Ollama 本地部署模型,让 OpenClaw 实现 Token 自由
事情是这样的。那天我正在愉快地摸鱼,突然收到了一条提示:API 余额不足。就像是正看得起劲的电视剧突然断电——那个难过啊。作为一个有追求的程序员,岂能被这几块钱的 API 费用难倒?于是乎,我研究了一下怎么用 Ollama 本地部署模型,让 OpenClaw 实现 Token 自由。你们猜怎么着?成功了!而且过程比想象中简单得多。今天,伯衡君就把这个"白嫖"攻略分享出来,让大家一起快乐摸鱼……

部分开源项目源码。
专业的服务器监控和管理工具,提供实时系统监控、性能测试、数据库检测等功能。本项目包含两个版本:独立PHP探针和WordPress插件版本。
php8-probe/
├── phpprobe.php # 独立PHP探针(可直接访问)
├── php-probe-widget/ # WordPress插件版本
│ ├── php-probe-widget.php # 主插件文件
│ ├── includes/ # 小组件类
│ ├── css/ # 前端样式
│ ├── js/ # 前端脚本
│ └── README.md # 插件详细文档
├── LICENSE # 许可证
└── README.md # 本文件
 快速开始
快速开始phpprobe.php 上传到您的Web服务器特点:
 无需安装,直接使用 单文件部署,简单方便 支持多平台(Linux、Windows、macOS、FreeBSD) 实时系统监控
无需安装,直接使用 单文件部署,简单方便 支持多平台(Linux、Windows、macOS、FreeBSD) 实时系统监控php-probe-widget 文件夹复制到 wp-content/plugins/ 目录https://gitee.com/obaby/php8-probe
基于Flask和jieba的本地HTTP分词服务。
https://gitee.com/obaby/baby-jb-server
这是一个用于分析 WordPress 博客数据的 Python 工具,可以通过 WordPress REST API 获取并分析博客的文章和评论数据。
 统计指定年份发布的文章数量(按月统计)
统计指定年份发布的文章数量(按月统计) 统计指定年份的评论数量
统计指定年份的评论数量 分析评论用户的评论数排行
分析评论用户的评论数排行 将分析结果保存为 JSON 文件
将分析结果保存为 JSON 文件https://gitee.com/obaby/baby-wp-data-analysis-tool
一个用于 macOS 系统的微信双开自动化脚本,通过复制微信应用并修改 Bundle ID 实现真正的微信双开功能。
 功能特性 一键双开 – 自动完成所有设置步骤 智能检测 – 自动检测已存在的 WeChat2.app 安全可靠 – 完善的错误处理和权限检查 彩色输出 – 友好的命令行界面 进程管理 – 查看和管理微信进程 自动化设置 – 无需手动执行复杂命令
功能特性 一键双开 – 自动完成所有设置步骤 智能检测 – 自动检测已存在的 WeChat2.app 安全可靠 – 完善的错误处理和权限检查 彩色输出 – 友好的命令行界面 进程管理 – 查看和管理微信进程 自动化设置 – 无需手动执行复杂命令https://github.com/obaby/baby-wechat
基于百度地图的足迹地图。
启动服务之后,先去后台 地图 key 设置页面,添加百度地图浏览器端 ak!
启动服务之后,先去后台 地图 key 设置页面,添加百度地图浏览器端 ak!
启动服务之后,先去后台 地图 key 设置页面,添加百度地图浏览器端 ak!
为了防止 js 地址解析受限,需要同时添加服务端 ak!
为了防止 js 地址解析受限,需要同时添加服务端 ak!
为了防止 js 地址解析受限,需要同时添加服务端 ak!
添加之后,访问: http://127.0.0.1:10099/api/location/process-my-location/ 地址刷新数据库的地点坐标信息,后续无需再通过 js 接口进行解析!
https://github.com/obaby/BabyFootprintV2
Add a microblog to your site; display the microposts in a widget or using a shortcode. 增强版优化页面显示,增加分页功能。wp微博插件。
https://github.com/obaby/Simple-microblogging-wordpress-plugin
一个强大的WordPress评论过滤插件,支持字数限制、中文检测、关键词过滤等功能。
 评论过滤功能
评论过滤功能
 管理功能
管理功能
 技术特性
技术特性
https://github.com/obaby/baby-wp-comment-filter
WinRAR is a trialware file archiver utility for Windows, developed by Eugene Roshal of win.rar GmbH.
It can create and view archives in RAR or ZIP file formats and unpack numerous archive file formats.
WinRAR is not a free software. If you want to use it, you should pay to RARLAB and then you will get a license file named "rarreg.key".
This repository will tell you how WinRAR license file "rarreg.key" is generated.
WinRAR uses a signature algorithm, which is a variant of Chinese SM2 digital signature algorithm, to process the user’s name and the license type he/she got. Save the result to “rarreg.key” and add some header info, then a license file is generated.
https://github.com/obaby/winrar-keygen
一个功能强大的WordPress设备管理系统插件,支持设备分组管理、设备信息管理、自定义排序、状态跟踪等功能。
https://github.com/obaby/Baby-Device-Manager
为 WordPress RSS Feed 提供美观的网页展示样式(基于 RSS.Beauty 的 Pink 主题)。
application/xml,使浏览器按 XML 解析并应用 xml-stylesheet。pink.xsl。需在 OpenResty/Nginx 中为 .xsl 配置正确的 Content-Type(见下方配置说明),否则浏览器可能不按 XSL 解析。https://cnb.cool/oba.by/rss-beauty
Contributors: obaby
Donate Link: https://oba.by
Tags: useragent, user-agent, user agent, web, browser, web browser, operating system, platform, os, mac, apple, windows, win, linux, phone
Requires at least: 2.0
Tested up to: 6.3
Stable tag: 16.06.99
插件支持四种 IP 查询方式,可在 设置 → WP-UserAgent 中选择:
| 方式 | 说明 |
|---|---|
| IP2Location | 使用 IP2Location 数据库(需将 BIN 文件放入 show-useragent/ip2location_db/db/),依赖 Composer |
| CZDB | 使用纯真 CZDB 数据库(需授权与 db 文件放入 show-useragent/czdb/db/),依赖 Composer |
| ip2region | 使用 ip2region xdb(仅内置 ip2reginapi,不依赖 Composer)。需将 xdb 文件放入 show-useragent/ip2region_db/,文件名:ip2region_v4.xdb、ip2region_v6.xdb |
| 纯真QQWRY | 使用 qqwry_api(qqwry.dat + ipv6wry.db),无需 Composer。数据文件放入 show-useragent/qqwry_api/ipdata/ |
选择 ip2region 或 纯真QQWRY 时不会加载 vendor/autoload.php。若选择 IP2Location 或 CZDB 时 vendor 加载失败,插件会自动回退为 ip2region 模式,避免站点白屏。
WP-UserAgent is a simple plugin that allows you to display details about a computer’s operating system or web browser that your visitors comment from.
It uses the comment->agent property to access the User-Agent string. Through a series of regular expressions, this plugin is able to detect the operating system and browser which can be integrated in comments or placed in custom places through your template(s).
I’m adding new web browsers and operating systems frequently, as well as updating and optimizing the source code. Your feedback is very important, new features have been added by request, so if there’s something you would like to see in WP-UserAgent, leave a comment, and I’ll see what I can do.
WP-UserAgent was written with Geany – http://www.geany.org/
Images created with The Gimp – http://www.gimp.org/
注意:
- 使用 CZDB 时:若更新替换纯真数据库,请同步更新
show-useragent/ip2c-text.php中的$key = 'n2pf2+PrE1y9I55MjdpLpg==';- 使用 ip2region 时:将 xdb 文件放入
show-useragent/ip2region_db/(ip2region_v4.xdb、ip2region_v6.xdb),无需 Composer。
https://cnb.cool/oba.by/wp-useragent
![]()
本文永久链接 – https://tonybai.com/2026/03/14/go-sumdb-transparent-logs-supply-chain-trust
大家好,我是Tony Bai。
在 Go 语言的日常开发中,go get 是我们最熟悉的命令之一。我们理所当然地认为,只要指定了版本号,从 GitHub 或其他代码托管平台拉取下来的代码就是安全、一致的。然而,现实却远比这脆弱——Git 的 Tag 是可变的。攻击者可以发布一个带有后门的 v1.2.3 版本,在诱导受害者下载后,再通过 Force-push 将其替换为干净的代码,从而在代码审查的眼皮底下“瞒天过海”。
为了应对这种极其隐蔽的软件供应链攻击,Go 团队祭出了其包管理生态中的终极武器:Go Checksum Database (sumdb)。但很多Go开发者并不清楚Go sumdb背后的工作机制。 本文将结合 Russ Cox 和 Filippo Valsorda 的核心设计文档,拆解一下 sumdb 究竟是如何利用透明日志(Transparent Logs)和精妙的瓦片化(Tiling)算法,在不信任任何中央服务器的前提下,为全球 Go 开发者构筑起一道坚不可摧的密码学防线的。

自 Go 1.11 引入 Modules 以来,go.sum 文件成为了每个项目不可或缺的部分。它记录了依赖包的预期加密哈希值。只要 go.sum 存在,明天下载的代码就必须和今天一模一样。
但这带来了一个经典的密码学难题:TOFU(Trust On First Use,首次使用时信任)。
当你在项目中第一次引入某个第三方包时,本地没有它的哈希记录。此时 go 命令只能“盲目”去源站(一般是github)下载,计算哈希并写入 go.sum。如果恰好在这一次下载时网络被劫持,或者作者刚好推送了恶意代码,那么恶意代码的哈希就会被“合法化”并永久记录在你的项目中。
为了解决 TOFU 问题,Go 官方设立了 sum.golang.org,一个记录全球所有公开 Go 模块版本哈希的中央校验和数据库。
但是,新的问题随之而来:如果连 Google 运营的这个中央数据库也被黑客攻破了呢?或者如果服务器故意向特定用户返回伪造的哈希值呢?
Go 团队的答案是:设计一个“多疑的客户端”。go 命令绝不盲目信任 sumdb 服务器返回的任何一条数据,而是要求服务器提供严密的数学证明。这套证明体系的基石,就是 透明日志(Transparent Logs)。
透明日志本质上是一个只追加(Append-Only)的防篡改数据结构,其核心是默克尔树(Merkle Tree)。在 sumdb/tlog/tlog.go 源码中,我们可以清晰地看到这棵树的构建过程。
透明日志将每一个模块的版本和哈希记录作为树的叶子节点。两两相邻的叶子节点哈希相加,生成父节点的哈希,层层向上,最终生成一个唯一的树根哈希(Tree Hash)。
为了防止经典的“第二原像攻击”(即攻击者构造一个叶子节点,使其哈希值碰巧等于某个内部节点的哈希值),tlog.go 在计算哈希时进行了极其严谨的域隔离(Domain Separation)前缀设计:
// 源码文件:sumdb/tlog/tlog.go
// 计算叶子节点(Record)哈希,前缀加 0x00
func RecordHash(data []byte) Hash {
h := sha256.New()
h.Write([]byte{0x00}) // RFC 6962: SHA256(0x00 || data)
h.Write(data)
// ...
}
// 计算内部节点哈希,前缀加 0x01
func NodeHash(left, right Hash) Hash {
var buf[1 + HashSize + HashSize]byte
buf[0] = 0x01 // RFC 6962: SHA256(0x01 || left || right)
copy(buf[1:], left[:])
copy(buf[1+HashSize:], right[:])
return sha256.Sum256(buf[:])
}
这个唯一的树根哈希代表了此刻全球 Go 生态所有公开包的完整历史状态。任何一个历史字节的篡改,都会导致根哈希发生雪崩式的变化。
当客户端向 sumdb 查询 rsc.io/quote@v1.5.2 时,服务器不仅返回记录,还会返回一条证明路径。
![]()
如上图所示,如果客户端想验证黄绿色的 Record 1 是否在树中,服务器只需提供旁边黄色的节点(Record 0 和 Node Hash L1-1)的哈希值。客户端在本地通过 NodeHash(RecordHash(Record 1), Record 0) 计算出 N1,再与 N2 结合计算出 Root。
如果计算出的 Root 与官方公布的根哈希一致,这在数学上就绝对证明了:该模块的哈希确实被官方收录,绝无伪造可能。 这一过程的时间复杂度仅为 O(log N)。
这是防止服务器“撒谎”的终极杀手锏。
如果 sumdb 服务器被黑客控制,黑客针对“受害者 A”返回一棵包含后门记录的“伪造树”,而对其他用户返回“正常树”(这种攻击被称为 Fork Attack)。该如何防范?
客户端在每次成功通信后,都会将当前的树大小(N)和根哈希(T)持久化在本地(通常位于 $GOPATH/pkg/sumdb/sum.golang.org/latest)。
下一次通信时,如果服务器声称树长大了(规模变为 N’,新哈希为 T’),客户端会要求服务器出具一致性证明。客户端通过比对两条证明路径,在本地强校验:新的树 T’,是否完美且完整地包含了旧树 T 的所有历史记录?
如果历史被重写,一致性校验必将失败。客户端会立即阻断构建,并抛出带有详细密码学证据的 SECURITY ERROR。
理论虽然完美,但落地面临着巨大的工程挑战:全球几百万 Go 开发者,每次 go get 都要向中央服务器请求动态计算的 Merkle Tree 证明,服务器算力绝对会瞬间崩溃。此外,动态生成的证明根本无法被 CDN 缓存。
为了解决这个问题,Russ Cox 引入了一项堪称艺术的设计:日志瓦片化(Tiling a Log)。
参考 Google Maps 将全球地图切分为静态切片(Tiles)的思路,sumdb 没有提供动态计算的证明 API,而是将整棵庞大的哈希树,按照固定的高度(默认 Height = 8)切分成了无数的静态“瓦片”。
![]()
在 sumdb/tlog/tile.go 源码中,每个 Tile 都有一个三维坐标 tile/H/L/N:
瓦片化带来的工程收益是巨大的:
当我们在命令行敲下 go get 时,底层到底发生了什么?翻开 sumdb/client.go 的源码,我们可以看到严密的防御逻辑:
获取最新签名树头:
客户端首先请求 /latest 接口。服务器返回由官方 Ed25519 密钥签名的树大小和根哈希。
客户端使用 sumdb/note 包(基于加盐哈希和 Base64)验证签名的合法性。
查询模块位置(Lookup):
执行 Client.Lookup(“rsc.io/quote”, “v1.5.2″)。向服务器请求 /lookup/rsc.io/quote@v1.5.2,服务器返回该模块在日志中的记录编号(Record ID)以及该记录的文本内容。
下载瓦片并行验证(Read and Verify Tiles):
客户端利用记录编号,推算出需要哪些瓦片才能构建从叶子节点到根哈希的证明路径(在 tileHashReader.ReadHashes 中实现)。
客户端并行下载缺失的静态瓦片文件 /tile/8/0/x001 等,并在本地执行 tlog.ProveRecord 和 tlog.ProveTree 进行存在性和一致性校验。
安全落地(Merge & Write):
// 源码片段:sumdb/client.go
if err := c.checkRecord(id, text); err != nil {
return cached{nil, err} // 存在性校验失败
}
if err := c.mergeLatest(treeMsg); err != nil {
return cached{nil, err} // 一致性校验失败 (防 Fork 攻击)
}
只有当数学证明完全成立时,go 命令才会将该模块的哈希写入你本地项目的 go.sum 文件中,并将其缓存,供后续使用。
透明日志机制并非 Go 语言独享,它是现代数字信任体系的基石架构。除了保护 Go 的供应链,它还在以下领域发挥着无可替代的作用:
在这个充满漏洞和供应链投毒的黑暗森林里,Go 语言之所以能成为安全开发的避风港,绝不仅仅是因为静态类型或内存安全。
sumdb 的设计展现了 Go 核心团队的高超的工程智慧:他们不强求开发者去信任任何外部服务器(甚至是他们自己运营的服务器),而是将信任建立在严密的代码、数学逻辑和密码学证明之上。
当你的屏幕上飞速闪过 go get 的进度条,并在零点几秒内完成构建时,请记住:你的本地机器刚刚与全球见证的密码学巨树完成了一次无声的灵魂校验。
你信任你的 Proxy 吗?
密码学的魅力在于“不信任任何人,只信任数学”。在你的日常开发中,你是否曾遭遇过依赖包版本冲突或疑似被“掉包”的经历?你认为透明日志这种机制,是否应该成为所有包管理器的标配?
欢迎在评论区分享你的供应链安全感悟!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。

你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。

© 2026, bigwhite. 版权所有.

本文永久链接 – https://tonybai.com/2026/03/11/standard-library-is-part-of-the-go-success
大家好,我是Tony Bai。
在现代软件开发中,我们似乎已经患上了一种名为“依赖上瘾”的绝症。
新建一个项目,你敲下的第一行命令大概率不是写业务逻辑,而是 npm install、cargo add 或者 pip install。我们潜意识里已经默认:语言本身只提供最基础的砖块,稍微高级一点的功能(比如发起个网络请求、解析个 JSON),都必须去浩如烟海的开源社区里“淘金”。
但这种习以为常的生态繁荣,真的是一件好事吗?
近日,在 Reddit 的 r/golang 社区,一个题为《标准库是 Go 成功的一部分吗?》的帖子,像一颗深水炸弹,炸出了无数程序员对于“依赖地狱(Dependency Hell)”的疯狂吐槽。
发帖人分享了一个极其真实且让人啼笑皆非的日常小故事:
他想写一个微型应用,目的非常单纯——从家里的太阳能光伏电池 Web 服务器上抓取一个 JSON 文件,解析出来,然后把能源数据显示在屏幕上。
他首先用 Go 语言写了一版。极其丝滑,仅靠自带的标准库就搞定了网络请求和 JSON 解析,编译出一个干干净净的二进制文件,直接跑通。
几天后,他闲来无事,想测试一下其他编译型语言:
这个看似不起眼的小实验,无意间撕开了现代软件工程一块遮羞布,也揭示了 Go 语言在后端开发中一个极其“霸道”、却常被新手低估的绝对优势:降维打击般的标准库(Standard Library)。
今天,我们就来深度剖析一下,为什么大量工程师越来越偏爱 Go 这种“零依赖”的极简哲学。

在很多主打“生态繁荣”的编程语言中,标准库被视为一种“最小公集”。语言的设计者把高级特性推给社区,美其名曰“保持语言的核心轻量”。
这听起来很美好,但在实际的商业工程中,它带来了一个极其消耗心智的隐性成本:决策疲劳(Decision Fatigue)。
想象一下,当你用 Node.js 或者 Rust 仅仅需要发起一个异步 HTTP 请求时,你需要经历怎样痛苦的内心戏?

