大多数应用的运行速度都比实际需要的要慢——原因如下(现场演示)

Most Apps Are Slower Than They Need to Be — Here’s Why (Live Demo) (dev.to)

本文永久链接 – https://tonybai.com/2026/03/28/ai-engineer-gpu-introduction-course
大家好,我是Tony Bai。
就在最近,科技界发生了一件极其戏剧性的事情。本周三美股开盘,全球存储产业巨头——美光、西部数据、希捷的股价遭遇了“黑色时刻”,普遍明显下跌(3%~6%)。
引发这场资本市场大地震的,不是什么贸易战,也不是财报暴雷,而仅仅是谷歌(Google Research)发布的一篇技术论文:《TurboQuant: Redefining AI efficiency with extreme compression》。
这篇论文宣称,他们发明了一种极端的压缩算法,能在几乎零损耗的情况下,将大模型推理时的 KV 缓存(KV Cache)暴降 6 倍,并让注意力机制的计算速度狂飙 8 倍!
很多传统的后端程序员看到这条新闻,可能一头雾水:
在这些雾水和疑惑背后,隐藏着 AI 大模型时代最核心、也最残酷的技术真相:内存墙(Memory Wall)。

在传统的软件开发中,我们习惯了用 CPU 的思维去思考性能。我们认为程序跑得慢,是因为“计算太复杂”,我们需要更强的算力(更快的 CPU 频率)。
但在大语言模型(LLM)的世界里,逻辑变了。
大模型在生成文本时,是逐字生成(自回归)的。为了不每次都把前面说过的话重新计算一遍,模型会把之前所有上下文的内部特征(Key 和 Value 矩阵)全部保存在显存里。这份庞大的“运行记忆”,就是 KV Cache。
随着上下文越来越长(比如从 4K 飙升到 128K 甚至百万级),这份 KV Cache 会像滚雪球一样膨胀。
这就是为什么业界说:KV Cache 是大模型推理名副其实的“吞金兽”。
更要命的是,每次生成一个新的字,GPU 都必须把这份庞大的 KV Cache 从显存(HBM)完整地搬运到计算核心(SRAM)里过一遍。
这就好比你有一个世界上切菜最快的厨师(GPU 算力),但他每次切一片肉,都要跑到 10 公里外的仓库(显存)去取。厨师的手速再快也没有用,整体速度完全被运货卡车的速度(显存带宽)锁死了。
这就是困扰所有 AI 工程师的 “内存墙”。也是为什么各大公司疯狂抢购高显存、高带宽的 H100 显卡的原因。
而谷歌的 TurboQuant 之所以引发地震,正是因为它通过极致的数学算法(极坐标变换 + 1-bit 残差误差校验),直接在软件层面把搬运的数据量压缩了 6 倍!这意味着,同样的硬件,现在能跑更长的上下文、支持更高的并发。存储巨头们能不慌吗?
你可以说:“我只是个调 OpenAI 兼容API 的后端工程师,硬件底层关我什么事?”
在过去的一年里,这是行得通的。但随着开源模型(如 GLM、Qwen、MiniMax、DeepSeek、KIMI等)的全面爆发,以及企业对数据隐私、成本控制的极致追求,“本地化/私有化部署大模型” 也正在成为一些中大型企业的刚需。
当你作为架构师或后端主力,被老板要求把一个 70B 的大模型部署到公司的服务器上时,真正的挑战才刚刚开始:
如果你把 GPU 当成一个“跑得更快的 CPU”来用,你将会在上述每一个问题上栽大跟头。
你需要建立一套全新的“硬件心智模型”,这也是我编写这门《AI 工程师的 GPU 入门课:从硬件视角看大模型推理》微专栏的主要目标。
市面上关于 GPU 和 CUDA 的教程很多,但大多是教你如何写出复杂的 C++ 图形渲染代码,或者如何在学术上推导矩阵乘法。
这门微专栏与众不同。它是专为后端/软件工程师打造的“白盒化” GPU 入门课程。
我们不教图形渲染,不深究复杂的 C++ 语法。我们将直接切入大模型推理的痛点,带你一步步从物理架构走到前沿的 AI 工程技术。
为了让你对这趟旅程有一个清晰的预期,以下是本专栏的完整地图:
第一阶段:硬件心智模型
* 第 01 讲 | 硬件解剖:为什么 CPU 是“法拉利”,GPU 是“大巴车”?(含 5090 vs H100 对比)
* 第 02 讲 | 内存金字塔:HBM、SRAM 与不可逾越的“内存墙”
第二阶段:编程模型与工具链
* 第 03 讲 | CUDA 编程模型:指挥“千军万马”的线程艺术
* 第 04 讲 | 性能侦探:性能侦探:拆解 Hello World Kernel 与 Profiling 实战
第三阶段:AI 工程进阶
* 第 05 讲 | 显存管理革命:从 KV Cache 到 PagedAttention (vLLM)
* 第 06 讲 | 算子融合魔法:FlashAttention 的底层原理
* 第 07 讲 | 精度与量化:精度与量化:INT8/FP8 为什么既快又省?
* 第 08 讲 | 分布式推理:Tensor Parallelism (TP) 与通信墙
* 第 09 讲 | 终极指南:如何科学计算 AI 算力需求与硬件选型?
特别加餐:Gopher 的专属浪漫
* 第 10 讲 | 加餐:Go 语言的 GPU 编程——Gopher 的逆袭
在算力的装备竞赛里,最锋利的武器未必是更昂贵的芯片,而是深刻理解软硬件边界的人。
正如谷歌 TurboQuant 证明的那样:懂底层的工程师,只需改写一行底层逻辑,就可能撬动万亿级别的市场价值。
算力时代,不要只做“调包”的局外人。
准备好跨越 CPU 的舒适区,跟我一起深入算力的硅基心脏了吗?
点击这里或扫描下方二维码,开启你的GPU与AI推理工程的入门之旅:
我将在第一讲等你。
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。

