确 SSL 证书。该扩展使得可以在 TLS 握手期间指定网站的主机名或域名,而不是在握手之后打开 HTTP 连接时指定。
开启 SNI 后,允许客户端在发起 SSL 握手请求时就提交请求的域名信息,负载均衡收到 SSL 请求后,会根据域名去查找证书,如果找到域名对应的证书,则返回该证书;如果没有找到域名对应的证书,则返回缺省证书。负载均衡在配置 HTTPS 监听器支持此功能,即支持绑定多个证书。
TLS 的做法,是在 TLS 握手第一阶段 ClientHello (客户端问候)的报文中就添加包含主机名。SNI 在 TLSv1.2 开始得到支持。从 OpenSSL 0.9.8 版本开始支持。
SNI 将域名添加到TLS握手过程,以便 TLS 程序到达正确的域名并接收正确的 SSL 证书,从而使其余 TLS 握手能够正常进行。
虽然 TLS 能够加密整个通信过程,但是在协商的过程中依旧有很多隐私敏感的参数不得不以明文方式传输,其中最为重要且棘手的就是将要访问的域名,即 SNI。
加密 SNI (Encrypted Server Name Indication, ESNI) 通过加密客户端问候的 SNI 部分来添加到 SNI 扩展,这可以防止任何在客户端和服务器之间窥探的人看到客户端正在请求哪个证书,从而进一步保护客户端。Cloudflare 和 Mozilla Firefox 于 2018 年推出了对 ESNI 的支持。
ESNI 可以确保正在侦听的第三方无法监视 TLS 握手流程并以此确定用户正在访问哪些网站。
ESNI 通过公钥加密客户端问候消息的 SNI 部分(仅此部分),来保护 SNI 的私密性。加密仅在通信双方(在此情况下为客户端和服务器)都有用于加密和解密信息的密钥时才起作用,就像两个人只有在都有储物柜密钥时才能使用同一储物柜一样。
由于客户端问候消息是在客户端和服务器协商 TLS 加密密钥之前发送的,因此 ESNI 加密密钥必须以其他方式进行传输。
Web 服务器可以在其 DNS 记录中添加一个公钥,这样,当客户端查找正确的服务器地址时,同时能找到该服务器的公钥。这有点像将房门钥匙放在屋外的密码箱中,以便访客可以安全地进入房屋。然后,客户端即可使用公钥来加密 SNI 记录,以便只有特定的服务器才能解密它。

ESNI 存在问题。首先是密钥的分发,Cloudflare 在部署时每个小时都会轮换密钥,这样可以降低密钥泄露带来的损失,但是 DNS 有缓存的机制,客户端很可能获得的是过时的密钥,此时客户端就无法用 ESNI 继续进行连接。其次是对网站的 DNS 请求可能返回有几个 IP 地址,每个地址分别代表了不同的 CDN 服务器,然而 ESNI 的 TXT 记录只有一个,可能会将该密钥发送给了错误的服务器导致握手失败。
自从 ESNI 规范草案在 IETF 上发布以来,分析表明仅仅加密 SNI 扩展提供的保护是不完整的。为了解决 ESNI 的问题,最近发布的规范不再只加密 SNI 扩展,而是对整个 Client Hello 信息进行加密,因此标准名称从 ESNI 也变成了 ECH。
ECH(Encrypted Client Hello,也称加密客户端问候)出现的目标就是就是为了克服 ESNI 的缺陷,同时也正如其名,ECH 有着更大的野心,不单单加密 SNI,而是要加密整个 Client Hello。
ECH 同样采用 DoH (后文会进行详细介绍,此处可暂时理解成 DNS 安全层的一种实现)进行密钥的分发,但是在分发过程上进行了改进。如果解密失败,ESNI 服务器会中止连接,而 ECH 服务器会提供给客户端一个公钥供客户端重试连接,以期可以完成握手。
ECH 协议实际上涉及两个 ClientHello 消息:ClientHelloOuter,它像往常一样以明文形式发送;ClientHelloInner,它被加密并作为 ClientHelloOuter 的扩展发送。服务器仅使用其中一个 ClientHello 完成握手:如果解密成功,则继续使用 ClientHelloInner;否则,它只使用 ClientHelloOuter。