而在 Go 中,这一切内耗根本不存在。
正如 Reddit 帖子评论区一位资深 Gopher 一针见血指出的:
“Go 的成功不仅在于它轻量、简单、易学,还在于它自带了一个庞大且极其优秀的标准库。因此,在开始处理每个微小的子任务之前,你不需要去评估一堆第三方库。”
Go 的哲学是“开箱即用”。net/http 就在那里,encoding/json(以及json/v2) 就在那里。它直接消灭了你在技术选型上的无意义内耗,让你可以把 100% 的脑力,全部砸在能给公司赚钱的业务逻辑上。
看到这里,Python 开发者可能会不服气:“Python 也有非常丰富的标准库啊,我们叫 Batteries included(自带电池)!”
没错,Python 的标准库确实庞大,但问题在于:它好用吗?它能直接扛高并发吗?
Python 自带的 urllib API 设计得极其反人类,导致全网的 Python 教程都在教你第一时间去 pip install requests。
如果你提供的标准库只是一个“能跑就行”的玩具,开发者迟早还是要逃向第三方库的怀抱。其他语言的标准库,大多只敢称自己是“开发级(Dev-level)”的替代品。
但 Go 的标准库,是真正意义上的“生产级(Production-ready)”。
以 Go 的 net/http 为例。它不仅仅是能发个请求那么简单,它底层直接内置了工业级的连接池、自动支持 HTTP/2、拥有极其精细的超时控制,并且在骨子里完美契合了 Go 的 Goroutine 并发模型。
在这个世界上,有无数估值数十亿美元的独角兽公司,他们的高并发微服务底层,没有套 Nginx,没有套 Tomcat 或 Gunicorn,而是直接裸跑在 Go 标准库的 net/http.Server 之上! 这在其他语言的生态里,简直是不可想象的。
同样,Go 的 crypto 包也不是随便拼凑的开源算法,它是由谷歌著名的密码学家亲自操刀设计和维护的。它被全球安全界公认为是业界最安全、最难被开发者“误用”的密码学实现之一。
在现代软件工程中,有一句极其沉重的话:“依赖即债务”。
你想要一个香蕉,但开源社区给你的是一只拿着香蕉的大猩猩,以及大猩猩背后的一整片热带雨林。你敲下的每一个 npm install,都在把公司的核心系统暴露给未知的风险。
前几年的 Java Log4j 史诗级漏洞事件,以及三天两头上头条的 NPM 恶意投毒、删库跑路事件(比如著名的 left-pad 事件),给全行业上了血淋淋的一课。当你引入一个计算日期的第三方包时,它可能又间接依赖了 50 个你闻所未闻的子依赖,其中哪怕有一个包的作者被黑客盗了号,你的服务器底裤就被看穿了。
发帖的楼主深刻地探讨了这一点:
“保持项目没有外部依赖,让维护变得更加容易。开发者经常忘记,向项目中添加一个依赖,就增加了一份审查恶意代码的责任。”
Go 强大的标准库,为你提供了一道天然的“供应链安全护城河”。
像前面提到的“拉取光伏面板 JSON 并解析”这样的任务,在 Go 中是零外部依赖的。
零外部依赖,就意味着零第三方供应链风险。这种“自给自足”的底气,在如今极度苛求数据安全、合规性审计的企业级开发中,绝对是降维打击般的加分项。
除了宏观的网络和并发处理,Go 的标准库在极其底层、却又极其折磨人的领域,展现出了极其深厚的内功。
熟悉 C/C++ 的老兵一定懂得,在底层处理多语言编码(locales)和宽字符(wide chars)是一场怎样的噩梦。而 Go 的标准库原生且完美地接纳了 UTF-8。从 strings 包到 unicode/utf8,再到字符串底层极其优雅的字节切片(Byte Slice)设计,让多语言文本处理变得如同呼吸一般自然。
更不用提 Go 那近乎魔法的跨平台交叉编译。
Go 的标准库(如 os、path/filepath)对底层操作系统的 API 差异进行了极致的抽象。作为开发者,你可以在一台舒舒服服的 Mac 上写代码,只需加一个环境变量 GOOS=linux,就能瞬间利用标准库编译出一个毫无平台依赖的静态二进制文件,直接扔到 Ubuntu 服务器上完美运行。
这种抽象能力,让一切第三方跨平台打包工具都显得极其多余。
最后,Go 的标准库之所以被几百万开发者绝对信任,离不开 Go 团队当年立下的一个近乎严苛的誓言:Go 1 兼容性保证(Go 1 Compatibility Guarantee)。
这意味着什么?这意味着你在 2012 年基于 Go 1.0 标准库写下的一段处理 HTTP 的代码,在今天最新的 Go 1.26 编译器下,不仅能一字不改地编译通过,而且运行行为保持绝对一致!
在任何其他语言的开源生态中,很多曾经辉煌一时的第三方霸主库,都会因为作者的精力衰退、兴趣转移或资金断裂,最终走向被废弃(Deprecated)的命运。当你依赖的库停止维护时,你的整个项目组都要被迫进行痛苦的代码大重构。
开源世界充满了不确定性,而 Go 的标准库,背后站着的是谷歌顶级的工程团队,拥有与这门语言同等漫长的寿命周期。
这种确定性的安全感,是任何高星的第三方库都无法给予你的。

我们常说,Go 是一门为“大规模软件工程”而生的语言。
这种工程基因,不仅仅体现在它的极速编译和极简语法上,更深深地烙印在它那套“霸道”的标准库里。
它逼着你放下对“奇技淫巧”的追求,逼着你放弃花里胡哨的第三方依赖,回归到用最稳固的基石,构建最健壮的系统的正道上来。
当然,Go 的标准库并不完美,比如千呼万唤始出来的官方 UUID 至今仍让社区望眼欲穿。但在构建现代云原生应用、微服务 API 和数据网关时,它依然交出了一份近乎满分的答卷。
它告诉了所有高级架构师一个硬道理:最好的工具,是让你感受不到工具存在的工具;最强大的库,是让你根本不用去寻找库的库。
今日互动吐槽
你在平时的开发中,被哪个第三方库(依赖地狱)狠狠坑过?或者你觉得 Go 的标准库里,现在最缺哪个核心功能?
欢迎在评论区开喷吐槽!
认知跃迁:读懂底层骨架,才能驾驭“降维打击”
很多写了几年 CRUD 的朋友问我:“Tony 老师,既然 Go 的标准库这么牛,那我只要背熟标准库的 API 是不是就能进大厂了?”
大错特错。会调 API 只是技工,看懂底层设计才是架构师。
Go 语言“少即是多”的工程美学,其精髓并不在于它提供了什么函数,而在于它是如何用极简的代码,实现千万级并发与跨平台抽象的。比如 net/http 背后那精妙的 Goroutine 调度模型,比如 context 是如何控制全局超时的。
如果你渴望突破技术瓶颈,不再满足于做一个“只会调包的熟练工”,而是想从骨子里吃透 Go 的系统级设计思维——
我的全新极客时间专栏 《Go语言进阶课》正是为你量身打造。
在这 30+ 讲硬核内容中,我将带你剥开语法糖,深入标准库与并发模型的底层骨架,锻造你编写高可用、生产级微服务的顶级工程实践能力。
目标只有一个:助你完成从“Go 熟练工”到“能做架构决策的 Go 专家”的蜕变!
扫描下方二维码,加入专栏,让我们一起深挖这门语言背后的“降维打击”之力。

还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

本文永久链接 – https://tonybai.com/2026/03/09/a-decade-of-docker-containers
大家好,我是Tony Bai。
2013年,当 Solomon Hykes 在 PyCon 上首次演示 Docker 时,他用一种名为“容器”的魔法,将开发者从依赖地狱中解救了出来。转眼间,十三年过去了。今天,Docker Hub 托管着超过 1400 万个镜像,每月拉取量超 110 亿次。它不仅是 Kubernetes 的基石,更是从流媒体到太空探索的底层引擎。
表面上看,Docker 只是简单的 build, push, run。但在这极简的开发者体验背后,是横跨操作系统、虚拟化、网络架构和硬件驱动的深水区。近日,Docker 领域的三位重量级人物(Anil Madhavapeddy, David J. Scott, Justin Cormack)在ACM通信上联合发表了万字长文《A Decade of Docker Containers》,首次全景式披露了 Docker 十年来的核心技术挑战与架构演进。
本文将带你一起解读这篇重磅论文,了解一下Docker这十年来背后不为人知的精彩故事。
在 2000 年代初,配置一台服务器是一场噩梦,你需要手动解决各种动态库的依赖冲突。到了 2010 年代,云计算兴起,主流的隔离方案是虚拟机(VM)。
虚拟机虽然隔离性好,但极其笨重。它需要完整的客户机内核、独立的虚拟磁盘和重复的内存开销。如果你只想在一台机器上跑十个轻量级微服务,虚拟机显然不是最优解。
另一方面,早期的 Linux 提供了一些原生隔离工具(如 1978 年引入的 chroot),但它们无法解决网络端口冲突等问题。像 Nix 和 Guix 这样的系统试图通过重组文件目录来解决依赖问题,但这要求重写所有的软件打包方式,门槛极高。
Docker 的天才之处,在于它找到了一种“务实的妥协”:利用 Linux Namespaces。
Namespaces(命名空间)并非 Docker 发明。自 2001 年起,Linux 内核逐步引入了 Mount(文件系统)、IPC、Network 等七种命名空间。它们允许在共享同一个系统内核的前提下,让每个进程拥有独立的资源视图。

如上图所示,通过 Mount Namespace,容器 A 看到的是 /alice/etc/passwd,而容器 B 看到的是 /bob/etc/passwd,但它们都以为自己访问的是根目录下的 /etc/passwd。这种机制的开销远低于启动一个完整的 Linux VM,通常只需不到一秒即可完成环境隔离。
Docker 将这些原本低级且晦涩的内核 API 进行了高层封装,结合基于联合文件系统(如 overlayfs)的层级镜像(Layered Images)机制,彻底奠定了容器技术的物理基础。
Docker守护进程最初是一个单体程序,但在 2015 年左右,Docker团队将其拆分为如下图所示的 7 个专用组件。第一个组件 buildkit 负责组装文件系统镜像,然后 containerd 管理将这些镜像实例化为运行中的容器,并配置相关的网络和存储资源。

Docker 诞生之初有一个致命的局限:它只能在 Linux 内核上运行。
但在现实世界中,绝大多数开发者使用的是 macOS 或 Windows 笔记本。为了让这些开发者能在本地顺畅地构建和测试容器,Docker 团队面临着其历史上最大的工程挑战之一:如何在非 Linux 宿主机上,提供与 Linux 原生体验一致的 docker run 和 localhost 访问?
最初,开发者必须使用 VirtualBox 这样的重量级独立虚拟机来运行 Linux。这种体验是割裂的:你需要管理虚拟机的生命周期,网络端口映射极其繁琐。
Docker 团队决定重构架构。他们采用了一种被称为“库虚拟机监控器(Library VMM)”的先进理念,结合了他们在 Unikernel 领域的研究成果。

如上图所示,在 macOS 上,Docker 开发了 HyperKit,利用 Apple 原生的 Hypervisor 框架,将一个极简的 Linux 虚拟机(基于定制的 LinuxKit 操作系统)直接嵌入到了 Docker 桌面端应用进程中。开发者在终端敲下的 docker build 命令,会通过隐形的 AF_VSOCK (虚拟套接字) 直接发送到这个嵌入式 Linux 内核中的 dockerd 守护进程。
这种设计使得虚拟机变得“隐形”,实现了无缝的客户端-服务器交互。
有了隐形虚拟机,更大的麻烦来了——网络联通性。
传统的桥接网络(Bridged Network)在企业环境中经常被防火墙和安全软件拦截,因为这种网络流量看起来像是绕过了宿主机网络栈的“未知进程”。同时,开发者希望在容器内监听 80 端口后,能在 Mac 的浏览器里直接通过 localhost:80 访问。
为了解决这个问题,Docker 团队做出了一个疯狂的决定:他们复活了一个诞生于 1990 年代中期、最初用于 Palm Pilot PDA 拨号上网的古老工具——SLIRP。

如上图所示,Docker 团队用 OCaml 语言重写了一个用户态的 TCP/IP 协议栈(命名为 vpnkit)。
这样一来,从企业防火墙的角度看,所有的网络请求都像是 Docker Desktop 这个普通应用程序发出的,从而完美绕过了安全拦截。这项被称为 SLIRP 的古老技术,在云原生时代焕发了第二春,将企业用户的网络 Bug 报告减少了 99% 以上。
不仅是网络,存储同样面临跨系统的挑战。Linux 的“绑定挂载(Bind Mount)”无法直接跨操作系统工作。Docker 利用 virtio-fs 协议,将 Mac/Windows 的文件系统操作转换为 FUSE 请求发送给宿主机,实现了代码热重载。
而在 Windows 阵营,随着 2018 年微软推出 WSL2(Windows Subsystem for Linux 2),情况迎来了转机。WSL2 本质上是在后台运行了一个高度优化的轻量级 Linux 虚拟机。Docker 顺势而为,将 Docker 引擎直接集成到 WSL2 中,彻底消除了早期使用 Hyper-V 时的性能损耗和体验割裂。
进入 2020 年代后,基础设施硬件发生了翻天覆地的变化。Docker 的技术版图也被迫(且成功地)向异构计算延伸。
随着 Apple M 系列芯片和 AWS Graviton 架构的普及,开发者不再局限于 x86 (AMD64) 架构。Docker 必须支持“一次构建,多架构分发”。
除了在 OCI 镜像规范中引入“多架构清单(Multi-arch Manifests)”外,Docker 还利用了 Linux 的一个冷门特性 binfmt_misc,结合 QEMU 模拟器。这使得开发者在 Mac M1(ARM)上构建镜像时,遇到 x86 的二进制指令,可以透明地通过 QEMU 翻译执行。虽然在构建阶段有性能损耗,但这完美解决了交叉编译的噩梦。
随着安全要求的提高,机密计算(Confidential Computing)成为热门。可信执行环境(TEE,如 Intel SGX 或 AMD SEV)允许在内存中创建一个被硬件加密的飞地(Enclave),甚至连宿主机操作系统都无法窥探其中的数据。
由于配置 TEE 的复杂度极高(相当于在里面启动一个微型内核),Docker 将其客户端-服务器架构发挥到了极致。开发者可以在本地使用 Docker CLI,将加密信息通过安全的 Socket 转发,直接部署并管理运行在云端 TEE 环境中的容器,兼顾了本地开发的便利性和云端的极致安全。
2023 年以来,AI 工作负载的爆发给容器带来了全新的难题:GPU 强绑定。
Docker 的初衷是解耦底层的硬件和系统,但 GPU 驱动却要求容器内的用户态动态库(User-space libraries)与宿主机的内核态驱动(Kernel driver)必须严格版本匹配。
为了解决这个矛盾,Docker 从 2023 年起全面支持了 容器设备接口(Container Device Interface, CDI)。这允许在容器启动时,动态地将特定 GPU 的设备文件和动态库“绑定挂载”到容器中,并重新生成链接器缓存(ld.so cache)。
然而,论文作者也坦言,目前的解决方案远未完美。GPU 的标准化程度远不及 CPU,针对 Nvidia GPU 编写的应用容器,依然无法在 Apple 的 M 系列 GPU 上无缝运行。硬件虚拟化和指令集翻译在 GPU 领域仍是一个巨大的挑战,整个社区仍在寻找更通用的抽象层(如 Triton 等中间语言)。

时间来到 2026 年,软件开发的范式正在被 AI 重塑。
如图所示,今天的开发者工作流(Workflow)已经不仅仅是 build 和 run。它融合了持续部署、云端卸载(Docker Build Cloud)、以及运行在容器内的 AI 智能体(Agentic Coding)。
未来的AI 智能体将通过 MCP(模型上下文协议,Model Context Protocol)直接调用容器内的工具和环境进行代码的编写、测试和调试。在这个过程中,Docker 扮演了一个“隐形的安全沙箱”。它必须足够轻量,以便 AI Agent 瞬间启动成百上千个测试环境;又必须足够安全,防止 AI 生成的未知代码破坏宿主机甚至横向渗透网络。
回望这十年,Docker 的成功绝不是偶然。它不是一项单一的颠覆性发明,而是一系列持续不断的、精妙的系统工程组合拳。
从最初利用 Linux Namespaces 寻找轻量级虚拟化的平衡点,到为了征服 macOS 和 Windows 桌面端而重构底层虚拟化和网络协议,再到如今积极适配 ARM、TEE 和 GPU 等异构硬件,Docker 始终在做一件事:为开发者屏蔽掉底层基础设施的混乱,提供一个统一、优雅、且安全的“集装箱”。
在不可预测的 AI 时代,底层的复杂性只会呈指数级上升。而我们需要像 Docker 这样久经考验的基础设施,在幕后默默地为每一次“创新”提供稳固的地基。
正如论文作者所言:“如果说我们有一个终极目标,那就是让 Docker 成为一个隐形的伴侣。你看不见它,但它能让你更快、更享受地交付代码。”
资料链接:
你的第一个容器跑的是什么?
回望十年,Docker 已经从一个“玩具”变成了世界的底座。你还记得自己第一次运行 docker run 时的感受吗?在你的开发流中,Docker 解决过的最让你难忘的 Bug 是什么?
欢迎在评论区分享你的 Docker 记忆或对“AI 容器”的脑洞!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!
想系统学习Go,构建扎实的知识体系?
我的新书《Go语言第一课》是你的首选。源自2.4万人好评的极客时间专栏,内容全面升级,同步至Go 1.24。首发期有专属五折优惠,不到40元即可入手,扫码即可拥有这本300页的Go语言入门宝典,即刻开启你的Go语言高效学习之旅!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

本文永久链接 – https://tonybai.com/2026/02/09/go-immutable-types-8-year-dormant-proposal-awakened
大家好,我是Tony Bai。
2026 年 2 月 4 日,在 Go 语言规范团队的最新一次“语言变更评审会议”纪要中,一个尘封已久的 Issue 赫然在列:proposal: spec: immutable type qualifier #27975。

这个提案最初提交于 2018 年,那是“Towards Go 2”口号喊得最响亮的年代。当时的 Go 社区正沉浸在对泛型、错误处理和不可变性的热烈讨论中。然而,随着泛型的落地,关于不可变性的声音似乎逐渐微弱。
如今,这个提案被重新摆上台面,是否意味着 Go 语言在完成泛型这一宏大叙事后,终于要向“数据竞争”和“防御性编程”这两个顽疾开刀了?
今天,我们就来看看复盘这份长达 8 年的提案,剖析一下“不可变性”对 Go 意味着什么,以及它面临的巨大挑战。