原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。

© 2026, bigwhite. 版权所有.

2026 年 3 月 17 日,一位网友在社交平台 X 上这样写道:
坏结局:现在所有的游戏,都变成 AI 泔水(AI slop)了。
这里所指的,不是马斯克那个「全 AI 开发」的游戏,而是英伟达刚刚公布的一个技术预览。
这项技术预览,就是英伟达 GTC(GPU Technology Conference, GPU 技术大会)上公布的 DLSS 5:

▲ 图|Quartz
作为帮助老游戏和中低端显卡焕发新活力的技术,DLSS 在过去几年的口碑还算不错,为什么偏偏 DLSS 5「一石激起千层浪」了呢?
原因很简单:DLSS 5 跨过了「在原有画面上做加强」的底线,开始在游戏画面内叠加「基于 AI 模型生成的新细节了」。
经历过 2025 年末图像 AI 的野蛮生长之后,大家原本就对 AIGC 类内容的「入侵」高度敏感。
而英伟达在 DLSS 5 中尝试的技术路径,在大多数游戏玩家和开发者看来,刚好跨过了那条禁忌的边界线。

▲ 图|Nvidia
实际上,虽然 DLSS 5 因为 AIGC(AI 生成内容)而被大家炎上,但 DLSS 技术本身就是重度基于 AI 学习的,这一点从它的全称「深度学习超采样」就能看出。
但是,相比上一代的 DLSS 4/4.5,英伟达是这样介绍 DLSS 5 的:
DLSS 5 以游戏每一帧的色彩和运动矢量作为输入,并利用 AI 模型为场景注入逼真的光照和材质,这些光照和材质与源 3D 内容紧密关联,确保帧与帧之间的一致性。
其中最出格的,莫过于「利用 AI 模型注入逼真的光照和材质」——
这与 DLSS 4 的几个技术路线,比如多帧生成、光线重构、DLAA 等等,产生了质的差别。

▲ 图|Nvidia
实际上,如果根据英伟达自己的描述,DLSS 5 在处理的「目的」上相比 DLSS 4 就已经截然不同了——
DLSS 4 是在 GPU 有限的前提下,补全分辨率、帧率等等外围参数。
而 DLSS 5,则是以游戏生成的画面为基础,利用 AI 生成本来不存在的材质、光照和反射细节,让画面变得更具真实感:
…… DLSS 5 随后利用其深度理解能力,生成精准的图像,能够处理复杂的元素,例如皮肤的次表面散射、织物的微妙光泽以及头发上的光与材质的相互作用,同时保留原始场景的结构和语义。
更直白一点说——在 DLSS 4 的时候,如果画面原始帧里面,角色的牛仔裤没什么材质细节,处理之后顶多干净一点,但不会让牛仔布凭空变得更精细。
而打开 DLSS 5 之后,算法模型会知道「画面这里是一条牛仔裤」,然后主动加入更精细的牛仔布纹理和材质,哪怕游戏的模型贴图里没有这些细节。

▲ 图|YouTube @ElAnalistaDeBits
而英伟达作为硬件厂商,却跨过了从「加强细节」到「创造细节」的行为,结合之前对于 AI 泔水的反感,才引发了玩家、用户和开发商们的普遍担忧。
这种担心是不无道理的——
老黄又不是游戏创作者或开发商,英伟达越俎代庖之后,DLSS 5 改变了开发者原本想要呈现的画面效果怎么办?
而英伟达官网上的 DLSS 5 演示片,也侧面印证了一部分观众的担忧。
从目前版本的 demo 来看,DLSS 5 的确在「场景感」和「材质细节」上的确让游戏画面变得更真实了。
但抛开氛围不谈,DLSS 5 对于画面主体的修改却非常让人不安:

▲ 图|Nvidia
在官网 demo 中我们能够看到:格蕾丝的颧骨相比原始建模明显更突出了一些,嘴唇也变成了「Ins 风」的泡泡唇。
画面的第一观感,就是 FBI 青涩新人突然变成了在 Onlyfans 晒沙滩豪车大豪斯的欧美女网红——