ClientHelloInner 由客户端想要用于连接的握手参数组成。这包括它想要访问的源服务器的 SNI、ALPN 列表等。ClientHelloOuter 虽然也是一个成熟的 ClientHello 消息,但不用于预期的连接。相反,握手是由 ECH 服务提供者完成,在无法完成解密的情况下,它会向客户端发出信号,表明由于解密失败而无法到达其预期的目的地。此时,服务提供商还会发送正确的 ECH 公钥,客户端可以使用该公钥重试握手,从而“更正”客户端的配置。

DNS 是互联网的电话簿;DNS 解析器将人类可读的域名转换为机器可读的 IP 地址。默认情况下,DNS 查询和响应以明文形式(通过 UDP)发送,这意味着它们可以被网络、ISP 或任何能够监视传输的人读取。即使网站使用 HTTPS,也会显示导航到该网站所需的 DNS 查询。
这种隐私上的欠缺对安全有着巨大影响,如果 DNS 查询不是私密的,则攻击者可以轻松跟踪用户的Web 浏览行为。
基于 TLS 的 DNS(DNS over TLS,简称 DoT)是加密 DNS 查询以确保其安全和私密的一项标准。DoT 使用安全协议 TLS,这与 HTTPS 网站用来加密和认证通信的协议相同。DoT 在用于 DNS 查询的用户数据报协议(TCP)的基础上添加了 TLS 加密,这可以确保 DNS 请求和响应不会被在途攻击篡改或伪造。
与 DoT 采用在 TCP 协议上处理稍有不同的是,还存在另一个在 UDP 协议上加密的标准,DNS over DTLS,即基于 UDP 的 DNS TLS 加密协议标准。
基于 HTTPS 的 DNS 或 DoH 是 DoT 的替代标准。使用 DoH 时,DNS 查询和响应会得到加密,但它们是通过 HTTP 或 HTTP/2 协议发送,而不是直接通过 UDP 发送。与 DoT 一样,DoH 也能确保攻击者无法伪造或篡改 DNS 流量。从网络管理员角度来看,DoH 流量表现为与其他 HTTPS 流量一样,如普通用户与网站和 Web 应用进行的交互。
这两项标准都是单独开发的,并且各有各的 RFC 文档,但 DoT 和 DoH 之间最重要的区别是它们使用的端口。DoT 仅使用端口 853,DoH 则使用端口 443,后者也是所有其他 HTTPS 流量使用的端口。
由于 DoT 具有专用端口,因此即使请求和响应本身都已加密,具有网络可见性的任何人都发现来回的 DoT 流量。DoH 则相反,DNS 查询和响应伪装在其他 HTTPS 流量中,因为它们都是从同一端口进出的。
除了上文提到的几种标准外,想要达到 DNS 请求加密的目的,我们仍然有多种其他实现方式:
TLS 握手指纹又叫 SSL 指纹,或者 JA3 指纹,是根据客户端向服务端发送的 Client Hello 信息中部分字段计算得出的 hash 值信息。
此外,在 TLS 握手中还有服务端响应的 Server Hello,这类信息也有特征,根据类似的思路可以得到 JA3S 指纹。又由于服务端会根据不同的 Client Hello 响应不同的 Server Hello,根据这个又可以得到 JARM 指纹。

由于 TLS/SSL 协商以明文形式传输,因此可以使用 SSL Client Hello 数据包中的详细信息对客户端应用程序进行指纹识别。JA3 从 Client Hello 数据包中的以下字段收集十进制字节值:
SSLVersion,Cipher,SSLExtension,EllipticCurve,EllipticCurvePointFormat
// 分别代表 TLS/SSL 版本,可接受的密码,扩展列表,椭圆曲线,椭圆曲线格式
然后按顺序将这些值连接在一起,使用,分隔每个字段,使用-分隔每个字段中的每个值,如果没有 TLS/SSL 扩展则留空,最后对这些字符串进行 MD5 散列以生成易于使用和共享的32个字符指纹,这就是 JA3 客户端指纹。