在 Go 1.x 的世界里,我们为了保证数据的安全性,往往需要付出高昂的代价。
假设你有一个包含敏感配置的结构体,你想把它暴露给其他包,但又不希望它被修改:
type Config struct {
Servers []string
// ...
}
// 现在的做法:为了安全,必须返回拷贝
func (c *Config) GetServers() []string {
out := make([]string, len(c.Servers))
copy(out, c.Servers)
return out
}
这种“防御性拷贝”带来了两个严重问题:
正如提案作者 romshark 所言:“我们现在的做法,要么是不安全的(直接返回指针),要么是低效的(防御性拷贝)。”
而不可变类型(Immutable Types)的引入,旨在提供第三种选择:既安全,又高效。
NO.27975 提案的核心思想非常直接:引入一个新的类型限定符(最初建议重载 const,后倾向于引入immut ),让编译器来强制执行“只读”契约。
想象一下这样的 Go 代码:
// 定义一个只读的切片类型
func ProcessData(data immut []byte) {
// 读取是 OK 的
fmt.Println(data[0])
// 修改是编译错误的!
// data[0] = 'X' // Compile Error: cannot assign to immutable type
}
在这个愿景中,不可变性是类型系统的一部分。
这看起来很像 Rust 的 & (immutable reference) 和 &mut (mutable reference),或者 C++ 的 const。但 Go 社区的讨论,揭示了这背后远比想象中复杂的工程难题。
这份提案下的讨论区,堪称 Go 语言设计哲学的“修罗场”。Ian Lance Taylor, Rob Pike 等核心大佬纷纷下场,与社区开发者展开了长达数年的拉锯战。
这是 Ian Lance Taylor 最担心的问题。如果你把一个底层函数的参数标记为 immut,那么所有调用它的上层函数,为了传递这个参数,往往也需要把自己的变量标记为 immut。
这种“传染性”会导致代码库中充斥着 immut 关键字。更糟糕的是,如果你以后需要修改底层函数,让它对数据进行一点点修改,你需要修改整个调用链上的类型签名。这在 C++ 中被称为“const correctness”的噩梦。
bcmills 提出了一个极其尖锐的兼容性问题:现有的 io.Writer 接口定义是 Write(p []byte)。
这似乎陷入了一个死循环:要么破坏所有现有代码,要么新特性无法与标准库兼容。
jimmyfrasche 指出了一个微妙的语义陷阱。
在 C++ 中,const T& 只是意味着“我不可以通过这个引用去修改它”(Read-only View),并不意味着“这个数据本身不会变”。因为可能还有另一个非 const 的指针指向同一块内存,并且正在修改它。
如果是前者(只读视图),它无法解决并发安全问题(数据竞争依然存在)。如果是后者(真正的内容不可变),那么 Go 必须引入一套类似 Rust 的所有权(Ownership)系统来保证“没有其他人在写”。这对于 Go 来说,改动太大了。
既然困难重重,为何在 2026 年的今天,这个提案又被翻出来了?
我认为有几个关键因素:
首先,泛型的“降维打击”。以权限泛型(Permission Genericity)化解兼容性死结。
前面提到了,在 Go 1.18 泛型落地之前,不可变性提案面临着一个被称为“io.Writer 陷阱”的致命矛盾:如果将 io.Writer.Write(p []byte) 改为接受 immut []byte,将导致全世界现有的实现代码因签名不匹配而崩溃;如果不改,只读数据又无法直接传入。
泛型的引入为这一难题提供了全新的解题思路。通过类型约束中的联合类型(Union Types),我们可以实现所谓的“权限泛型性”。这意味着 mutability(可变性)不再是一个硬编码的死结,而可以作为一个类型参数(Type Parameter)来处理。
想象一下,我们可以利用泛型约束定义一个覆盖“可变”与“不可变”两种状态的超集:~[]byte | ~immut []byte。下面是在这种模式下的一个泛型化的Writer接口:
// 这是一个设想中的“权限泛型”接口
type Writer[T ~[]byte | ~immut []byte] interface {
Write(p T) (n int, err error)
}
泛型化的 Write[T ~[]byte | ~immut []byte](p T) 方法,在逻辑上可以产生如下影响:
其次,性能压力的倒逼。
随着 Go 在高性能领域的应用越来越深(如数据库、AI 推理),对于“零拷贝”的需求越来越强烈。能够安全地共享内存,是提升性能的关键。
最后是安全性需求。
在并发编程中,数据竞争依然是 Go 程序的头号杀手。go vet 和 race detector 虽然好用,但它们是运行时的、滞后的。社区渴望一种编译期的保证。
虽然完全的“不可变类型”可能依然很难落地,但我们可以期待一些更温和的替代方案:
NO.27975 提案的“复活”,是一个信号。它表明 Go 团队并没有满足于现状,依然在探索如何在保持“简单”这一核心价值观的同时,赋予语言更强的表达力和安全性。
无论最终结果如何,这都是 Go 语言演进史上值得铭记的一笔。它提醒我们:在软件工程中,没有免费的午餐,每一个简单的特性背后,都是无数次复杂的权衡。
你支持引入 immut 吗?
面对“性能”与“简单”的博弈,你是否愿意为了消除数据竞争而接受 immut 带来的“类型传染”?在你的项目中,是否也曾深受“防御性”的性能困扰?
欢迎在评论区分享你的看法,或者聊聊你最期待的 Go 演进方向!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

本文永久链接 – https://tonybai.com/2026/01/28/go-standard-library-vendor-std-cmd-dependency-management
大家好,我是Tony Bai。
我们都知道,Go 推荐使用 Go Modules 来管理依赖。但在 Go 源码树的最深处,隐藏着一个鲜为人知的秘密:Go 标准库 (std) 和工具链 (cmd) 竟然依然在使用 vendor 目录来管理它们的外部依赖。
为什么官方要“反其道而行之”?当你在 crypto/tls 中引入 golang.org/x/crypto 时,底层到底发生了什么?今天,让我们潜入 $GOROOT/src,解密一下 std 和 cmd 这两个特殊模块的依赖管理之道。

在 Go 的源码树中,其实存在着两个特殊的模块(module),它们定义了 Go 核心代码的依赖边界:
看看 当前 Go 主干 (Go 1.27开发分支)中的 src/go.mod:
module std
go 1.27
require (
golang.org/x/crypto v0.47.1-0.20260113154411-7d0074ccc6f1
golang.org/x/net v0.49.1-0.20260122225915-f2078620ee33
)
require (
golang.org/x/sys v0.40.1-0.20260116220947-d25a7aaff8c2 // indirect
golang.org/x/text v0.33.1-0.20260122225119-3264de9174be // indirect
)
当前最新cmd/go.mod内容如下:
module cmd
go 1.27
require (
github.com/google/pprof v0.0.0-20260115054156-294ebfa9ad83
golang.org/x/arch v0.23.1-0.20260109160903-657d90bd6695
golang.org/x/build v0.0.0-20260122183339-3ba88df37c64
golang.org/x/mod v0.32.0
golang.org/x/sync v0.19.0
golang.org/x/sys v0.40.1-0.20260116220947-d25a7aaff8c2
golang.org/x/telemetry v0.0.0-20260116145544-c6413dc483f5
golang.org/x/term v0.39.0
golang.org/x/tools v0.41.1-0.20260122210857-a60613f0795e
)
require (
github.com/ianlancetaylor/demangle v0.0.0-20250417193237-f615e6bd150b // indirect
golang.org/x/text v0.33.1-0.20260122225119-3264de9174be // indirect
rsc.io/markdown v0.0.0-20240306144322-0bf8f97ee8ef // indirect
)
这意味着,虽然标准库被认为是“零依赖”的基石,但实际上它在内部复用了大量 golang.org/x 下的高质量代码。
既然用了 Module,为什么 std 和 cmd 还要维护 src/vendor 和 src/cmd/vendor 目录?
这就涉及到了 Go 编译器的底层机制。当标准库内部的代码引入外部包时,发生了一个神奇的重命名 (Renaming) 过程。
当 crypto/tls (在 std 模块中) 导入 golang.org/x/crypto/cryptobyte 时,编译器并不会去 Module 缓存里找,而是将其解析为:
vendor/golang.org/x/crypto/cryptobyte
这样做有两个关键目的:
维护这套庞大的依赖系统并非易事。Go 团队在 src/README.vendor 中记录了一套严格的工程流程:
bash
cd src # 或者 cd src/cmd
go get golang.org/x/net@master # 更新依赖
go mod tidy # 清理 go.mod
go mod vendor # 更新 vendor 目录
go test cmd/internal/moddeps # 运行一致性检查Go 官方对 std 和 cmd 的管理方式,其实是一种“单体仓库 (Monorepo) + 依赖固化”的最佳实践。
下次当你感叹 Go 标准库的稳定与强大时,别忘了这背后,有一套精密设计的 Vendor 机制在默默支撑着这一切。
参考资料:https://github.com/golang/go/blob/master/src/README.vendor
你的“Vendor”情结
虽然 Go Modules 已经统治了世界,但 vendor 依然在标准库和许多企业级项目中发光发热。在你的项目中,你还在使用 vendor 目录吗?是
为了离线构建,还是为了像标准库一样实现“依赖固化”?
欢迎在评论区分享你的依赖管理策略!让我们一起探讨 Go 工程化的最佳实践。
如果这篇文章揭开了你心中关于标准库的谜团,别忘了点个【赞】和【在看】,并转发给身边那些爱钻研源码的朋友!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

本文永久链接 – https://tonybai.com/2026/01/19/unleashing-the-go-toolchain
大家好,我是Tony Bai。
“Go 语言以简洁著称,但在可观测性(Observability)领域,这种简洁有时却是一种负担。手动埋点、繁琐的初始化代码、版本升级带来的破坏性变更……这些都让 Gopher 们痛苦不已。

相比之下,Java 和 Python 开发者享受着“零代码修改”的自动插桩福利。Go 开发者能否拥有同样的体验?
在 GopherCon UK 2025 上,来自 DataDog 的资深工程师 Kemal Akkoyun 给出了肯定的答案。他通过挖掘 Go 工具链中一个鲜为人知的特性,不仅实现了这一目标,还将其开源为一个名为 Orchestrion 的工具。今天,就让我们一起揭秘这背后的“黑魔法”。

在 Go 中集成分布式追踪(如 OpenTelemetry),通常意味着你需要:



这种手动方式不仅效率低下,而且容易出错。如果有遗漏,追踪链路就会断裂;如果库升级,你可能需要重写大量代码。

与 Java Agent 的字节码注入或 Python 的动态装饰器不同,Go 是静态编译语言,运行时极其简单,没有虚拟机层面的“后门”可走。这似乎是一个死局。

Gopher强烈希望 Go 也能像其他语言那样,轻松实现插桩从而注入追踪(trace)能力:


Kemal 及其团队发现,Go 虽然没有运行时魔法,但在编译时却留了一扇窗:-toolexec 标志。
$go help build|grep -A6 toolexec
-toolexec 'cmd args'
a program to use to invoke toolchain programs like vet and asm.
For example, instead of running asm, the go command will run
'cmd args /path/to/asm <arguments for asm>'.
The TOOLEXEC_IMPORTPATH environment variable will be set,
matching 'go list -f {{.ImportPath}}' for the package being built.
这是一个鲜为人知的 go build 参数。它允许你指定一个程序,拦截并包装构建过程中的每一个工具调用(如 compile、link、asm 等),让你可以在真正的compile、link 等之前对Go源码文件 (以compile等命令行工具的命令行参数形式传入) 做点什么。
为了让大家直观感受 -toolexec 的作用,我们先来看一个最简单的“拦截器”示例。
假设我们写了一个名为 mytool 的小程序,它的作用仅仅是打印出它接收到的命令,然后再原样执行该命令:
// mytool.go
package main
import (
"fmt"
"os"
"os/exec"
)
func main() {
// 注意:将日志打印到 Stderr,避免干扰 go build 读取工具的标准输出(如 Build ID)
fmt.Fprintf(os.Stderr, "[Interceptor] Running: %v\n", os.Args[1:])
// 原样执行被拦截的命令
cmd := exec.Command(os.Args[1], os.Args[2:]...)
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
os.Exit(1)
}
}
现在,当我们使用 -toolexec 参数来编译一个普通的 Go 程序时:
# 先编译我们的拦截器
go build -o mytool mytool.go
# 使用拦截器来编译目标程序
go build -toolexec="./mytool" main.go // 这里的main.go只是一个"hello, world"的Go程序
你会看到类似这样的输出:
[Interceptor] Running: /usr/local/go/pkg/tool/darwin_amd64/compile -o ...
[Interceptor] Running: /usr/local/go/pkg/tool/darwin_amd64/link -o ...
看到了吗?go build 并没有直接调用编译器,而是先调用了我们的 mytool,并将真正的编译器路径和参数作为参数传给了它。之后再调用回原命令,在上面示例执行完go build -toolexec=”./mytool” main.go后,我们同样看到了编译成功后的可执行二进制文件main。
这就给了我们一个惊人的机会:既然我们拦截了编译指令,我们当然可以修改它,甚至修改它即将编译的源文件!
但是,仅仅打印几个日志、拦截一下命令,离真正的“自动插桩”还有很远的距离。要在真实复杂的 Go 项目中,安全、准确地修改成千上万行代码,同时还要处理依赖管理、缓存失效、语法兼容等棘手问题,绝非易事。
这正是 Orchestrion 登场的时刻。它不仅将 -toolexec 的潜力发挥到了极致,更将这套复杂的流程封装成了一个开箱即用的产品。
Orchestrion 是什么?
简单来说,它是 DataDog 开源的一个编译时自动插桩工具。它的名字来源于一种模仿管弦乐队声音的机械乐器(Orchestrion),寓意它能像指挥家一样,协调并增强你的代码,而无需你亲自演奏每一个音符。
有了 -toolexec 这把钥匙,Orchestrion 就开启了一场编译时的“精密手术”。这不仅仅是简单的拦截,而是一场与 Go 编译器配合默契的“双人舞”。

安装下面图片中步骤,你就可以自动完成对你的go程序的插桩:

Kemal 在演讲中展示了一个复杂的时序图,Orchestrion 的工作流远比我们想象的要精细:

精准拦截:
当 go build 启动时,Orchestrion 守在门口。它并不关心链接器(linker)或汇编器(asm),它的目光紧紧锁定在 compile 命令上。每当 Go 编译器准备编译一个包(Package),Orchestrion 就会叫停。
AST 级解析与“无损”操作:
它读取即将被编译的 .go 源文件,将其解析为 AST(抽象语法树)。
手术式注入 (Injection):
根据预定义的规则(YAML 配置),Orchestrion 开始在 AST 上动刀:
狸猫换太子:
手术完成后,Orchestrion 将修改后的 AST 重新生成为 .go 文件,保存在一个临时目录中。
最后,它修改传递给编译器的参数,将原始源文件的路径替换为这些临时文件的路径。
透明编译:
真正的 Go 编译器(compile)被唤醒,它毫不知情地编译了这些被“加料”的代码。
最终生成的二进制文件,包含了完整的、生产级的可观测性代码,而你的源代码仓库里,依然是那份清清爽爽、没有任何第三方依赖的业务逻辑。


Orchestrion 不仅仅是一个概念验证,它是 DataDog 已经在生产环境中使用的成熟工具(现已捐赠给 OpenTelemetry 社区)。它解决了一系列工程难题:
Orchestrion 引入了类似 AOP(面向切面编程) 的概念。通过 YAML 配置文件,你可以定义“切入点”(Join Points)和“建议”(Advice)。
例如,你可以定义一条规则:
* 切入点:所有调用 database/sql 包 Query 方法的地方。
* 建议:在调用前后包裹一段计时和记录代码。


Go 的许多老旧库或设计不规范的代码并没有在参数中传递 context.Context。为了在这些地方也能传递追踪 ID,Orchestrion 做了一件极其硬核的事情:它修改了 Go 的运行时(Runtime)!
通过修改 runtime.g 结构体,它引入了类似 GLS (Goroutine Local Storage) 的机制。这允许在同一个 Goroutine 的不同函数调用栈之间隐式传递上下文,彻底解决了 Context 断链的问题。虽然这听起来很危险,但在受控的编译时注入环境下,它变得可行且强大。