▲ 图|Nvidia
甚至于这种「通过 AI 强行美化」的行为在英文里还有一个专门的说法,叫做 yassify ——

▲ 图|网络
当然,在看过那么多 AI 泔水之后,原因也不难猜测——
英伟达训练模型所使用的素材,无非是巨量的互联网数据,其中有多少 yassify 的「人造泔水」混进去影响了模型,英伟达既没办法知道、也很难控制。
而 DLSS 5 读取原始帧,感觉「这里有个人脸」之后,就会注入高颧骨、泡泡唇、影棚光等等原本不存在的要素,和原始画面混合在一起。
这种 「DLSS 幻觉」最明显的例子,则来自《星空》demo(超级小陶本人在 GTC 上表示非常支持 DLSS 5)。
原始画面中,人物打光明明是个硬顶光 + 面前漫光的组合,但 DLSS 5 打开之后,竟然凭空多出了一块右侧高光:

▲ 图|Nvidia
这种没有细节硬造细节的问题,正是大多数玩家对 DLSS 5 表示反对的原因。
哪怕老黄在公布当天,以及后续的采访中反复表示:
游戏开发者可以自由调节和修改 DLSS 5 细节,让处理后的画面符合原本的艺术风格。
也没能让大家放下心来。

但 DLSS 5 尚未正式发布,GTC 上展示的仅仅是个预览,开发者究竟能够以何种自由度对 DLSS 5 进行调节,仍然是个未知数。

只不过虽然网友们在过去 24 小时内制作了大量 DLSS 5 的梗图,但单纯从应用角度出发,DLSS 5 还是有一定可取之处的——
它的真正发挥空间,不是最近几年的新游戏,反而是一些使用旧引擎的经典作品。
尤其对于贝塞斯达(Bethesda)这类开发商来说,Creation 引擎因为历史原因导致角色建模诡异的问题,被玩家诟病已经不是一天两天了:

▲ 图|TheGamer
刚好在英伟达选出的 DLSS 5 演示里,就有来自《星空》的 demo。
除了增加莫须有的光源和颜色细节之外,我们不得不承认—— DLSS 5 还真让 Creation 引擎的 NPC 变得更「耐看」了一点……

▲ 图|Nvidia
当然,《星空》还是很新的游戏,如果 DLSS 5 能够被正确用在比如《辐射 4》或者《上古卷轴:湮灭重制版》里面,是的确能带来一些体验提升的。
前提是 DLSS 5 正式版发布的时候,能够把这个骇人的「动态画面 bug」给解决掉:

▲ 图|YouTube @Vex
总的来说,DLSS 5 有可取之处吗?
有。
至少以「纯技术」的视角来看,从之前 DLSS 单纯加强原始帧,转向通过 AI 理解画面内容然后针对性优化,在「某些特定情况下」,是可以让一些存在「技术限制」的游戏得到提升的……
比如,DLSS 5 虽然 AI 味精味溢出屏幕,但对冲一下,说不定能让《消逝的光芒 2》变得好接受一点:

▲ 图|SVG
只不过从上面连篇累牍的定语也能知道,现在仅从 DLSS 5 有限的演示片段来看,这东西依然是非常让人担忧的。
目前来看,玩家们最需要关注的,是英伟达能给游戏开发者们提供多少控制权限,以控制 DLSS 5 的算法。
而开发者也需要基于不同类型、不同美术风格、不同角色特点的游戏,有针对性地微调 DLSS 5,才能发挥出恰当的效果。

▲ 图|GamesRadar
但如果 DLSS 5 就是拿个固定的训练集往所有游戏上生搬硬套,那无疑是另一次 AI 泔水的向上污染。
但如果把目光放到 DLSS 5 以外,英伟达在本次 GTC 上释放出的信号,其实是没有脱离 DLSS 的本源的:
除了游戏开发者之外,计算机硬件同样可以参与到「游戏美学」的构建中,两者的重要性甚至不相上下。
如果 DLSS 1-4 解决的是分辨率和帧数问题,而 DLSS 5(如果发展顺利的话)解决画面质量问题,就提供了这样一种可能性——
开发者不再需要头疼由于引擎或者技术导致的各种「艺术审美」问题(比如首发版《赛博朋克 2077》),而是可以把精力放在玩法创新和剧情创作上。

换句话说:贝塞斯达万一出了支持 DLSS 5 甚至 DLSS 6 的老滚 5 重制版,依然可以支持曾经的 mod,而角色外观终于可以更现代化一些了。
那岂不是杯赛玩家狂喜?而老滚 6 又可以多苟几年。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

本文永久链接 – https://tonybai.com/2026/01/21/integrating-cuda-in-go
大家好,我是Tony Bai。
长期以来,高性能计算(HPC)和 GPU 编程似乎是 C++ 开发者的专属领地。Go 语言虽然在并发和服务端开发上表现卓越,但在触及 GPU 算力时,往往显得力不从心。
然而,在最近的 GopherCon 2025 上,软件架构师 Sam Burns 打破了这一刻板印象。他展示了如何通过 Go 和 CUDA 的结合,让 Gopher 也能轻松驾驭 GPU 的海量核心,实现惊人的并行计算能力。
本文将带你深入这场演讲的核心,从 GPU 的独特架构到内存模型,再通过一个完整的、可运行的矩阵乘法示例,手把手教你如何用 Go 驱动 NVIDIA 显卡释放澎湃算力。