对于服务端来说,同一台服务器会根据Client Hello消息及其内容以不同的方式创建其Server Hello消息。因此,这里不能像客户端和JA3那样,仅仅根据服务器的Hello消息来对其进行指纹识别。
JA3S是用于 SSL/TLS 通信的服务器端的JA3, 服务器对特定客户机响应的指纹。
JA3S 使用以下字段生成指纹:SSLVersion,Cipher,SSLExtension,在应用中,需要通过结合JA3 + JA3S对客户端与其服务器之间的整个加密协商进行指纹识别。因为服务器会对不同的客户端做出不同的响应,但对同一个客户端的响应总是相同的。
通过以上两类指纹可以来标记SSL握手中客户端、服务端特征。关于 JA3/JA3S 的详细定义可参见 https://github.com/salesforce/ja3
TLS Server 根据 TLS Client Hello 中参数的不同,返回不同的 Server Hello 数据包。而 Client Hello 的参数可以人为指定修改,因此通过发送多个精心构造(比如指定不同的TLS版本、支持套件等来试探服务端响应情况)的 Client Hello 获取其对应的特殊 Server Hello(包含服务器返回的加密套件、服务器返回选择使用的 TLS 协议版本、TLS 扩展 ALPN 协议信息、TLS 扩展列表等信息),最终形成 JARM 指纹信息,来标记服务器的特征。具体能够产生影响的参数包括但不限于:
与 JA3/JA3S 是在流量被动监听中得到的方式不同的是,JARM 是通过主动探测的方式得到。
详细定义可参见 https://github.com/salesforce/jarm
两者均是 TLS 握手信息(版本、支持套件)的简化表现形式。所以 JA3/JA3S 可以用来标记特质的客户端、服务端所产生的流量。
JA3S 指纹则根据客户端的不同环境(系统版本等)有变化。JARM 则可以用来威胁狩猎。
TLS 协议已经成为互联网上最流行的协议,以确保网络通信免受干扰和窃听。但在握手阶段,由于 SNI 信息是明文传输,这导致了客户端的访问网址等信息容易被窃听。
ESNI 是保护网络隐秘性和安全性的重要步骤,但其他新协议和功能也很重要。设计 Internet 时并未考虑安全性和隐私性,因此,在访问网站的过程中有很多步骤都是非私密的。但是,有各种新协议都有助于对每个步骤进行加密,使之免受恶意攻击者的攻击。
域名系统或 DNS 将人类可读的网站地址(如 www.example.com)与字母数字 IP 地址进行匹配。这就像在所有人都使用的大型地址簿中查找某人的地址一样。但是,普通的 DNS 未加密,这意味着任何人都可以看到某人正在查找哪个地址,并且任何人都可以伪装成地址簿。即使安装了 ESNI,攻击者仍然可以查看用户正在查询的 DNS 记录,并确定他们正在访问哪些网站。
其他三个附加协议旨在弥补这些空白:
基于 TLS 的 DNS 和基于 HTTPS 的 DNS 都在做同样的事情:使用 TLS 加密来加密 DNS 查询。它们之间的主要区别在于使用网络的哪个层以及使用哪个网络端口。DNSSEC 确认 DNS 记录真实并来自合法的 DNS 服务器,而非来自冒充 DNS 服务器的攻击者(例如,发生 DNS 缓存中毒攻击时)。
说完浏览私密性保证,我们再来看看对恶意流量的分析检测。由于网络管理人员可以识别和阻止自定义协议,很多恶意工具已经转向使用现有协议,TLS的流行为这些恶意工具提供了一个很好的选择,使用TLS协议的恶意工具可以将其流量隐藏在大量web浏览器和其他TLS的合法覆盖流量中以逃避检测。
从 TLS 连接(Client hello 阶段)中提取特定的一些字段生成指纹,通过分析恶意工具和常规工具在协议信息上的区别,可以进一步分析或者研究,通过连接模式或时间特征来检测恶意流量。