Orchestrion 支持通过环境变量注入。这意味着平台工程师可以构建一个包含 Orchestrion 的基础镜像,只需要在 CI/CD 流水线中设置几个环境变量,就可以让所有基于该镜像构建的 Go 应用自动获得可观测性能力,而无需应用开发者修改一行代码。
DataDog 已将 Orchestrion 捐赠给 OpenTelemetry,并与阿里巴巴(其有类似的 Go 自动插桩工具)合作,共同在 OpenTelemetry Go SIG 下推进这一技术的标准化。
这意味着,未来 Go 开发者可能只需要执行类似 otel-go-instrument my-app 的命令,就能获得与 Java/Python 同等便捷的监控体验。
Kemal 的演讲不仅展示了一个工具,更展示了一种思维方式:当语言本身的特性限制了你时,不妨向下看一层,去挖掘工具链本身的潜力。
虽然“编译时注入”听起来像是一种对 Go 简洁哲学的“背叛”,但在解决大规模微服务治理、遗留代码维护等现实难题时,它无疑是一剂强有力的解药。
对于那些渴望从重复劳动中解脱出来的 Gopher 来说,这或许就是你们一直在等待的“魔法”。
你的插桩之痛
自动插桩无疑是未来的方向。在你的项目中,目前是如何处理链路追踪埋点的?是忍受手动埋点的繁琐,还是已经尝试过类似的自动化工具?你对
这种修改 AST 甚至 Runtime 的“黑魔法”持什么态度?
欢迎在评论区分享你的看法或踩坑经历! 让我们一起探索 Go 可观测性的最佳实践。
如果这篇文章为你打开了 Go 编译工具链的新大门,别忘了点个【赞】和【在看】,并转发给你的架构师朋友,让他也来学两招!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.
最近读了《征服C指针》,是一本好书。日本人写的计算机技术书籍像娓娓道来的技术博客那样,假设读者没有(或者有很少)相关的背景知识,围绕一个主题,除了介绍干巴巴的知识,还会谈自己的经验和理解,对其他的书和论点做点评,指出一些常见的谬误,这样读者可以更容易理解书里讲的东西。如果只有干巴巴的知识,那么去读维基百科就好了。但是维基百科(无论中文还是英文)的说明一般晦涩难懂,因为百科的首要目标是准确,消除歧义,而不是易于理解。而好的技术书里面会旁征博引,运用举例和比喻,用多的篇幅详细说明难懂的部分,加上作者的经验让读者知道哪些内容是经常使用的,哪些是晦涩又不常用的,哪些是可以辅以技巧理解的。这是我理解的优秀的技术书籍。比如,《流畅的 Python》就是这样一本好书,这本书不光介绍 Python 的编程知识,还有对 Python 语言设计的点评,和其他编程语言的对比,作者自己的理解和评价,读完之后对于整个编程概念的理解都会有提升。
这本书其实就不只是 C 语言的指针,还设计内存分配,C 的语法和编译器,CPU 等知识。从初学者到老手都可以从中有所收获。
另外书中对于有些概念可以给出确定的定义,而不是给出模棱两可的答案。如果永远模棱两可,那么永远都不会错,但是这种内容读起来也是浪费时间。一位得高望重的星际2游戏解说曾经说过:「专业解说要敢于下判断。」
以下是一些笔记。每一段引用都是书中的原文,引用如果不是连续的,就来自于不同的段落。非引用的格式是我的评论。
在C语言中,记录指针指向何种类型是只到编译器为止的,到了运行的时候就已经没有相关信息了。在运行时,指针的值就只是单纯的地址而已。“要从这个地址里取出哪种类型的值”这一信息只残留在编译器生成的机器码中。无论是在指针的值中,还是在指针指向的变量的内存空间中,都没有类型的信息。因此,如果把指向int的指针转换成了void*,就不可能再知道它原来是指向 int 的了。
指针的类型,主要是为了告诉编译器信息。
int hoge = 5;
void *hoge_p;
hoge_p = &hoge; <-- 不会报错
printf("%d\n", *hoge_p); /* 输出hoge_p所指向的内容 */会报错如下:
warning: dereferencing `void *' pointer error: invalid use of void expression
只告知了内存上的地址,却没有告知那里保存的是什么类型的数据,当然无法读取。
改成下面这样可以运行:
5: printf("%d\n", *(int*)hoge_p); /* 将hoge_p转换成int */这正是指针运算的特征。在 C 语言中,对指针加1 后,其地址就增加该指针所指向的类型的长度。示例程序中的 hoge_p 是指向 int 的指针,而在我的环境中 int 的长度是 4,所以对地址来说,加 1 就是前进 4 字节,加 3 就是前进 12 字节。
对指针+1,地址移动的单位是「指针所指向的类型的长度」,这个也是编译器计算的,这是指针需要类型的主要原因。
由于空指针可以确保与任何非空指针进行比较都不相等,所以经常作为返回指针的函数发生异常时的返回值使用。
例如我工作的地方位于日本名古屋市某栋大楼的 5 楼,某人爬一层楼需要 10秒,那么从地面上到 5 楼需要花费多少秒?50 秒?很遗憾,正确答案是 40秒。想必大家在中学都学过等差数列,等差数列的第 n 项等于“首项 + 公差× (n –1)”。每个都要减 1,真麻烦……此外,“1900 年代”并不是 19 世纪,它的一大半属于 20 世纪。更加复杂的情况是,2000 年不属于 21 世纪,而属于 20 世纪。这些问题分别可通过以下方式回避。把大楼里与地面等高的那层计作第 0 层把数列的首项计作第 0 项把最初的世纪计作 0 世纪,把公历最初的年份计作 0 年这种“差 1 错误”的问题在编程中经常发生。因此,普遍认为在一般情况下如果以 0 为基准编号,那么通常(并不是所有)能回避这类问题。
延伸阅读:为什么要“包含头不包含尾”?
要点
p[i] 是 *(p + i) 的简便写法。
下标运算符 [] 只有它原本的意义,与数组毫无关系。
要点
【比上面的要点更重要的要点】
但是,千万别写成那样。
在 get_word() 中使用下标运算符访问 buf 的内容,会让人觉得从 main() 传递过来的就是buf 数组。然而,这是个错觉,从 main() 传递过来的说到底只是指向 buf 的初始元素的指针。
函数传递只能传递指针而不能传递数组。即使数组和指针不同,但是在函数传递的时候,数组也会转换为指针,指向数组开头的元素。
在 C 语言中,参数全部都是通过值传递的。
即便是像全局变量那样在函数外部定义的变量,一旦加上 static,其作用域就只限定在当前源文件内。指定为 static 的变量(函数)对于其他源文件是不可见的(函数也是一样的)。
另外,对于函数(非 static 限定)和全局变量,只要名称相同,即便位于不同的源文件中,也会被当作相同的对象处理。
因此,根据操作系统及CPU的不同,需要规定不同的调用方法,这就叫作调用约定(calling convention)。本书中说明的调用方法是在x86系列处理器中被称为cdecl的调用约定。该方法中所有的参数都通过压栈的方式进行传递。
malloc() 会遍历链表,搜寻空块,若该块大小足够,就将其分割出来,做成使用中的块,并向应用程序返回紧邻管理区域的下一个地址。free() 会改写管理区域的标志,将该块置为空块,如果上下有空块,就顺便将它们合并成一个块。这是为了防止块碎片化。 这种操作称为 coalescing。当没有足够大的空块满足 malloc() 的要求时,就向操作系统请求(在 UNIX 中需要通过 brk()系统调用)扩充内存空间。
补充
Valgrind正如前面多次提到的那样,与动态内存分配相关的Bug往往出现在距离它被发现的位置很远的地方,因此调试非常困难。在Linux上可以使用Valgrind工具追踪这类Bug。Valgrind工具用于检测对malloc()分配的内存空间越界读写、忘记free()(内存泄漏)或者对同一块内存空间多次free()这类问题。
如果运气好,标准库 glibc 也可以为我们检测出这个问题。
调用 malloc() 之后必定写上相应的free() 是一种谨慎的编程风格。程序员就应该小心翼翼地将 malloc()和 free() 对应起来。“因为调用了 exit(),所以就没必要free() 了”的想法是不负责任的偷工减料行为,是不良的编程风格。不管怎么说,程序员也是人,人就是这么一种在可能犯错的地方必定会犯错的生物。可是,“必须 free() 派”却偏要大肆宣扬无论如何都要“谨慎地”编码,这种论调其实是于事无补的。
我认为,“谨慎地”编码并没有什么了不起的,那些能够尽可能地回避“麻烦事”的人才是优秀的程序员。在我心中,理想的程序员是下面这样的:在能够安全地偷懒的地方尽可能地偷懒,并且尽可能地依靠工具而不是肉眼来进行检查,但在无论如何都需要人工处理麻烦的事情时,会在心中坚定地起誓“总有一天要将它自动化”。
这是我最喜欢的一段话。Python 的初学者写的代码,会在所有的函数入口都写上 try-catch,称之为防御性编程。我觉得这么做的人肯定会有这样的疑惑:「怎么这么麻烦?」对于这个疑惑,有两类人,一类是认为「这么做一定有道理,作为程序员我们要不辞劳苦地做好工作。」另一类人认为「一定有更方便的方式」。
正如图 2-17 所示,填充有时会被放到结构体的末尾。因为在创建结构体数组时,填充是必要的。在将 sizeof 运算符应用到这样的结构体上时,返回的是包含末尾填充部分大小的长度。将结果和元素个数相乘,就可以获取数组整体的长度。
——有关结构体的对齐
小端与大端到底哪一种更好呢?这个话题经常引起人们的争论,此处就不再深入讨论了。它们各有各的优点。人类在用纸和笔做加法时也会从低位开始相加,所以对 CPU 来说,或许采用小端的方式更轻松一些,而在人类看来,大端的方式或许更容易理解。
C 语言的声明要用英语阅读
我们可以遵循以下步骤解释 C 语言声明。
先看标识符(变量名或函数名)。
从贴近标识符的地方开始,按照如下优先级解释派生类型(指针、数组、函数):
①用于整合声明的括号;
②表示数组的 []、表示函数的 ();
③表示指针的 *。
完成对派生类型的解释之后,通过 of、to 或returning 连接句子。添加类型修饰符(位于左侧,比如 int、double)。如果不擅长英语,可以用中文解释。
能正确地阅读 C 指针的声明,函数参数中有关指针的声明,已经 sizeof 中的声明,是读此书最大的收获了。
像这样可以确定长度的类型,在标准中被称为对象类型(object type)。然而,函数类型不是对象类型。C 语言中不存在函数类型的变量,因而我们无法(也没必要)确定其长度。我们说过,数组类型是由若干个派生源类型排列而成的类型。因此,数组类型的总长度为:
派生源类型的长度×数组的元素个数
但是,由于函数类型的长度无法确定,所以也就无法从函数类型派生出数组类型。也就是说,无法创造出“函数的数组”这种类型。但是,可以生成“指向函数的指针”这一类型。只是指向函数类型的指针是不能进行指针运算的,因为我们无法确定指针指向的类型的长度。
当表达式代表的是某处的存储空间时,该表达式就称为左值。与此相对,当表达式仅代表值时,该表达式称为右值。表达式中有时存在左值,有时不存在左值。例如,变量名是左值,而 5 这样的常量、1 +hoge 这样使用运算符的表达式就不是左值。
当作为 sizeof 运算符的操作数时
在以“sizeof 表达式”的形式使用 sizeof 运算符时,由于这里的操作数是表达式,所以即使是对数组使用 sizeof,数组也会被解读为指针,从而只能获取指针的长度——或许有人是这样认为的,但其实在数组作为 sizeof 运算符的操作数的情况下,将数组解读为指针这一规则是无效的,在这种情况下返回的是数组整体的长度。
总之,关于指向函数的指针的 C 语言的语法是比较混乱的。造成这种混乱的罪魁祸首就是“函数在表达式中会被解读为指向函数的指针”这一意图不明(难不成是为了与数组保持一致?)的规则。
在表达式中,数组会被解读为指向该数组初始元素的指针,因此代码可以写成下面这样。
int *p; int array[10]; p = array; <-- 将指向array[0]的指针赋给p
但是,反过来写成下面这样就不行。array = p;
数组和指针截然不同。
“不要误会我对 goto 语句持有任何教条主义的执念。我只是担忧,很多人把这件事给神化了,甚至认为仅凭某个编程技巧或某个简单的编程原则,就能解决编程语言的概念问题!”

大家好,欢迎收听老范讲故事的YouTube频道。从1月4号下午到1月4号晚上,都发生了些什么事情?
有传言出来,宇树A股上市的绿色通道被叫停了,机器人赛道要降温。人形机器人现在是不是太卷了?还没有商业应用,你们这么多人就要冲上去上市割韭菜了,这事是不是有问题?

这个消息最早来自于网易科技。但是呢,网易科技上写着说:“我们听说了这样的一个事情,然后呢去找宇树科技确认,没有获得回应。”他到底是不是确认过这事?不知道。但反正他写了这样的一篇文章出来。
到了晚上,宇树受不了了,出来辟谣来了。他说:“我们未涉及申请绿色通道,报道不实,已经向主管部门反映了,并且呢敦促撤回。”这个里头要注意,他没有写我敦促谁,也没有写清楚说我要撤回什么。所以呢,现在就只能认为他在敦促网易科技把你发的这个文章撤回去。
这个官方辟谣呢,也在被很多的媒体进行转载。新浪科技报道20:46转载的,上海证券报和中国证券网是在21:02转载的,新华财经这都属于大官媒了,21:06进行的转载。
到1月5号,更多的主流媒体跟进,转述了宇数科技的官方声明。网易科技的信息已经撤回了,只是部分的镜像服务器上没准你还能找到,但是现在再去找的话,应该已经看不到了。

优先受理,优先审核,缩短排队,这个东西叫绿色通道。要注意,绿色通道里边的企业不会放松标准,只是插个队而已。上市审核的话,这个审核过程很复杂,如果很多公司你想一起上市的话,你有可能排队。他这个叫优先,你先上,但是所有的标准是不能放松的。反正大家是人家就这么说了,咱们就这么信就可以了。
绿色通道这个名字呢,其实并不是那么准确,因为有非常非常多的绿色通道。特别是在上市的过程中,涉及的手续非常的多,涉及的相关部门也非常多。任何一个部门说:“我这块给你加快一点点。”你说这玩意算不算绿色通道?它也算。
大家所理解的真正A股上市绿色通道,到底是个什么东西?证监会在面向科技企业的时候,有一个政策性文件,专门写了一个词叫绿色通道。上面写的什么呢?叫“优先支持突破关键核心技术的科技型企业上市融资、并购重组、债券发行,健全全链条绿色通道机制”。

这个事情呢稍微有一点点玄学。咱们呢是有绿色通道的政策,但是呢通常很少有上市公司敢真的挂上绿色通道的牌子去上市去。原因其实也很简单,因为你一旦挂上这牌子的话,大家觉得凭什么你行我不行?那我一定要好好挑挑你毛病。谁经得起挑毛病?所以大家通常都不挂牌子,我就直接走了。
目前要求能走通绿色通道的公司主要有两类:
那不走绿色通道,是不是上市就会变得很难很慢呢?对于很多要上市的企业来说,不走绿色通道,他压根他就上不去。而且呢在中国上市一直都是很慢的,上市的公司很多,我们如果遇到股市不好,我们还会暂停上市。那么就会有这种积压的现象,所以经常会排好几年。

在中国首先呢你得想上市。你想上市了以后呢,就要去找保荐机构了。宇数科技呢,2025年7月7日跟中信证券签署了辅导协议。2025年10月15日,已经完成了IPO辅导。
1. 制度建设
很多的东西你需要审批,而且所有的步骤你都需要留下痕迹来,以供事后审核。你需要有独立董事,然后呢要设立四大委员会:
2. 合规培训与问题整改
做完制度建设,要去做合规培训,发现不规范的地方赶快改。
3. 监管衔接
保荐机构帮企业去跟监管部门沟通,把文件包装成他们能听懂的语言送上去。
4. 发行准备
写招股说明书,写申报材料,定估值,做募集资金规划,协调会计师事务所、律师事务所等中介机构。
5. 发行承销与持续督导
做询价定价系统,组织股票配售。上市以后还要保证企业继续规范运作,信息真实完整及时披露,并做风险预警。
宇数科技它已经完成了辅导了,11月15号就完成了。那下一步该干嘛呢?提交上市申请文件。
宇数科技呢,目前为止还没有正式提交申请文件。真正的上市流程压根都没开始,前面那部分都不算,真正的上市流程是从提交文件开始的。

绿色通道的差别在于所有的审核都快速进行,通常呢只做两轮的问询和回复。假设宇树科技1月份能够提交了申请,目前预计呢最快是7-10月份就可以在科创板上市了。

首先跟大家一个结论:2025年没有任何一家企业是挂着绿色通道的标签过会的。但是呢确实有一些企业,你说他不是绿色通道吧,大家都不信。
这些企业呢,是按照正常注册制进行优先审核的,但并不是挂牌的绿色通道。2025年A股没有任何官方标注的绿色通道上市案例。

既然大家都不挂牌子,这个里边就有很多可以操作的余地。会有一些中间人(掮客)跑出来说,给钱可以在某些环节走小型的绿色通道。如果不给钱或者价格没谈拢,就会传出“绿色通道被关闭”的传闻。
机器人圈子呢,要比其他圈子要更卷一点点。前面优必选已经上市了,后边智源科技融资体量也不小。大家技术大差不差,就开始卷谁先上市。
能够出来说宇数科技绿色通道被关闭的人,一定是明白中国A股绿色通道的制度到底是怎么样的。宇树科技身上确实没有绿色通道的标签,他现在连文件都没递呢。宇树科技只能出来辟谣,但这辟谣显得极其无力。“没有绿色通道,你还上的去吗?” 这个呢就真的是叫黄泥巴糊裤裆,不是屎也是屎了。
宇数科技呢肯定是被人坑了。大概率呢是某些细节流程上,跟中间人沟通的不顺畅,没有享受到某个快速通道。
中国A股呢,本身就是一个非常魔幻现实的地方。有绿色通道相关的文件和制度,但是呢没有任何公司可以挂着绿色通道的标签公示和过会。同时呢还有硬科技企业优先审查的机制,大家都不是绿色通道,但是我舅舅先给他审查了,这玩意就真的是说你行你就行,不行也行;说不行就不行,行也不行。横批是不服不行。
和股市沾边的事呢,因为离钱太近,所以呢出现任何幺蛾子都别太惊讶。有什么新鲜故事,我们继续去分享。好,这个故事就讲到这里,感谢大家收听。请帮忙点赞点小铃铛,参加DISCORD讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。
Prompt:high-contrast watercolor illustration, bustling stock exchange trading floor, one side featuring a vibrant green channel with glowing positive charts and upward arrows, the opposite side a vivid red channel with declining graphs and downward trends, traders and screens in sharp focus, glossy reflections on glass surfaces, dramatic neon cyan rimlight, deep navy background, cinematic composition with strong subject separation, minimal palette dominated by ink blue, neon cyan, and subtle gold accents, expansive legible negative space for overlay text, ultra-detailed, sharp edges –ar 16:9 –raw –s 250 –v 7.0 –p lh4so59