在摩尔定律逐渐失效的今天,CPU 的单核性能提升已遇瓶颈。虽然 CPU 拥有极低的延迟、卓越的分支预测能力和巨大的缓存,但它的核心数量(通常在几十个量级)限制了其处理大规模并行任务的能力。

相比之下,GPU (Graphics Processing Unit) 走的是另一条路。它拥有成千上万个核心。虽然单个 GPU 核心的频率较低,且缺乏复杂的逻辑控制能力,但它们能同时处理海量简单的计算任务。这使得 GPU 成为以下场景的绝佳选择:

通过 Go 语言集成 CUDA,我们可以在享受 Go 语言高效开发体验(构建 API、微服务、调度逻辑)的同时,将最繁重的“脏活累活”卸载给 GPU,实现 CPU 负责逻辑,GPU 负责算力 的完美分工。
在编写代码之前,我们需要理解 GPU 的独特架构。Sam Burns 用一个形象的比喻描述了 GPU 的线程模型。如果说 CPU 是几位精通各种技能的“专家”,那么 GPU 就是一支纪律严明、规模庞大的“兵团”。

而指挥这支兵团的指令集,我们称之为 “内核” (Kernel)。
此 Kernel 非彼 Kernel(操作系统内核)。在 CUDA 语境下,Kernel 是一个运行在 GPU 上的函数。
当我们“启动”一个 Kernel 时,GPU 并不是简单地调用这个函数一次,而是同时启动成千上万个线程,每个线程都在独立执行这份相同的代码逻辑。每个线程通过读取自己独一无二的 ID(threadIdx),来决定自己该处理数据的哪一部分(比如图像的哪个像素,或矩阵的哪一行)。
理解了 Kernel,我们再看它是如何被调度执行的。CUDA 编程模型将计算任务分解为三个层级:


GPU 的内存架构比 CPU 更为复杂,理解它对于性能优化至关重要:
编写高效 CUDA 代码的秘诀,就是尽可能让数据停留在寄存器和共享内存中,减少对全局内存的访问。