虽然这个系列的文章都是聚焦于如何通过分析网络抓包文件,结合网络知识,来解决实际的问题的,但是分析之前的步骤——抓包,也是同样重要!很显然,如果不会抓包,那么网络分析去分析什么呢?
抓得一手好包也是很厉害的!笔者遇到过很多次情况,虽然我们无法直接定位根因,但是同事能够精准地捕获到问题的现象,把问题描述给相关的网络专家,传给他们抓包文件,专家一看到准确的抓包文件,就可以很快解决问题了!
可惜的是,抓包的技巧无法像网络分析那样可以通过文章来出谜题,来让读者小试牛刀。所以,这篇文章就来写一下一些常用的抓包方式和技巧,希望能补齐这一块内容。
tcpdump 命令是我们最常用的抓包工具了1。
tcpdump -i eth0 icmp and host 1.1.1.1
这个命令就可以抓取到所有通过 eth0 去 ping 1.1.1.1 这个地址的包。
-i eth0 的意思是抓取指定的 interface,如果不指定,tcpdump 会默认选择一个。但是推荐每次都指定好这个参数,这样就没有不确定性了。如果使用 -i any 就可以抓取所有常规端口(文档的原文是 all regular network interfaces),但是什么属于「常规端口」就取决于操作系统的实现了。所以,建议也是如果要抓取多个 interface 来分析的话,就多开几个 tcpdump 进程,这样更加稳定一些。
这个参数非常有用,比如,在定位 ARP 问题的时候,我们需要确定每一个物理接口收发 ARP 的情况,就可以开多个进程分别 dump 每一个 interface 的网络;在定位 Linux 网络栈不通的情况时2,比如有 macvlan,vlan,veth 等复杂的 driver,可以用 tcpdump 对每一个接口 dump,看下包丢在哪里。
icmp and host 1.1.1.1 这个就是包过滤的表达式了,icmp 表示只抓取 icmp 协议,host 1.1.1.1 表示只抓取 src ip 或者 dst ip 是 1.1.1.1 的包。这种包过滤表达式其实是 pcap-filter(7)3 提供的,所以要想看语法是怎么定义的,看 pcap-filter 的文档就可以了。pcap-filter 支持的语法很灵活,能做的事情很多,基本上想抓什么样的包都可以写出来。但是我们没有必要把所有的语法都记住,因为常用的抓包都是比较简单的。可以找一个 tcpdump exmaple4 看一下,基本就够用了。其次,我们一般不会直接从 tcpdump 就分析出来问题原因,所以这个语法最重要的作用是把我们想要的包抓到,然后为了抓包性能更高,抓包文件更小,我们想要对抓包定义的更精确一些。其实,多抓一些包也没有什么问题,如果不确定怎么过滤出来 TCP SYN+ACK 的包,那不妨就把所有的 SYN 包全抓到,然后再用 Wireshark 这种工具来分析吧。最后,我们现在有 AI 了,用 AI 来写 pcap-filter 也是一个不错的方法,因为这种语法难写,但是很容易验证正确性。
Tcpdump 一些常用的其他参数如下:
-n 不解析主机名和端口号,保留原始的数字-v, -vv, -vvv v 越多表示输出的信息越详细-c 5 表示抓到 5 个包之后就退出-e 显示二层的 link layer header,这样就可以看到 MAC 地址了-Q 可以指定抓包方向,可以选的有 in, out, inout-A 可以展示包的内容,tcpdump 默认是只根据不同的协议展示 header 信息的。在线上排查问题的时候,我们往往需要通过特殊请求的关键字来定位到单个请求的情况进行排查,这样 -A 展示出来包的内容就格外有用。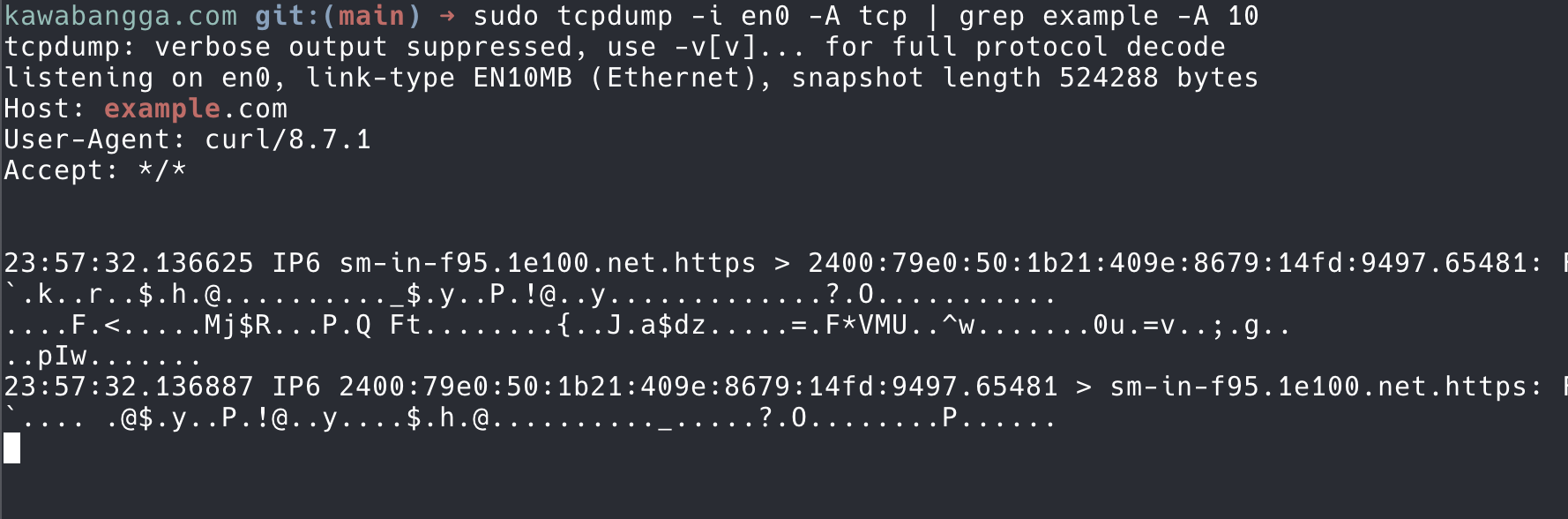
这里分享一个特殊的技巧,就是发标记请求来定位问题。比如 A 通过 B 代理发请求给 C,现在网络不通,我们要定位 B 收到了请求没有,才知道是 B 的问题还是 C 的问题。但是 B 本身就有很多线上流量,怎么知道 A 发送的请求到达 B 了没有呢?我们可以在 B 进行 tcpdump:tcpdump -i eth0 tcp | grep asdf123 -A 10,然后我们从 A 发送一个请求:curl http://host-C.com/asdf123。asdf123 就是我们在请求里面放上的标记,如果 B 能够正常转发,我们就可以 match 到这个请求。当然了,这种技巧只适用于 HTTP 这种明文协议。
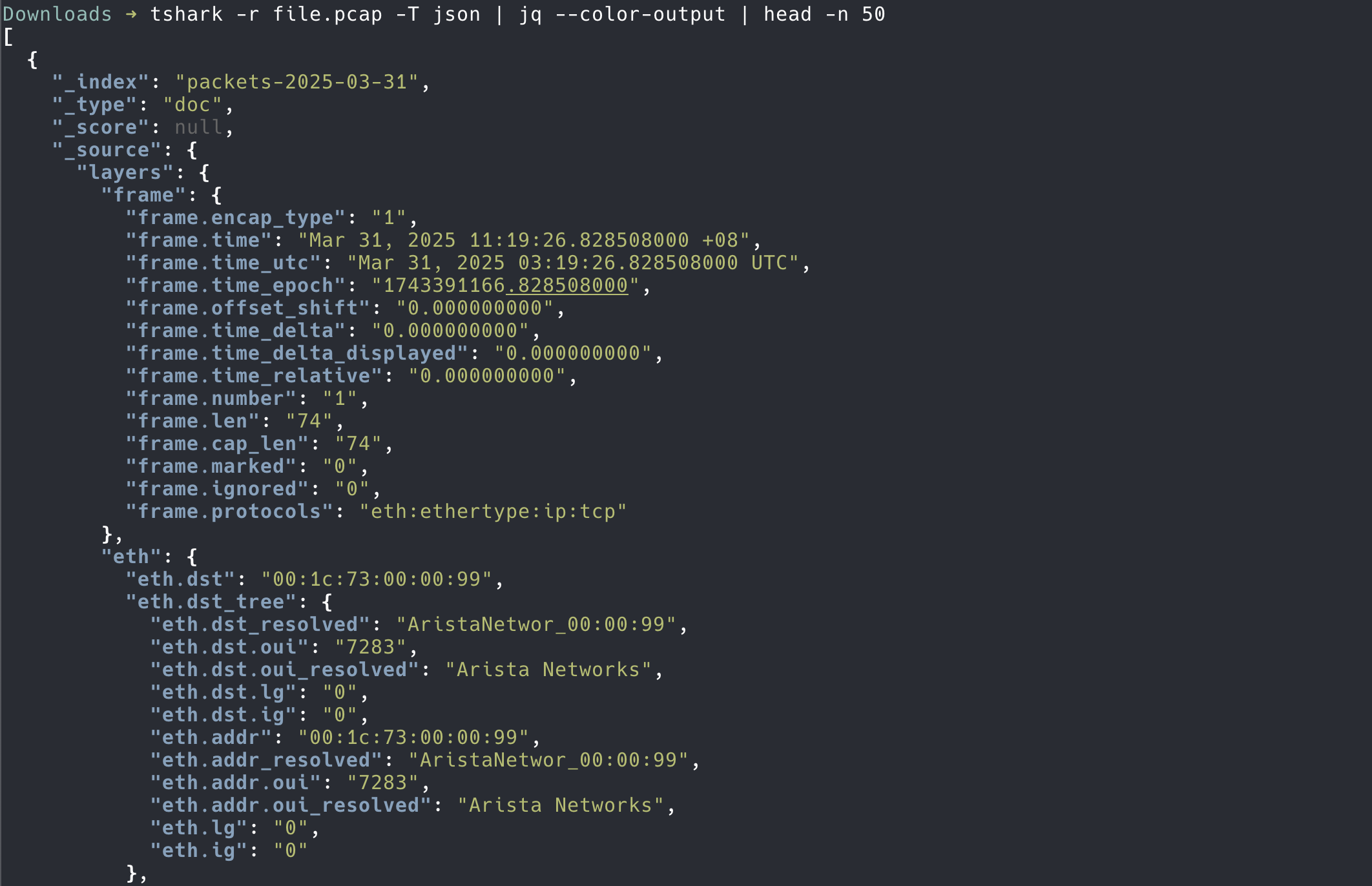
有些问题很难直接在 tcpdump 的终端分析出来问题,比如涉及 sequence number 分析的,重传分析之类的,我们需要人工对比 seq number,真是一项费眼睛的工作!所以如上所说,我们也经常在机器上用 tcpudmp 抓包保存成 .pcap 文件,下载到本地用 Wireshark 分析。Wireshark 就可以自动根据 sequence number 告诉我们重传等信息了!
具体的操作方式是,用 tcpdump -i eth0 -w file.pcap icmp 来进行抓包,-w file.pcap 表示把抓包文件保存为 file.pcap,抓包结束后,就可以把这个文件用 rsync 或者 scp 下载到本地,用 Wireshark 打开了。
.pcap 文件是一种标准的二进制抓包文件5,很多抓包分析工具都支持这种格式的解析,比如 tcpdump, wireshark, scapy 等等,如果想写代码进行更加定制化的分析,也可以用已有的库6解析,就如同用 json 库来解析 json 文件一样。
使用 -w 写入文件的时候有一个小问题,就是 tcpdump 原本的到终端的输出没有了。有两种方式可以解决,第一种是用 tcpdump 自带的 --print 功能:
tcpdump -i eth0 -w file.pcap --print
--print 会让 tcpdump 把内容输出到屏幕,即使当前使用了 -w 参数。
第二种就是用 tee,在写入文件的同时,也写入到 stdout。
tcpdump -i eth0 -U -w - | tee test.pcap | tcpdump -r -
其中,第一个 tcpdump 把抓包文件写入到 stdout(-w stdout,注意其中的 -U 表示按照 packet buffer,即来一个 packet 就输出一个到 stdout,而不是等 buffer 满了才进行输出),然后 tee 这里做了分流,把 stdin(tcpdump 的 stdout)同时输出到文件和 stdout。由于这里的 stdout 是 tcdpump 输出的二进制抓包内容,所以我们需要再用 tcpdump 解析这个二进制内容,-r - 表示从 stdin 读入。
还有一个技巧是 -s 参数,默认情况下 tcpdump 会保存所有抓到的内容,但是在分析某些问题的时候,尤其是 TCP 性能问题,我们其实不需要 TCP 传输的 payload 内容,只看 TCP 包的 header(序列号部分)就知道传输的速度了,所以可以用 -s 40 来只抓取前 40 个 bytes,有了 IP header 和 TCP header,就足够分析了。(如果担心有 TCP option 的存在,可以用 -s 54)
知道包是从哪里抓到的,很重要。在排查问题的时候,拿到抓包文件,应该第一时间确认抓包的位置。否则,就可能连自己看到的问题是现象还是根因都分不清楚。建议在复杂的结构中画一个拓扑图来对照分析,在定位 Linux 网络栈的问题时,如果接口拓扑非常复杂,也建议画一个拓扑图来分析。
可以从网络的多端抓包对照分析。发送端的抓包不一定等于接受端,尤其分析 TCP 问题的时候。可以同时在发送端和接收端进行抓包,然后对照分析。
在使用 tcpdump 的时候,要尤其注意,我们抓到的包已经经过了网卡驱动的处理,网卡驱动经常会帮 CPU 做一些 offload 的工作,比如把可能因网卡的 GRO/LRO 等特性,导致多个小包在抓包时被合并为一个较大的数据包,或者网卡帮助卸载了 vlan tag 等,我们用 tcpdump 抓到的包不一定是真正在网络上传输的包7。要格外注意。
注意抓包不要抓重。比如有人很喜欢用 tcpdump -i any ... 抓全部的包回来慢慢分析。然后下载下来抓包文件就吓坏了——重传率高达 50%!
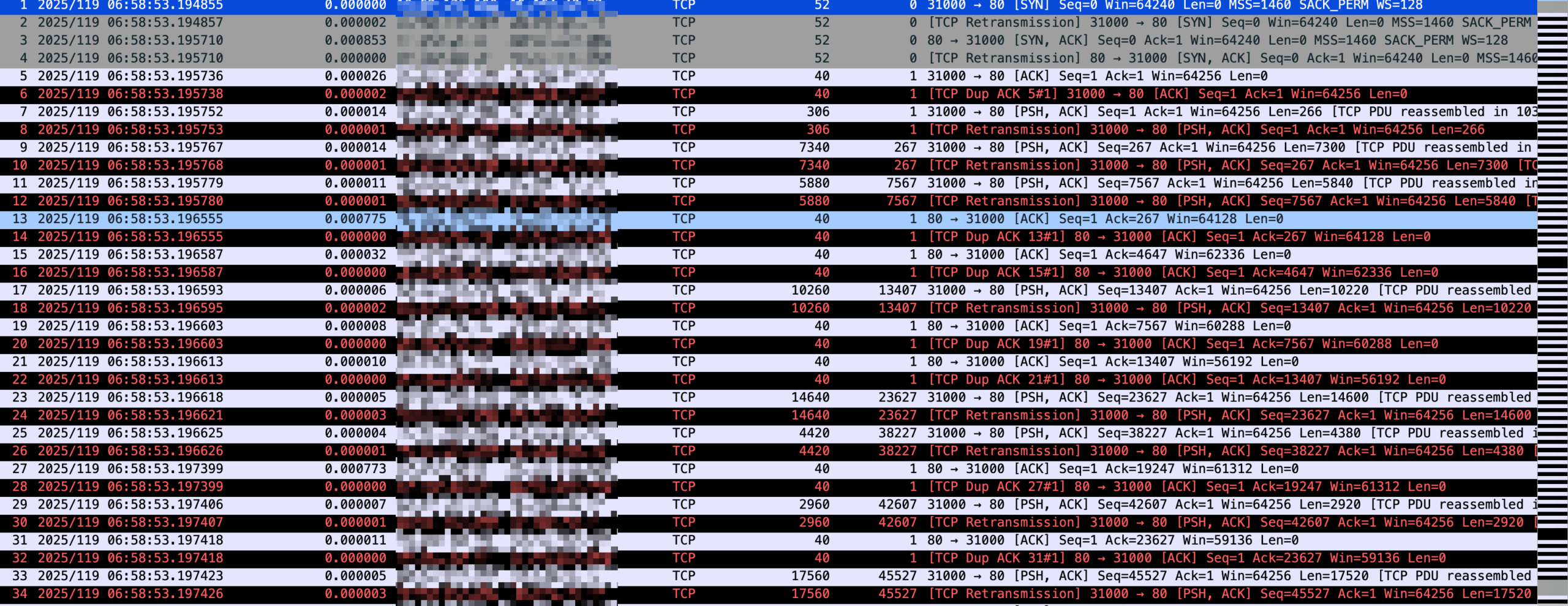
在 Linux 中的网卡配置有 slave 和 master 的时候很容易发生这种情况,比如有 bonding 配置8,-i any 会从 slave 抓包包,从 master 又抓到一次,然后在 Wireshark 看来,所有的包都被重传了。实际是同一个包先后经过 slave 和 master 而已。
抓包的时候最好把相关 host 的 ICMP 协议包也一起抓了。因为 ICMP 是重要的 control message,TCP 在传输的时候,不光有 TCP 协议,可能还会用 ICMP 协议来传递一些信息。比如 PMTUD9,以及之前遇到过的这个问题10,都是涉及到 ICMP 包。如果只按照 TCP 协议来抓包,那这个重要的信息就错过了。
除了我们熟悉的 Linux 抓包,其实网络设备上也可以抓包的。我们一般叫它「端口镜像」技术,故名思义,原理就是把网络设备的一个端口的流量全部复制到另一个端口,而另一个端口连接的就是我们的抓包程序。
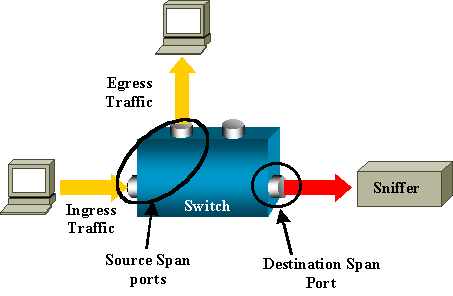
 ︎︎︎︎︎︎︎︎︎︎
︎︎︎︎︎︎︎︎︎︎这篇文章是计算机网络实用技术系列文章中的一篇,这个系列正在连载中,我计划用这个系列的文章来分享一些网络抓包分析的实用技术。这些文章都是总结了我的工作经历中遇到的问题,经过精心构造和编写,每个文件附带抓包文件,通过实战来学习网路分析。
如果本文对您有帮助,欢迎扫博客右侧二维码打赏支持,正是订阅者的支持,让我公开写这个系列成为可能,感谢!
没有链接的目录还没有写完,敬请期待……
与本博客的其他页面不同,本页面使用 署名-非商业性使用-禁止演绎 4.0 国际 协议。