理解了原理,现在让我们动手。我们将构建一个完整的 Go 项目,利用 GPU 并行计算两个矩阵的乘积。这个过程需要借助 CGO 作为桥梁。
go-cuda-cgo-demo/
├── main.go # Go 主程序 (CGO 入口,负责内存分配和调度)
├── matrix.cu # CUDA 内核代码 (在 GPU 上运行的 C++ 代码)
└── matrix.h # C 头文件 (声明导出函数,供 CGO 识别)
这是在 GPU 上运行的核心代码。我们定义一个 matrixMulKernel,每个线程利用自己的坐标 (x, y) 计算结果矩阵中的一个元素。
// matrix.cu
#include <cuda_runtime.h>
#include <stdio.h>
// CUDA Kernel: 每个线程计算 C[row][col] 的值
__global__ void matrixMulKernel(float *a, float *b, float *c, int width) {
// 根据 Block ID 和 Thread ID 计算当前线程的全局坐标
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < width && col < width) {
float sum = 0;
// 计算点积
for (int k = 0; k < width; k++) {
sum += a[row * width + k] * b[k * width + col];
}
c[row * width + col] = sum;
}
}
extern "C" {
// 供 Go 调用的 C 包装函数
// 负责显存分配、数据拷贝和内核启动
void runMatrixMul(float *h_a, float *h_b, float *h_c, int width) {
int size = width * width * sizeof(float);
float *d_a, *d_b, *d_c;
// 1. 分配 GPU 显存 (Device Memory)
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// 2. 将数据从 Host (CPU内存) 复制到 Device (GPU显存)
// 这一步通常是性能瓶颈,应尽量减少
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
// 3. 定义 Grid 和 Block 维度
// 每个 Block 包含 16x16 = 256 个线程
dim3 threadsPerBlock(16, 16);
// Grid 包含足够多的 Block 以覆盖整个矩阵
dim3 numBlocks((width + threadsPerBlock.x - 1) / threadsPerBlock.x,
(width + threadsPerBlock.y - 1) / threadsPerBlock.y);
// 4. 启动内核!成千上万个线程开始并行计算
matrixMulKernel<<<numBlocks, threadsPerBlock>>>(d_a, d_b, d_c, width);
// 5. 将计算结果从 Device 传回 Host
cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost);
// 6. 释放 GPU 内存
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
}
// matrix.h
#ifndef MATRIX_H
#define MATRIX_H
void runMatrixMul(float *a, float *b, float *c, int width);
#endif
在 Go 代码中,我们准备数据,并通过 CGO 调用 runMatrixMul。
// go-cuda-cgo-demo/main.go
package main
/*
#cgo LDFLAGS: -L. -lmatrix -L/usr/local/cuda/lib64 -lcudart
#include "matrix.h"
*/
import "C"
import (
"fmt"
"math/rand"
"time"
"unsafe"
)
const width = 1024 // 矩阵大小 1024x1024,共 100万次计算
func main() {
size := width * width
h_a := make([]float32, size)
h_b := make([]float32, size)
h_c := make([]float32, size)
// 初始化矩阵数据
rand.Seed(time.Now().UnixNano())
for i := 0; i < size; i++ {
h_a[i] = rand.Float32()
h_b[i] = rand.Float32()
}
fmt.Printf("Starting Matrix Multiplication (%dx%d) on GPU...\n", width, width)
start := time.Now()
// 调用 CUDA 函数
// 使用 unsafe.Pointer 获取切片的底层数组指针,传递给 C
C.runMatrixMul(
(*C.float)(unsafe.Pointer(&h_a[0])),
(*C.float)(unsafe.Pointer(&h_b[0])),
(*C.float)(unsafe.Pointer(&h_c[0])),
C.int(width),
)
// 注意:在更复杂的场景中,需要使用 runtime.KeepAlive(h_a)
// 来确保 Go GC 不会在 CGO 调用期间回收切片内存。
elapsed := time.Since(start)
fmt.Printf("Done. Time elapsed: %v\n", elapsed)
// 简单验证:检查左上角元素
fmt.Printf("Result[0][0] = %f\n", h_c[0])
}