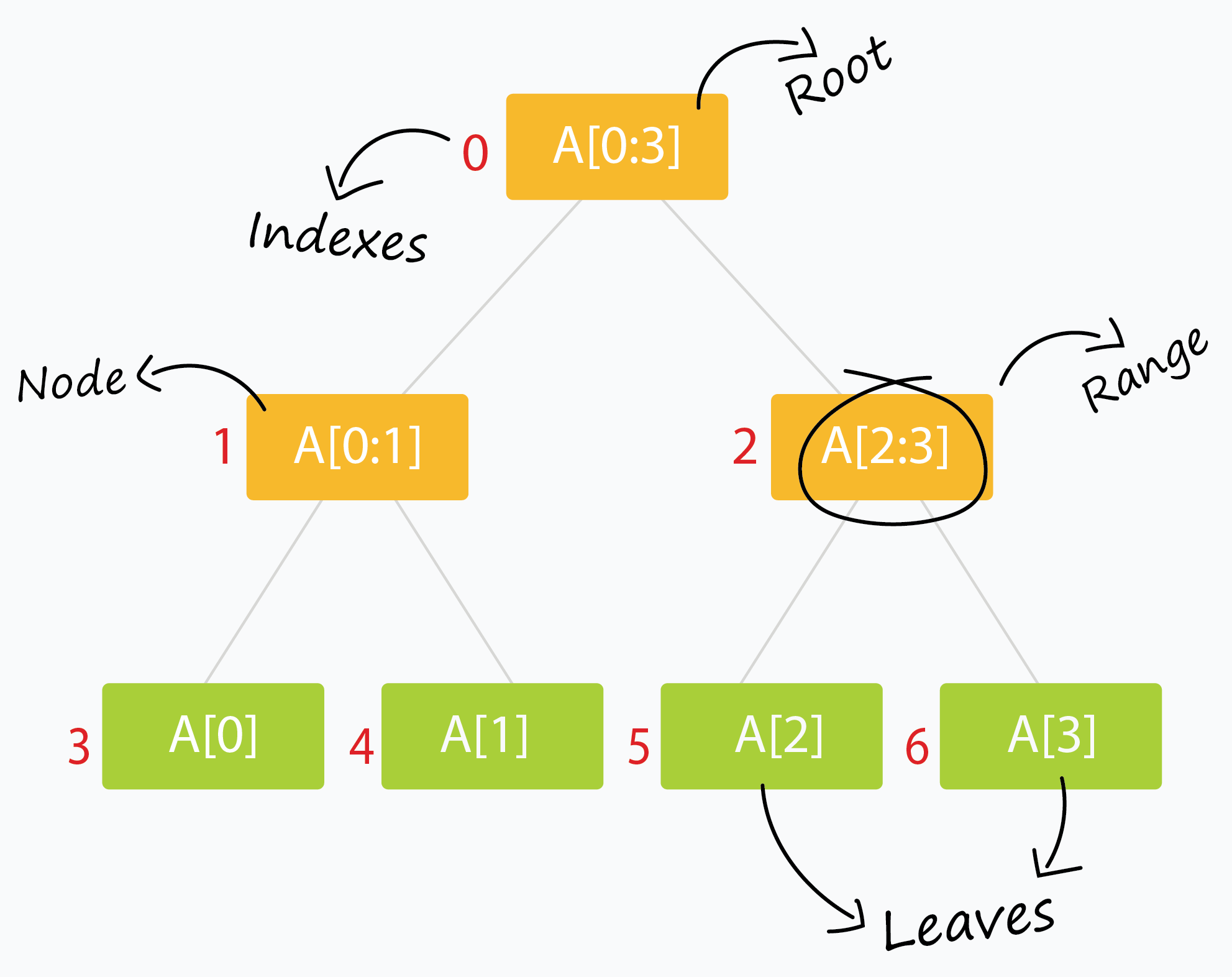
线段树 Segment tree 是一种二叉树形数据结构,1977年由 Jon Louis Bentley 发明,用以存储区间或线段,并且允许快速查询结构内包含某一点的所有区间。
一个包含 $ n $ 个区间的线段树,空间复杂度为 $ O(n) $ ,查询的时间复杂度则为$ O(log n+k) $ ,其中 $ k $ 是符合条件的区间数量。线段树的数据结构也可推广到高维度。
以一维的线段树为例。
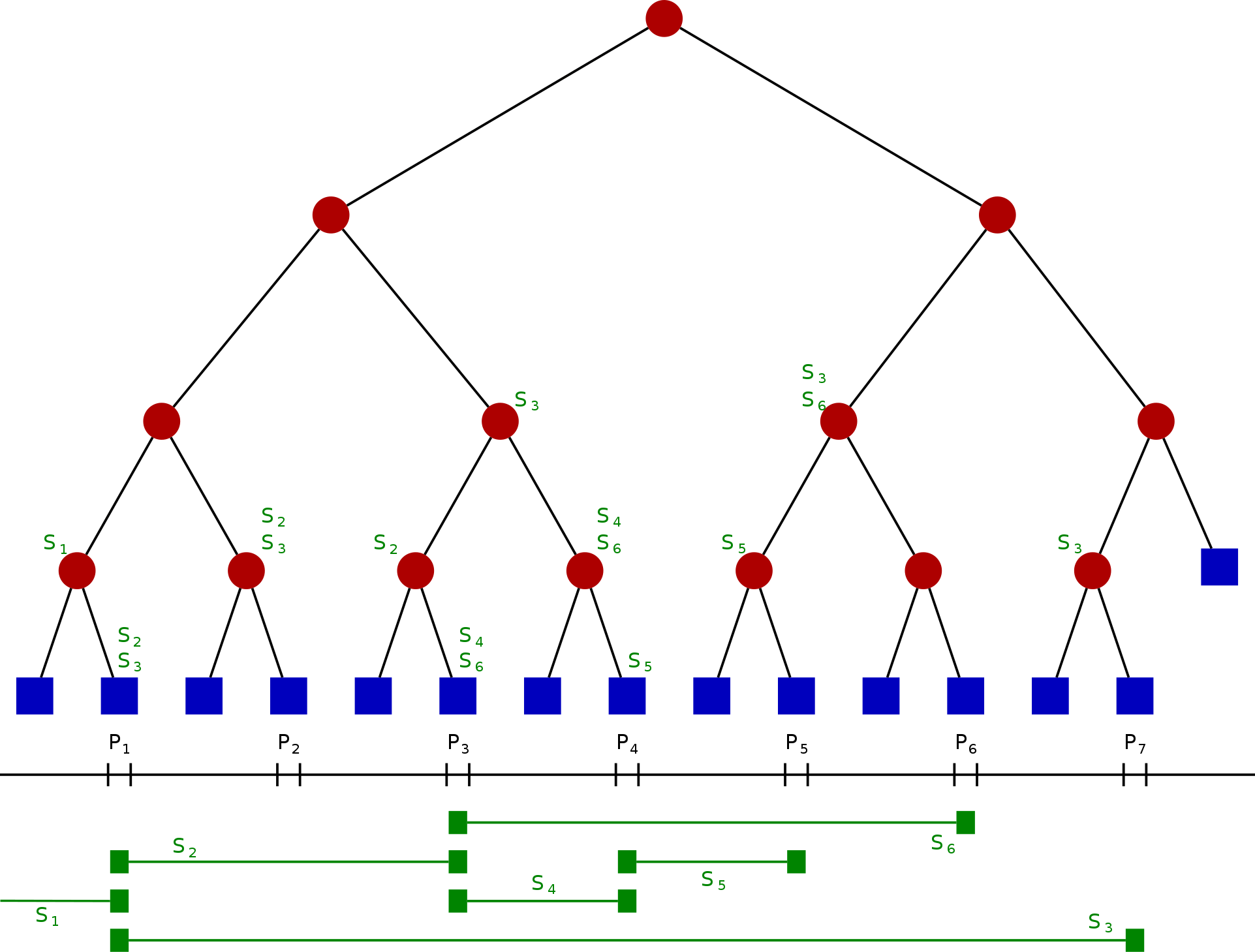
令 S 是一维线段的集合。将这些线段的端点坐标由小到大排序,令其为$ x_{1},x_{2},\cdots ,x_{m} $ 。我们将被这些端点切分的每一个区间称为“单位区间”(每个端点所在的位置会单独成为一个单位区间),从左到右包含:
$$
(-\infty ,x_{1}),[x_{1},x_{1}],(x_{1},x_{2}),[x_{2},x_{2}],...,(x_{m-1},x_{m}),[x_{m},x_{m}],(x_{m},+\infty )
$$
线段树的结构为一个二叉树,每个节点都代表一个坐标区间,节点 N 所代表的区间记为 Int(N),则其需符合以下条件:
线段树是二叉树,其中每个节点代表一个区间。通常,一个节点将存储一个或多个合并的区间的数据,以便可以执行查询操作。
许多问题要求我们基于对可用数据范围或区间的查询来给出结果。这可能是一个繁琐而缓慢的过程,尤其是在查询数量众多且重复的情况下。线段树让我们以对数时间复杂度有效地处理此类查询。
线段树可用于计算几何和地理信息系统领域。例如,距中心参考点/原点一定距离的空间中可能会有大量点。假设我们要查找距原点一定距离范围内的点。一个普通的查找表将需要对所有可能的点或所有可能的距离进行线性扫描(假设是散列图)。线段树使我们能够以对数时间实现这一需求,而所需空间却少得多。这样的问题称为平面范围搜索。有效地解决此类问题至关重要,尤其是在处理动态数据且瞬息万变的情况下(例如,用于空中交通的雷达系统)。下文会以线段树解决 Range Sum Query problem 为例。
上图即作为范围查询的线段树。
假设数据存在 size 为 n 的 arr[] 中。
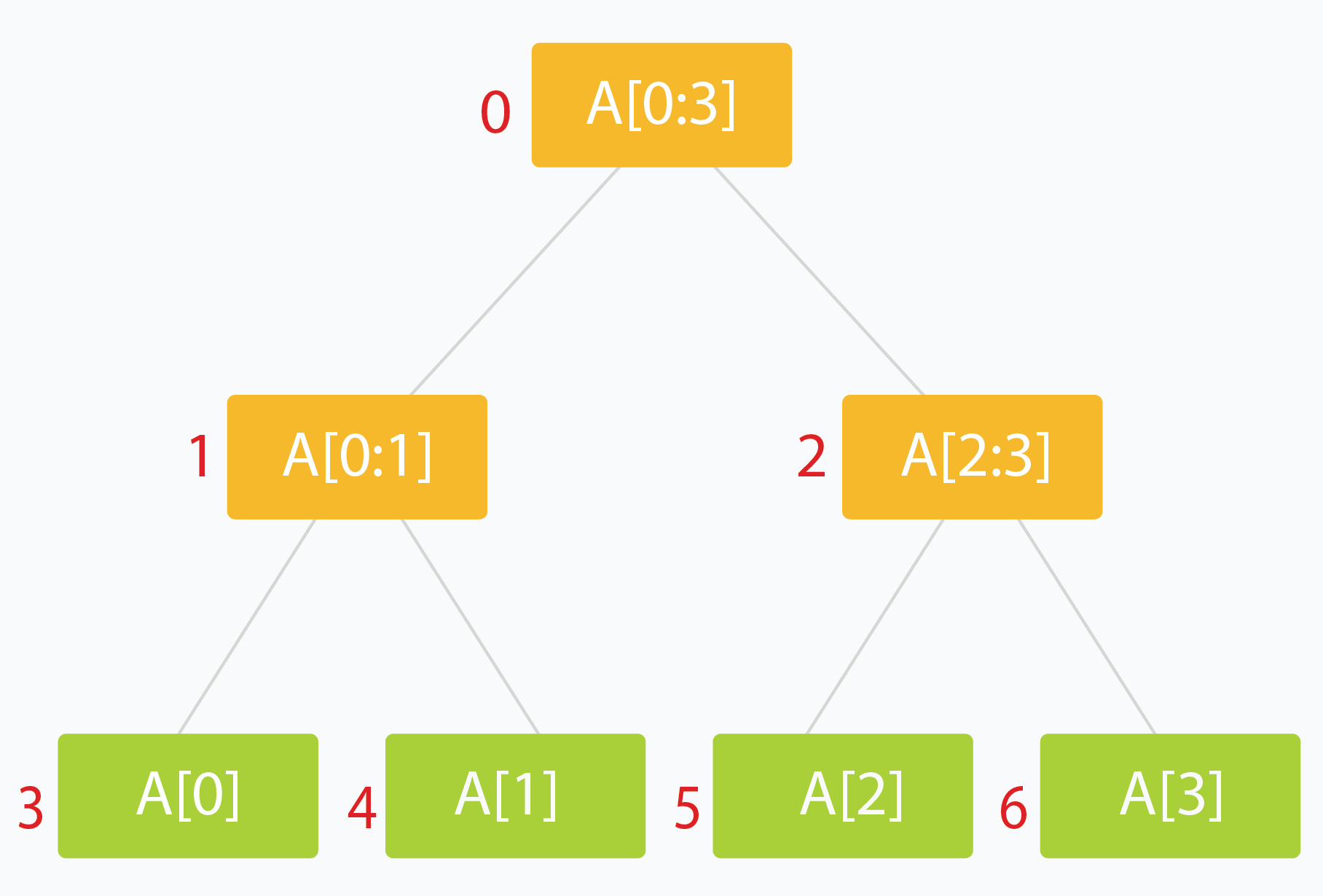
使用大小为 $ \approx 4 \ast n $ 的数组可以轻松表示 n 个元素范围的线段树。(Stack Overflow 对原因进行了很好的讨论。如果你还不确定,请不要担心。本文将在稍后进行讨论。)
下标为 i 的节点有两个节点,下标分别为 $ (2 \ast i + 1) $ 和 $ (2 \ast i + 2)$ 。
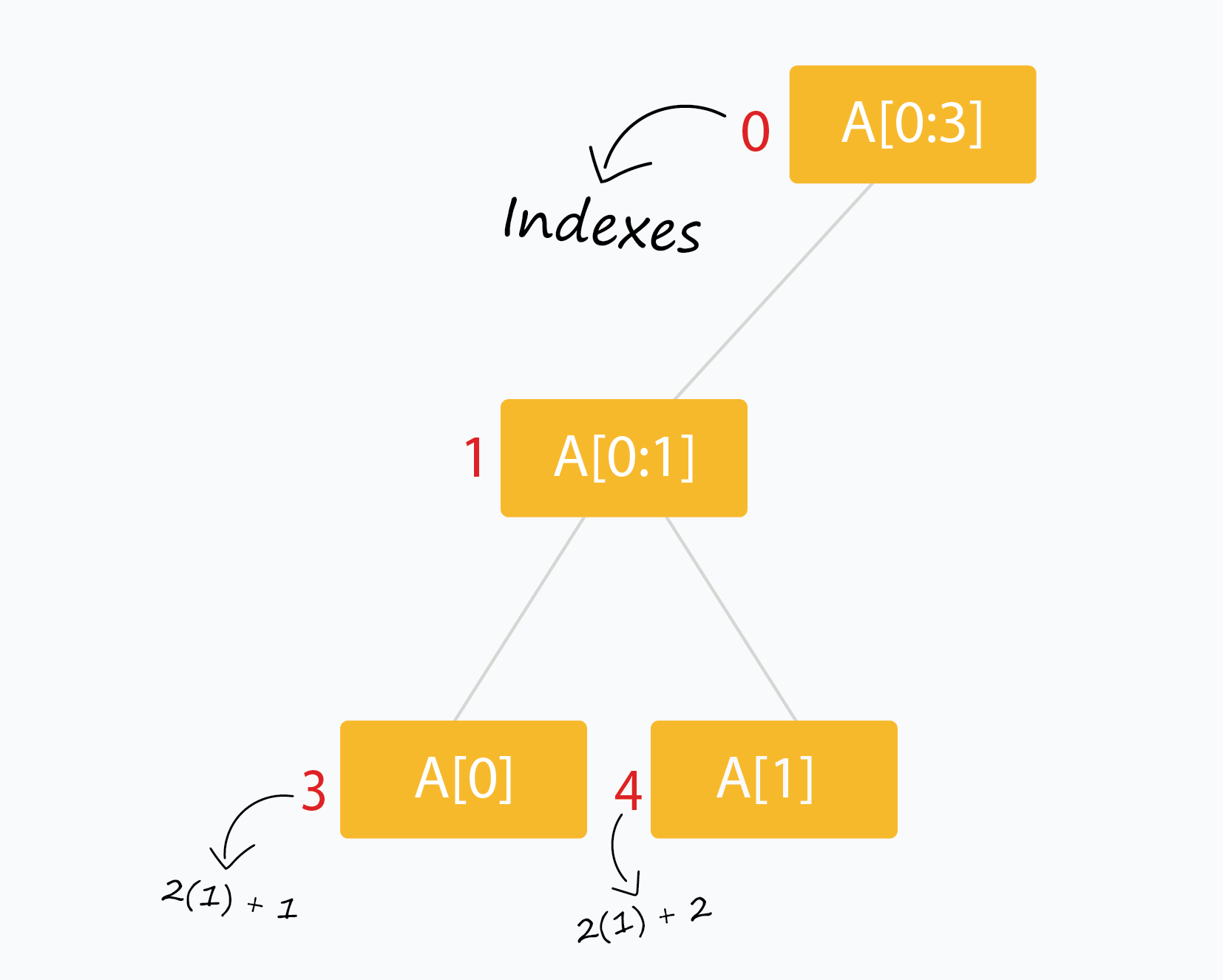
线段树看上去很直观并且非常适合递归构造。
我们将使用数组 tree[] 来存储线段树的节点(初始化为全零)。 下标从 0 开始。
构造线段树的代码如下:
// SegmentTree define
type SegmentTree struct {
data, tree, lazy []int
left, right int
merge func(i, j int) int
}
// Init define
func (st *SegmentTree) Init(nums []int, oper func(i, j int) int) {
st.merge = oper
data, tree, lazy := make([]int, len(nums)), make([]int, 4*len(nums)), make([]int, 4*len(nums))
for i := 0; i < len(nums); i++ {
data[i] = nums[i]
}
st.data, st.tree, st.lazy = data, tree, lazy
if len(nums) > 0 {
st.buildSegmentTree(0, 0, len(nums)-1)
}
}
// 在 treeIndex 的位置创建 [left....right] 区间的线段树
func (st *SegmentTree) buildSegmentTree(treeIndex, left, right int) {
if left == right {
st.tree[treeIndex] = st.data[left]
return
}
midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex)
st.buildSegmentTree(leftTreeIndex, left, midTreeIndex)
st.buildSegmentTree(rightTreeIndex, midTreeIndex+1, right)
st.tree[treeIndex] = st.merge(st.tree[leftTreeIndex], st.tree[rightTreeIndex])
}
func (st *SegmentTree) leftChild(index int) int {
return 2*index + 1
}
func (st *SegmentTree) rightChild(index int) int {
return 2*index + 2
}
笔者将线段树合并的操作变成了一个函数。合并操作根据题意变化,常见的有加法,取 max,min 等等。
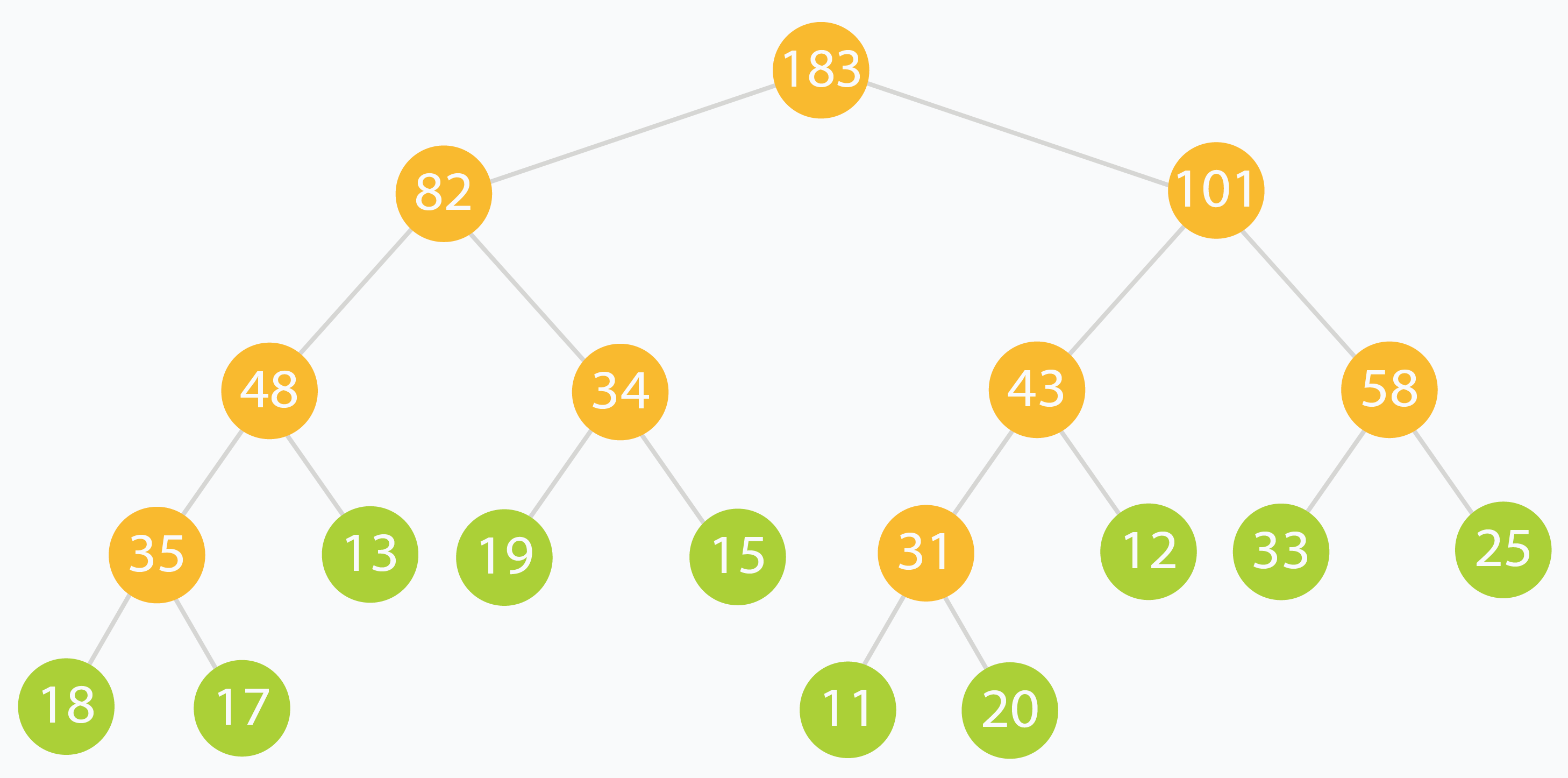
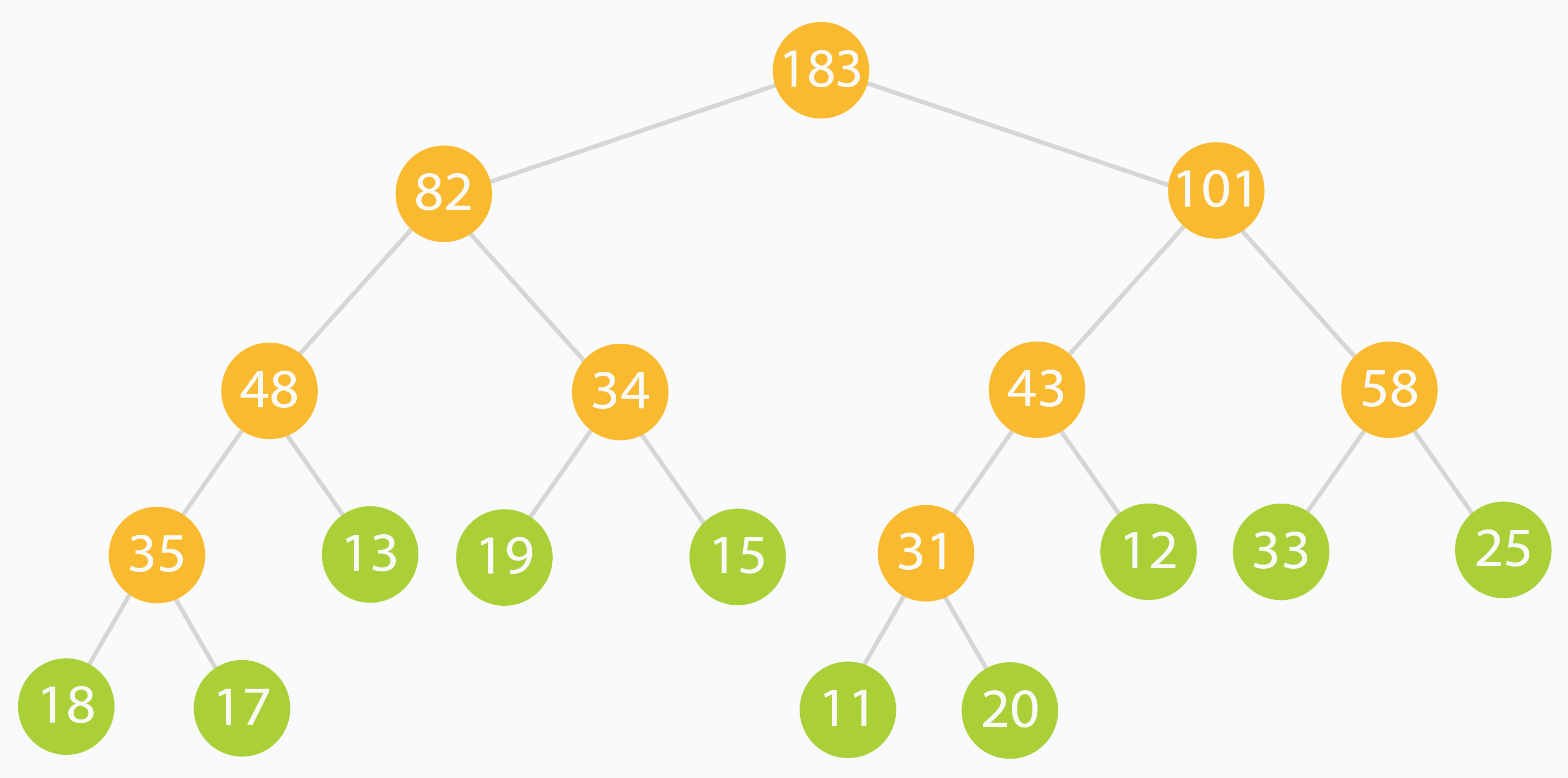
我们以 arr[] = [18, 17, 13, 19, 15, 11, 20, 12, 33, 25 ] 为例构造线段树:

线段树构造好以后,数组里面的数据是:
tree[] = [ 183, 82, 101, 48, 34, 43, 58, 35, 13, 19, 15, 31, 12, 33, 25, 18, 17, 0, 0, 0, 0, 0, 0, 11, 20, 0, 0, 0, 0, 0, 0 ]
线段树用 0 填充到 4*n 个元素。
LeetCode 对应题目是 218. The Skyline Problem、303. Range Sum Query - Immutable、307. Range Sum Query - Mutable、699. Falling Squares
线段树的查询方法有两种,一种是直接查询,另外一种是懒查询。
当查询范围与当前节点表示的范围完全匹配时,该方法返回结果。否则,它会更深入地遍历线段树树,以找到与节点的一部分完全匹配的节点。
// 查询 [left....right] 区间内的值
// Query define
func (st *SegmentTree) Query(left, right int) int {
if len(st.data) > 0 {
return st.queryInTree(0, 0, len(st.data)-1, left, right)
}
return 0
}
// 在以 treeIndex 为根的线段树中 [left...right] 的范围里,搜索区间 [queryLeft...queryRight] 的值
func (st *SegmentTree) queryInTree(treeIndex, left, right, queryLeft, queryRight int) int {
if left == queryLeft && right == queryRight {
return st.tree[treeIndex]
}
midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex)
if queryLeft > midTreeIndex {
return st.queryInTree(rightTreeIndex, midTreeIndex+1, right, queryLeft, queryRight)
} else if queryRight <= midTreeIndex {
return st.queryInTree(leftTreeIndex, left, midTreeIndex, queryLeft, queryRight)
}
return st.merge(st.queryInTree(leftTreeIndex, left, midTreeIndex, queryLeft, midTreeIndex),
st.queryInTree(rightTreeIndex, midTreeIndex+1, right, midTreeIndex+1, queryRight))
}
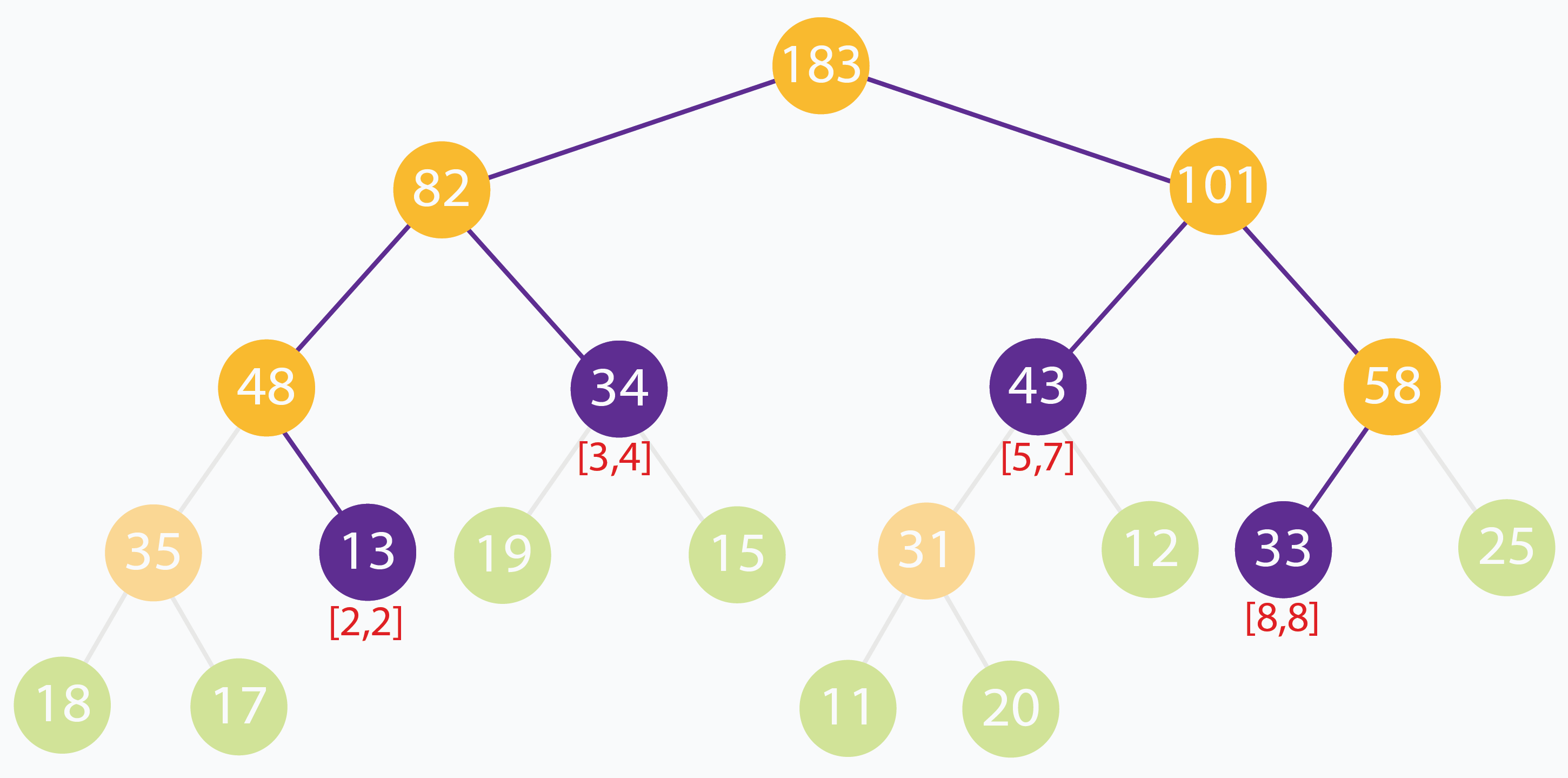
在上面的示例中,查询的区间范围为[2,8] 的元素之和。没有任何线段可以完全代表[2,8] 范围。但是可以观察到,可以使用范围 [2,2],[3,4],[5,7],[8,8] 这 4 个区间构成 [8,8]。快速验证 [2,8] 处的输入元素之和为 13 + 19 + 15 + 11 + 20 + 12 + 33 = 123。[2,2],[3,4],[5,7] 和 [8,8] 的节点总和是 13 + 34 + 43 + 33 = 123。答案正确。
懒查询对应懒更新,两者是配套操作。在区间更新时,并不直接更新区间内所有节点,而是把区间内节点增减变化的值存在 lazy 数组中。等到下次查询的时候再把增减应用到具体的节点上。这样做也是为了分摊时间复杂度,保证查询和更新的时间复杂度在 O(log n) 级别,不会退化成 O(n) 级别。
懒查询节点的步骤:
具体代码如下:
// 查询 [left....right] 区间内的值
// QueryLazy define
func (st *SegmentTree) QueryLazy(left, right int) int {
if len(st.data) > 0 {
return st.queryLazyInTree(0, 0, len(st.data)-1, left, right)
}
return 0
}
func (st *SegmentTree) queryLazyInTree(treeIndex, left, right, queryLeft, queryRight int) int {
midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex)
if left > queryRight || right < queryLeft { // segment completely outside range
return 0 // represents a null node
}
if st.lazy[treeIndex] != 0 { // this node is lazy
for i := 0; i < right-left+1; i++ {
st.tree[treeIndex] = st.merge(st.tree[treeIndex], st.lazy[treeIndex])
// st.tree[treeIndex] += (right - left + 1) * st.lazy[treeIndex] // normalize current node by removing lazinesss
}
if left != right { // update lazy[] for children nodes
st.lazy[leftTreeIndex] = st.merge(st.lazy[leftTreeIndex], st.lazy[treeIndex])
st.lazy[rightTreeIndex] = st.merge(st.lazy[rightTreeIndex], st.lazy[treeIndex])
// st.lazy[leftTreeIndex] += st.lazy[treeIndex]
// st.lazy[rightTreeIndex] += st.lazy[treeIndex]
}
st.lazy[treeIndex] = 0 // current node processed. No longer lazy
}
if queryLeft <= left && queryRight >= right { // segment completely inside range
return st.tree[treeIndex]
}
if queryLeft > midTreeIndex {
return st.queryLazyInTree(rightTreeIndex, midTreeIndex+1, right, queryLeft, queryRight)
} else if queryRight <= midTreeIndex {
return st.queryLazyInTree(leftTreeIndex, left, midTreeIndex, queryLeft, queryRight)
}
// merge query results
return st.merge(st.queryLazyInTree(leftTreeIndex, left, midTreeIndex, queryLeft, midTreeIndex),
st.queryLazyInTree(rightTreeIndex, midTreeIndex+1, right, midTreeIndex+1, queryRight))
}
单点更新类似于 buildSegTree。更新树的叶子节点的值,该值与更新后的元素相对应。这些更新的值会通过树的上层节点把影响传播到根。
// 更新 index 位置的值
// Update define
func (st *SegmentTree) Update(index, val int) {
if len(st.data) > 0 {
st.updateInTree(0, 0, len(st.data)-1, index, val)
}
}
// 以 treeIndex 为根,更新 index 位置上的值为 val
func (st *SegmentTree) updateInTree(treeIndex, left, right, index, val int) {
if left == right {
st.tree[treeIndex] = val
return
}
midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex)
if index > midTreeIndex {
st.updateInTree(rightTreeIndex, midTreeIndex+1, right, index, val)
} else {
st.updateInTree(leftTreeIndex, left, midTreeIndex, index, val)
}
st.tree[treeIndex] = st.merge(st.tree[leftTreeIndex], st.tree[rightTreeIndex])
}

在此示例中,下标为(在原始输入数据中)1、3 和 6 处的元素分别增加了 +3,-1 和 +2。可以看到更改如何沿树传播,一直到根。
线段树仅更新单个元素,非常有效,时间复杂度 O(log n)。 但是,如果我们要更新一系列元素怎么办?按照当前的方法,每个元素都必须独立更新,每个元素都会花费一些时间。分别更新每一个叶子节点意味着要多次处理它们的共同祖先。祖先节点可能被更新多次。如果想要减少这种重复计算,该怎么办?
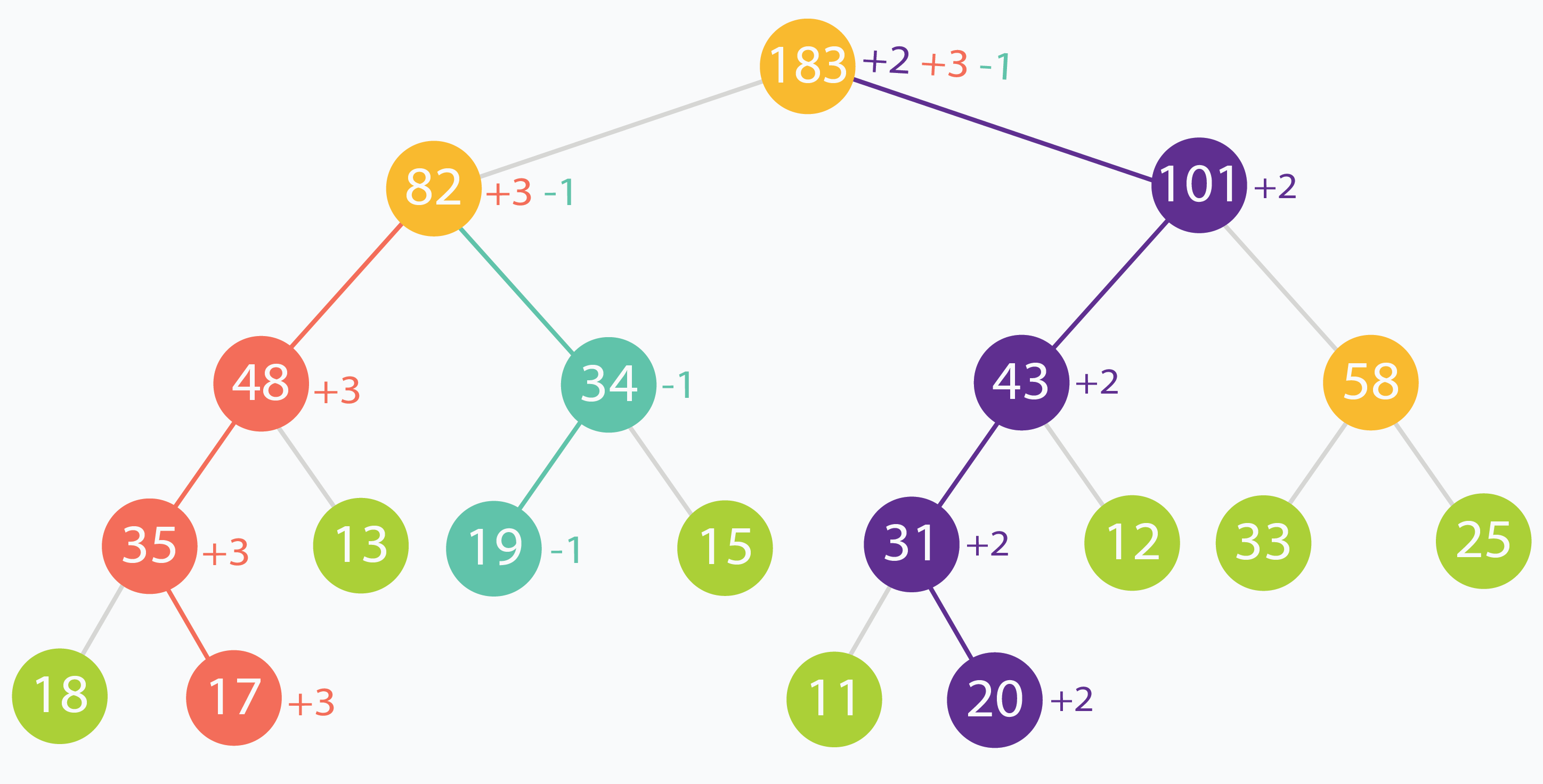
在上面的示例中,根节点被更新了三次,而编号为 82 的节点被更新了两次。这是因为更新叶子节点对上层父亲节点有影响。最差的情况,查询的区间内不包含频繁更新的元素,于是需要花费很多时间更新不怎么访问的节点。增加额外的 lazy 数组,可以减少不必要的计算,并且能按需处理节点。
使用另一个数组 lazy[],它的大小与我们的线段树 array tree[] 完全相同,代表一个惰性节点。当访问或查询该节点时,lazy[i] 中保留需要增加或者减少该节点 tree[i] 的数量。 当 lazy[i] 为 0 时,表示 tree[i] 该节点不是惰性的,并且没有缓存的更新。
更新区间内节点的步骤:
具体代码如下:
// 更新 [updateLeft....updateRight] 位置的值
// 注意这里的更新值是在原来值的基础上增加或者减少,而不是把这个区间内的值都赋值为 x,区间更新和单点更新不同
// 这里的区间更新关注的是变化,单点更新关注的是定值
// 当然区间更新也可以都更新成定值,如果只区间更新成定值,那么 lazy 更新策略需要变化,merge 策略也需要变化,这里暂不详细讨论
// UpdateLazy define
func (st *SegmentTree) UpdateLazy(updateLeft, updateRight, val int) {
if len(st.data) > 0 {
st.updateLazyInTree(0, 0, len(st.data)-1, updateLeft, updateRight, val)
}
}
func (st *SegmentTree) updateLazyInTree(treeIndex, left, right, updateLeft, updateRight, val int) {
midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex)
if st.lazy[treeIndex] != 0 { // this node is lazy
for i := 0; i < right-left+1; i++ {
st.tree[treeIndex] = st.merge(st.tree[treeIndex], st.lazy[treeIndex])
//st.tree[treeIndex] += (right - left + 1) * st.lazy[treeIndex] // normalize current node by removing laziness
}
if left != right { // update lazy[] for children nodes
st.lazy[leftTreeIndex] = st.merge(st.lazy[leftTreeIndex], st.lazy[treeIndex])
st.lazy[rightTreeIndex] = st.merge(st.lazy[rightTreeIndex], st.lazy[treeIndex])
// st.lazy[leftTreeIndex] += st.lazy[treeIndex]
// st.lazy[rightTreeIndex] += st.lazy[treeIndex]
}
st.lazy[treeIndex] = 0 // current node processed. No longer lazy
}
if left > right || left > updateRight || right < updateLeft {
return // out of range. escape.
}
if updateLeft <= left && right <= updateRight { // segment is fully within update range
for i := 0; i < right-left+1; i++ {
st.tree[treeIndex] = st.merge(st.tree[treeIndex], val)
//st.tree[treeIndex] += (right - left + 1) * val // update segment
}
if left != right { // update lazy[] for children
st.lazy[leftTreeIndex] = st.merge(st.lazy[leftTreeIndex], val)
st.lazy[rightTreeIndex] = st.merge(st.lazy[rightTreeIndex], val)
// st.lazy[leftTreeIndex] += val
// st.lazy[rightTreeIndex] += val
}
return
}
st.updateLazyInTree(leftTreeIndex, left, midTreeIndex, updateLeft, updateRight, val)
st.updateLazyInTree(rightTreeIndex, midTreeIndex+1, right, updateLeft, updateRight, val)
// merge updates
st.tree[treeIndex] = st.merge(st.tree[leftTreeIndex], st.tree[rightTreeIndex])
}
LeetCode 对应题目是 218. The Skyline Problem、699. Falling Squares
让我们看一下构建过程。我们访问了线段树的每个叶子(对应于数组 arr[] 中的每个元素)。因此,我们处理大约 2 * n 个节点。这使构建过程时间复杂度为 O(n)。对于每个递归更新的过程都将丢弃区间范围的一半,以到达树中的叶子节点。这类似于二分搜索,只需要对数时间。更新叶子后,将更新树的每个级别上的直接祖先。这花费时间与树的高度成线性关系。