前提:确保你的机器安装了 NVIDIA Driver 和 CUDA Toolkit。nvcc是CUDA编译器工具链,可以将基于CUDA的代码翻译为GPU机器码。
步骤一:编译 CUDA 代码
nvcc -c matrix.cu -o matrix.o
ar rcs libmatrix.a matrix.o
步骤二:编译 Go 程序
# 链接本地的 libmatrix.a 和系统的 CUDA 运行时库
go build -o gpu-cgo-demo main.go
步骤三:运行
./gpu-cgo-demo
预期输出:
Starting Matrix Multiplication (1024x1024) on GPU...
Done. Time elapsed: 611.815451ms
Result[0][0] = 262.440918
代码跑通只是第一步。Sam 推荐使用 NVIDIA 的 Nsight Systems (nsys) 来进行性能分析。你会发现,虽然 GPU 计算极快,但PCIe 总线的数据传输往往是最大的瓶颈。
优化黄金法则:
Go + CUDA 的组合,为 Go 语言打开了一扇通往高性能计算的大门。它证明了 Go 不仅是编写微服务的利器,同样可以成为驾驭底层硬件、构建计算密集型应用的强大工具。如果你正在处理大规模数据,不妨尝试将计算任务卸载给 GPU,你会发现,那个熟悉的蓝色 Gopher,也能拥有令人惊叹的爆发力。
资料链接:
本文涉及的示例源码可以在这里下载。
虽然 CGO 是连接 Go 和 C/C++ 的标准桥梁,但它也带来了编译速度变慢、工具链依赖等问题。有没有一种更“纯粹”的 Go 方式?
答案是有的。借助 PureGo 库,我们可以在不开启 CGO 的情况下,直接加载动态链接库 (.so / .dll) 并调用其中的符号。
让我们看看如何用 PureGo 重写上面的 main.go。
首先,我们需要将 CUDA 代码编译为共享对象 (.so),而不是静态库。
# 编译为共享库 libmatrix.so
nvcc -shared -Xcompiler -fPIC matrix.cu -o libmatrix.so
// go-cuda-purego-demo/main.go
package main
import (
"fmt"
"math/rand"
"runtime"
"time"
"github.com/ebitengine/purego"
)
const width = 1024
func main() {
// 1. 加载动态库
// 注意:在运行时,libmatrix.so 和 libcuder.so 必须在 LD_LIBRARY_PATH 中
libMatrix, err := purego.Dlopen("libmatrix.so", purego.RTLD_NOW|purego.RTLD_GLOBAL)
if err != nil {
panic(err)
}
// 还需要加载 CUDA 运行时库,因为 libmatrix 依赖它
_, err = purego.Dlopen("/usr/local/cuda/lib64/libcudart.so", purego.RTLD_NOW|purego.RTLD_GLOBAL)
if err != nil {
panic(err)
}
// 2. 注册 C 函数符号
var runMatrixMul func(a, b, c *float32, w int)
purego.RegisterLibFunc(&runMatrixMul, libMatrix, "runMatrixMul")
// 3. 准备数据 (与 CGO 版本相同)
size := width * width
h_a := make([]float32, size)
h_b := make([]float32, size)
h_c := make([]float32, size)
rand.Seed(time.Now().UnixNano())
for i := 0; i < size; i++ {
h_a[i] = rand.Float32()
h_b[i] = rand.Float32()
}
fmt.Println("Starting Matrix Multiplication via PureGo...")
start := time.Now()
// 4. 直接调用!无需 CGO 类型转换
runMatrixMul(&h_a[0], &h_b[0], &h_c[0], width)
// 5. 极其重要:保持内存存活
// PureGo 调用是纯汇编实现,Go GC 无法感知堆栈上的指针引用
// 必须显式保活,否则在计算期间 h_a 等可能被 GC 回收!
runtime.KeepAlive(h_a)
runtime.KeepAlive(h_b)
runtime.KeepAlive(h_c)
fmt.Printf("Done. Time: %v\n", time.Since(start))
fmt.Printf("Result[0][0] = %f\n", h_c[0])
}
# 无需 CGO,直接在go-cuda-purego-demo下运行
# 确保当前目录在 LD_LIBRARY_PATH 中
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:.
CGO_ENABLED=0 go run main.go
Starting Matrix Multiplication via PureGo...
Done. Time: 584.397195ms
Result[0][0] = 260.088806
优势:
注意:PureGo 方案虽然优雅,但也失去了 CGO 的部分类型安全检查,且需要开发者更小心地管理内存生命周期 (runtime.KeepAlive)。
你的“算力”狂想
Go + GPU 的组合,打破了我们对 Go 应用场景的想象边界。在你的业务场景中,有没有哪些计算密集型的任务(比如图像处理、复杂推荐算法、密码学计算)是目前 CPU 跑不动的?你是否会考虑用这种“混合动力”方案来重构它?
欢迎在评论区分享你的脑洞或实战计划! 让我们一起探索 Go 的算力极限。
如果这篇文章为你打开了高性能计算的大门,别忘了点个【赞】和【在看】,并转发给那个天天喊着“CPU 跑满了”的同事!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

AI 解决方案开发商 Tiny Corp 近日表示,AMD 在软件方面取得重大进步,已大幅缩小与 NVIDIA CUDA 系统的差距,甚至可能在 NVIDIA 出现技术失误时超越其在 AI 市场的主导地位。虽然 NVIDIA 目前在 2025 年第一季度取得 92% GPU 市场占有率,但 AMD 正通过 ROCm 平台快速赶上。
专注于开发消费端 AI 解决方案的 Tiny Corp 认为,AMD 在软件方面的进步已使其接近 NVIDIA 水平。该公司表示:“就像 Intel 在 CPU 领域一样,如果 NVIDIA 一代产品犯错误,AMD 就能获得大部分市场占有率,并且市场占有率转移比游戏领域更容易。”这观点在当前 AI GPU 竞争激烈背景下显得格外重要。虽然 NVIDIA 凭借强大 CUDA 生态系统长期占据主导地位,但 AMD 正通过 ROCm 平台迅速追赶。
AMD is closer to NVIDIA than most people think, we're working hard on the software gap.
— the tiny corp (@__tinygrad__) August 18, 2025
similar to Intel with CPUs, if NVIDIA stumbles for a generation AMD can capture majority market share. this is easier than gaming for market share to shift.
AMD 在 6 月“Advancing AI”活动中推出 ROCm 新版本,支持包括 vLLM v1、llm-d、SGLang 在内的多种增强框架,并专注于分布式推理、预填充等优化功能。据报告,ROCm 7 平台能将 AI 推理性能提升达 3.5 倍。AMD ROCm 7 主要关注推理工作负载,带来明显性能提升,特别是在 DeepSeek R1 FP8 吞吐量和增强训练性能方面,甚至声称其性能优于 NVIDIA CUDA。最新发布的 ROCm 6.4.3 版本进一步解决性能问题,修复通信操作中延迟问题。
AMD 计划在今年稍晚时间在基于 Ryzen 的笔记本电脑和工作站上开放 ROCm 支持,并提供 Linux 和 Windows 全面支持。这意味着 AMD 希望其 ROCm 平台能被更多用户使用,挑战 NVIDIA 在专业和消费市场的主导地位。行业竞争加剧另一例证是,中国 AI 团队最近在全球获奖,成功开发出以工业芯片替代 NVIDIA GPU 的视频生成 AI 模型,显示替代方案正在涌现。
虽然面临挑战,NVIDIA 在 2025 年第一季度市场表现依然强劲,其市场占有率较上季增加 8 个百分点,而 AMD 则下降 7.3 个百分点至 8%。不过随着 AMD ROCm 技术不断成熟,AI GPU 市场竞争格局可能出现变化。
GPU相关一些基础建设的常识
TPU,张量处理单元,主要是进行矩阵乘法计算
NPU,其实类似TPU,但是他是一种定制的计算规则,比如矩阵先乘后加,先加后乘,或者是更复杂的乘加乘加等等,相当于是定制化的计算单元,他是有适用的局限性的。如果专门为某个算法而生,那么这个算法就能吃满硬件加速,远超CPU或者TPU等其他方式实现的计算速率。
GPU,主攻并行计算,常常需要CPU指挥,广义上GPU是包含了TPU、NPU的,所以主力是强大的专业算力。
CPU,主攻逻辑运算,广义上CPU是可能会包含NPU和TPU,GPU的,但是多而不精,遇到一些专业问题,还是得专业的来搞。
但是,其实现在GPU的广义定义可能又发生改变了,英伟达新系列已经把一个小CPU作为协处理器融入到了GPU芯片中,这样GPU里就会包含CPU,因为在AI计算力,CPU不是大哥了,对于CPU的需求不是那么高,那么直接融一个ARM系列的GPU进去,显然是十分容易的。而且本身英伟达以前就做过客户端的ARM系列的CPU,这算是老树开新花了。
问一个模型,如果可以给无尽的资源,那么这个模型的训练、运行效率会被什么东西卡住。
目前来说,主要被限制的大概就是三个地方,GPU算力TOPS,GPU显存大小GB,GPU显存速率(如果显存无限大,可能没这个事情)。
粗浅的可以把模型分为训练和推理两个阶段:
训练相对推理来说,是更需要资源的,基本什么东西都要更好,更高的
推理阶段,往往是为了高并发,服务大规模使用者,而需要更大规模的GPU集群,但是模型本身可能只需要单GPU就能运行了。