4*n 个节点可以确保将线段树构建为完整的二叉树,从而树的高度为 log(4*n + 1) 向上取整。线段树读取和更新的时间复杂度都为 O(log n)。
Range Sum Queries 是 Range Queries 问题的子集。给定一个数据元素数组或序列,需要处理由元素范围组成的读取和更新查询。线段树 Segment Tree 和树状数组 Binary Indexed Tree (a.k.a. Fenwick Tree)) 都能很快的解决这类问题。
Range Sum Query 问题专门处理查询范围内的元素总和。这个问题存在许多变体,包括不可变数据,可变数据,多次更新,单次查询 和 多次更新,多次查询。
这类题目会询问区间中满足条件的连续最长区间,所以PushUp的时候需要对左右儿子的区间进行合并
这类题目需要将一些操作排序,然后从左到右用一根扫描线扫过去最典型的就是矩形面积并,周长并等题
在 LeetCode 中还有一类问题涉及到计数的。315. Count of Smaller Numbers After Self,327. Count of Range Sum,493. Reverse Pairs 这类问题可以用下面的套路解决。线段树的每个节点存的是区间计数。
// SegmentCountTree define
type SegmentCountTree struct {
data, tree []int
left, right int
merge func(i, j int) int
}
// Init define
func (st *SegmentCountTree) Init(nums []int, oper func(i, j int) int) {
st.merge = oper
data, tree := make([]int, len(nums)), make([]int, 4*len(nums))
for i := 0; i < len(nums); i++ {
data[i] = nums[i]
}
st.data, st.tree = data, tree
}
// 在 treeIndex 的位置创建 [left....right] 区间的线段树
func (st *SegmentCountTree) buildSegmentTree(treeIndex, left, right int) {
if left == right {
st.tree[treeIndex] = st.data[left]
return
}
midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex)
st.buildSegmentTree(leftTreeIndex, left, midTreeIndex)
st.buildSegmentTree(rightTreeIndex, midTreeIndex+1, right)
st.tree[treeIndex] = st.merge(st.tree[leftTreeIndex], st.tree[rightTreeIndex])
}
func (st *SegmentCountTree) leftChild(index int) int {
return 2*index + 1
}
func (st *SegmentCountTree) rightChild(index int) int {
return 2*index + 2
}
// 查询 [left....right] 区间内的值
// Query define
func (st *SegmentCountTree) Query(left, right int) int {
if len(st.data) > 0 {
return st.queryInTree(0, 0, len(st.data)-1, left, right)
}
return 0
}
// 在以 treeIndex 为根的线段树中 [left...right] 的范围里,搜索区间 [queryLeft...queryRight] 的值,值是计数值
func (st *SegmentCountTree) queryInTree(treeIndex, left, right, queryLeft, queryRight int) int {
if queryRight < st.data[left] || queryLeft > st.data[right] {
return 0
}
if queryLeft <= st.data[left] && queryRight >= st.data[right] || left == right {
return st.tree[treeIndex]
}
midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex)
return st.queryInTree(rightTreeIndex, midTreeIndex+1, right, queryLeft, queryRight) +
st.queryInTree(leftTreeIndex, left, midTreeIndex, queryLeft, queryRight)
}
// 更新计数
// UpdateCount define
func (st *SegmentCountTree) UpdateCount(val int) {
if len(st.data) > 0 {
st.updateCountInTree(0, 0, len(st.data)-1, val)
}
}
// 以 treeIndex 为根,更新 [left...right] 区间内的计数
func (st *SegmentCountTree) updateCountInTree(treeIndex, left, right, val int) {
if val >= st.data[left] && val <= st.data[right] {
st.tree[treeIndex]++
if left == right {
return
}
midTreeIndex, leftTreeIndex, rightTreeIndex := left+(right-left)>>1, st.leftChild(treeIndex), st.rightChild(treeIndex)
st.updateCountInTree(rightTreeIndex, midTreeIndex+1, right, val)
st.updateCountInTree(leftTreeIndex, left, midTreeIndex, val)
}
}
【阅读时间】
【阅读内容】结合Leetcode相关算法题总结二叉搜索树的相关算法,包括基本的二叉搜索构建和应用,附带一些关于AVL树,红黑树的基本概念梳理
二叉搜索树(Binary Search Tree)BST是大名鼎鼎的搜索算法。在算法界,$O(n)$ 到 $O(\log_2 n)$ 的效率优化大多和BST有关
用白话文来说,二叉搜索树是一颗对于所有节点左孩子 < 根,右子树 > 根的二叉树
相关例题:108. Convert Sorted Array to Binary Search Tree
已经给出了定义,Leetcode中有一道将升序数组转换成平衡二叉搜索树的题目。根据二叉树遍历一节的内容,中序遍历的顺序是左 ➜ 根 ➜ 右,再结合二叉搜索树的定义。观察知,二叉搜索树的中序遍历就是一个升序数组。那么问题就转换成了,哪颗平衡二叉树的中序遍历是这个升序数组
因为题目要求平衡二叉树,保证所有子树的高度一样,必须二分输入序列
假设输入序列为[-10,-3,0,5,9],根节点一定在mid = (start + end) // 2 位置,由递归思维:假设再次调用的函数的返回值是已经完成的子树,也就是说只需把[0, mid-1]代表的树作为左子树,和[mid+1, end]代表的树作为右子树即可
1 |
class Solution: |
相关例题:700. Search in a Binary Search Tree
最常见的二叉树操作,查找一个对应节点,平均查找长度为 $\log_2(n)$ 。二叉搜索树性质,左孩子<根<右孩子,按照规律进行递归即可。省略迭代写法,只需要按照顺序进行一个节点一个节点顺下即可,非常简单
1 |
class Solution: |
相关例题:98. Validate Binary Search Tree
【输入】给定一个树的结构【操作】判断这颗树是不是二叉搜索树【输出】True or False
① 使用中序遍历,结果是升序序列则为二叉搜索树(前面讲定义的时候已经讲解的原因)
② 去重复操作。①中在遍历过程就可做判断,不需要重新再做一次升序判断
这里实现使用迭代写法,递归写法比较简单
1 |
class Solution(object): |
二叉查找树中的删除节点操作,详见链接
需要分为3种情况进行讨论
【阅读时间】7 - 10 min | 4300字
【阅读内容】结合应用场景,总结有关二叉树遍历的所有算法和对应Leetcode题目编号。基于Python代码,给出完整逻辑链。希望给读者一个线头,让你永远忘不了这几个遍历算法
遍历的含义就是把树的所有节点(Node)按照某种顺序访问一遍。包括前序,中序,后续,广度优先(队列),深度优先(栈)5中遍历方法
| 遍历方法 | 顺序 | 示意图 | 应用 |
|---|---|---|---|
| 前序 | 根 ➜ 左 ➜ 右 |  |
想在节点上直接执行操作(或输出结果)使用先序 |
| 中序 | 左 ➜ 根 ➜ 右 |  |
在二分搜索树中,中序遍历的顺序符合从小到大(或从大到小)顺序的 要输出排序好的结果使用中序 |
| 后序 | 左 ➜ 右 ➜ 根 |  |
后续遍历的特点是在执行操作时,肯定已经遍历过该节点的左右子节点 适用于进行破坏性操作 比如删除所有节点,比如判断树中是否存在相同子树 |
| 广度优先 | 层序,横向访问 |  |
当树的高度非常高(非常瘦) 使用广度优先剑节省空间 |
| 深度优先 | 纵向,探底到叶子节点 | 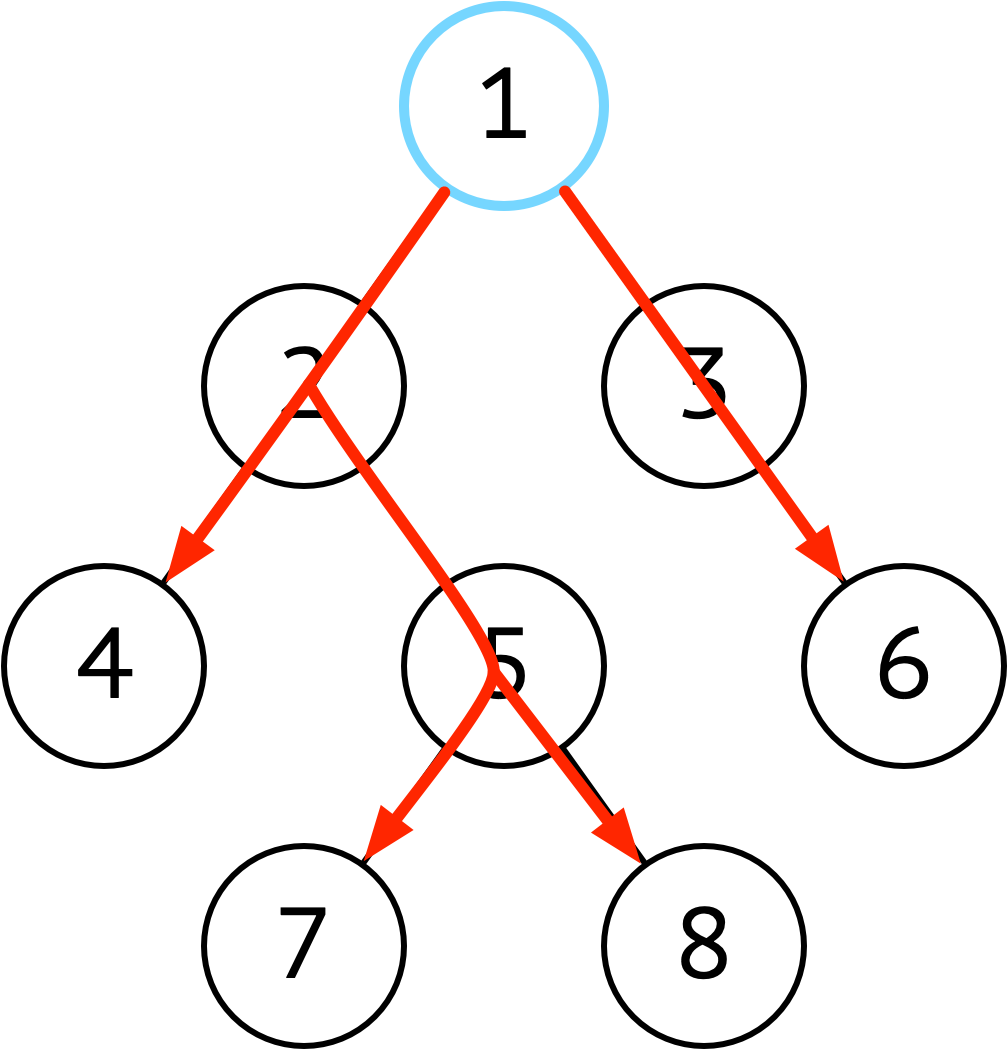 |
当每个节点的子节点非常多(非常胖),使用深度优先遍历节省空间 (访问顺序和入栈顺序相关,想当于先序遍历) |
关于应用部分,选择遍历方法的基本的原则:更快的访问到你想访问的节点。先序会先访问根节点,后序会先访问叶子节点
需要说明的是,递归是一种拆分思维的具体问题类别的思维方法,其核心的思维我觉得和动态规划非常类似,都是假设子节点搞定了我现在应该干什么这个问题
先确定Python语言下的TreeNode定义
1 |
class TreeNode: |
需要输出遍历结果时直接输出保存val的数组即可
关于递归算法的解释,博主打算写一份【直观算法】汉诺塔问题最全解答,过后可能会更新,是一篇小品文,比较短,这篇文章只是希望让所有阅读的人能一次就直观的搞明白汉诺塔的算法是怎么做的,永远记住它,也搞懂递归算法
三种遍历方法,都有一个特点,无论是先序根 ➜ 左 ➜ 右,中序左 ➜ 根 ➜ 右,后序左 ➜ 右 ➜ 根,所谓的访问顺序,根是最重要,根才代表了访问这个动作(在我们的代码中,就是把节点中的值加入到输出数组中),⭐️而根在的位置决定了是否可以访问的条件
比如对于中序来说,根在左的后面,意味着,只要当前操作的节点有左节点,就不能输出根里面的值
对于后序来说,有了这个直观理解,对理解三者的迭代算法有帮助
在线刷题:Leetcode 44. Binary Tree Preorder Traversal
所谓递归(Recursive),即把函数本身看成一个已经有解的子问题
定义函数preorderTraversal(self, node)返回以node为答案的先序遍历结果的数组,假设它的两个孩子node.left和node.right已经搞定了,即可以返回答案的输出数组。那么思考最终的输出数组是什么样的,很明显要满足根 ➜ 左 ➜ 右的规则,应该返回[node.val] + preorderTraversal(self, node.left) + preorderTraversal(self, node.right)(函数返回的就是一个数组,只需要把它们拼接起来即可)
之后再完善防御性编程的基本步骤(保证函数输入有效),按照这个思路就可以写出先序遍历的递归代码。Python代码的特点是可读性比较强,这样一行代码简洁明了,能简洁的表达上面的逻辑链推理过程
1 |
class Solution: |
当然,如果不使用Python,在语法上无法写的这么简短。常见的标准写法是使用helper()函数,具体实现见下
1 |
def preorderTraversal1(self, root): |
同理,递归算法使用系统栈,不好控制,性能问题比较严重,需要进一步了解不用递归如何实现。为了维护固定的访问顺序,使用栈数据结构的先入后出特性
先处理根节点,根据访问顺序根 ➜ 左 ➜ 右,先入栈的后访问,为了保持访问顺序(先入后出),⭐️先把右孩子入栈,再入栈左孩子(此处需要注意,出栈才是访问顺序)
1 |
class Solution: |
在线刷题:94. Binary Tree Inorder Traversal
同理于前序遍历,一模一样的处理方法,考虑访问顺序为左 ➜ 根 ➜ 右即可,快速模仿并写出代码
1 |
class Solution: |
同理在这里也附上使用helper()函数的标准写法,代码上来说,只变了名称和访问顺序
1 |
def inorderTraversal1(self, root): |
核心思路依旧是利用栈维护节点的访问顺序:左 ➜ 根 ➜ 右。使用一个p_node来指向当前访问节点,p是代表指针point,另外有一个变量cur_node表示当前正在操作节点(把出栈节点值加入输出数组中),算法步骤如下(可以对照代码注释)
① 访问当前节点,如果当前节点有左孩子,则把它的左孩子都入栈,移动当前节点到左孩子,重复第一步直到当前节点没有左孩子
② 当当前节点没有左孩子时,栈顶节点出栈,加入结果数组
③ 当前节点指向栈顶节点的右节点
1 |
class Solution: |
如果想要精简代码,从逻辑上来看,p_node可以使用root代替,这样写只是为了让代码更可读,和逻辑链相切合,方便理解
在线刷题:145. Binary Tree Postorder Traversal
同理先序遍历,代码如下
1 |
class Solution: |
节省版面,使用helper()函数的写法只需要改变函数名和访问顺序
后序遍历访问顺序要求为左 ➜ 右 ➜ 根,在对访问节点进行操作的条件是,它的左子树和右子树都已经被访问。这样算法的框架就出来了:只需要对每个节点进行标记,表示这个节点有没有被访问,一个节点能否进行操作的条件就是这个节点的左右节点都被访问过了。
因为栈先入后出,为了维护访问顺序满足条件,入栈顺序应该是根 ➜ 右 ➜ 左(和要求访问顺序相反)。代码如下
1 |
class Solution: |
还有一种迭代算法利用后序遍历的本身属性,注意到后序遍历的顺序是左 ➜ 右 ➜ 根,那么反序的话,就直接倒序的输出结果,即反后序:根 ➜ 右 ➜ 左,和先序遍历的根 ➜ 左 ➜ 右对比,发现只需要稍微改一下代码就可以得到反后序的结果,参考先序遍历,代码如下
1 |
class Solution: |
从上到下的层序102. Binary Tree Level Order Traversal
从下到上的层序(Bottom-up) 107. Binary Tree Level Order Traversal 2
按照层序进行遍历的的过程,有两种说法,一种是按照层序的从顶到底的(level order),另一种是从底到顶的(bottom up),具体实现上来说,就是输出反序即可。在具体问题设计上可能有区别,但是基本思路不变
广度遍历的核心思路就是使用队列,即先进先出 First-in First-out,这里很关键的一点就是以层来作为入队和出队的判断条件。并且因为按照层的顺序,是从左到右,所以遍历顺序(入队顺序)为左 ➜ 右
基本思路参看代码注释,逻辑比较简单。实现上,使用Python中的自带类deque来实现,新建为queue = deque([]),入队为queue.append(),出队为queue.popleft()
1 |
from collections import deque |
226. Invert Binary Tree,就是一道基本的树的遍历题。有故事说Mac包管理工具Brew的作者Max在Google被面试这道题,没写出来,被拒了。之后Max去了Apple。个人感觉,对于遍历的理解,如果是真的根据逻辑链理解,且对递归有着深刻的理解,那实在不应该写不出这道题,因为真的很简单
题目是这样说的,要求把一颗二叉树的所有左右子树互换位置
假设左右子树都搞定了,那么当前节点需要的操作为:把当前节点的左右孩子互换即可,写成递归非常简洁
1 |
class Solution: |
因为对于每一个节点,只需要把它的左右孩子互换位置,并且依次遍历即可,使用DFS或BFS都是一样的,这里用使用栈的深度优先搜索举例
1 |
class Solution: |
二叉树遍历问题最关键的逻辑链记忆点如下
遍历顺序
⭐️遍历顺序非常重要,即某 ➜ 某 ➜ 某。如果这一点你不太记得,我认为在考试的过程中可以尝试向面试官确认,某的带选项只有三个,就是根,左,右,全排列也只有6种,长时间不用不记得也是情有可原的。所以在这里非常优秀
递归 ➜ 假设搞定了
确认遍历顺序后,写出递归方法的核心思维是:⭐️假设左右孩子搞定了(搞定的方式就是调用函数本身,替换自变量即可),现在怎么做才能得到最终答案
一般面试官会继续询问迭代方法如何写,这里的核心思维是:⭐️关注根的位置,根对应的就是出栈输出的操作(在例题中就是添加到输出数组)
那么根据遍历顺序,⭐️只要根之前的左或右孩子不为空就不能出栈输出,要继续入栈(办法自己想即可,每次可能写出来的代码都不同,但是思路相同。需要例子,可以参考中序和后序里的迭代算法部分)