NvLink,早年的NvLink主要是可以让双卡之间直接进行通信(NVLink Bridge),可以共享显存,而不需要走PCIe通道,让别人帮忙转发消息,这样速度非常快
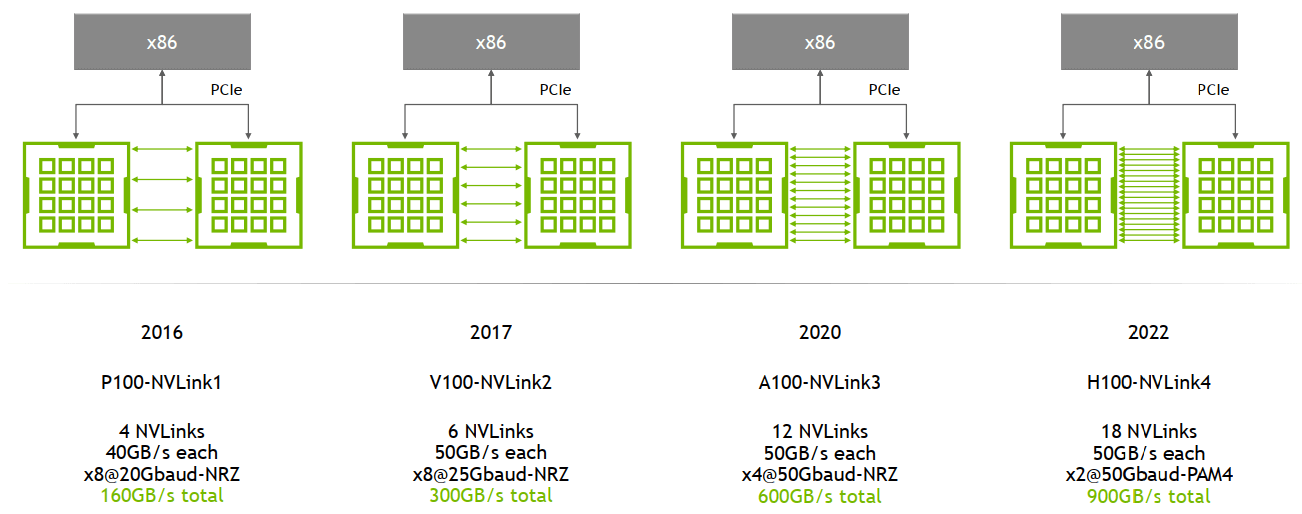
这样速度可以达到双向900GB/s,远超内存等速率,但是此时NvLink只能双卡,双卡的规模面对巨型AI来说,还是太小了,于是乎就有了后续NvSwitch。
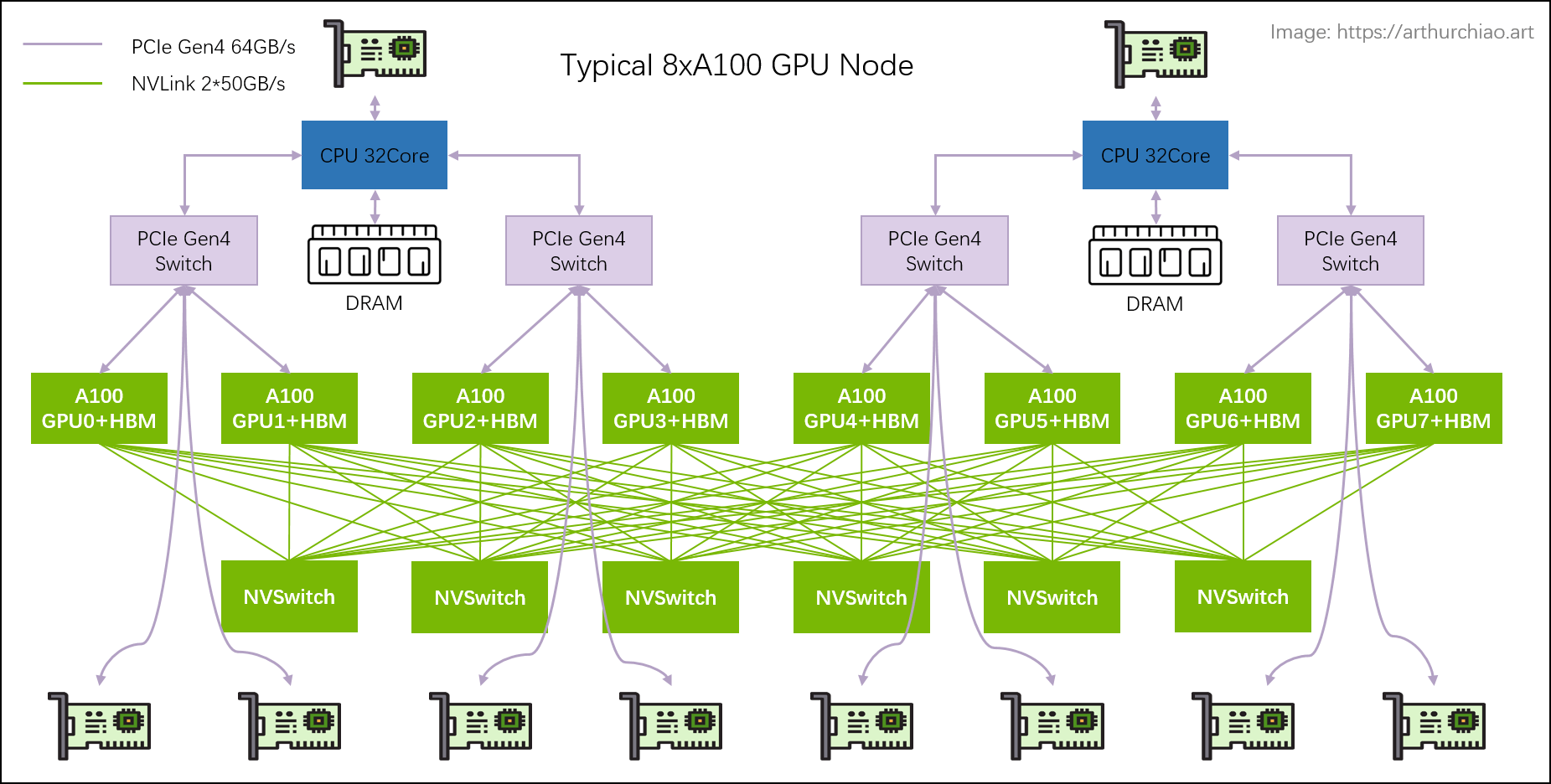
NvSwitch,就让原来的NvLink从双卡拓展到了8卡,8卡之间可以互相通信共享显存了。NvSwitch可以认为类似网络中的交换机,但是它实际上一个芯片模块,是直接在GPU主板上的。到了这个阶段,还是无法满足超级大显存的需求,于是乎又有了NvLink Switch。
NvLink Switch,他是真的变成了GPU的交换机,他变成了一个独立设备,用来跨主机连接不同的GPU集群。
除了NvLink这种英伟达自家的集群方案,还有一种就是通过网络来组集群,只是这种方式速度要比英伟达的方案慢一些
主要是说明数据链路级别的瓶颈
PCIe,目前最新是6.0,但是还没有实物,5.0才刚落地,速率大概是32GT/s,就算是6.0也才64GT/s,单通道是大概是7.876 GB/s,如果使用更多通道就可以*n,比如16通道就能达到126GB/s,单向速率也就是63GB/s。
DDR,目前最新是6.0,还是没实物,5.0落地一段时间了,速率大概是12800MT/s,明显比PCIe慢了许多
HBM,目前最新是3.0,速率大概是819 GB/s,比PCIe和DDR都要快很多,但是3.0还没落地,现在还是2E
阶段,速率大概是461GB/s,所以目前是GPU的首选内存
NvLink,起步就900GB/s了,甚至比HBM还快
Ethernet,目前落地的200Gb/s的网卡,只能达到25Gb/s的传输速率,整体比PCIe还是要慢一些的。
所以如果组集群或者涉及到多个GPU服务器之间通信,最后的瓶颈往往都落在了这个网络和GPU到PCIe的头上
抄个表格,这里只说了英伟达和华为,其实还有AMD和一些其他厂商,只是规模比起来有点小而已
| NVIDIA | HUAWEI | 功能 |
|---|---|---|
| GPU | NPU/GPU | 通用并行处理器 |
| NVLINK | HCCS | GPU 卡间高速互连技术 |
| InfiniBand | HCCN | RDMA 产品/工具 |
nvidia-smi |
npu-smi |
GPU 命令行工具 |
| CUDA | CANN | GPU 编程库 |
| DCGM | DCMI | GPU 底层编程库/接口,例如采集监控信息 |

比较关键的就是CANN/CUDA,他整体定义了整个GPU算力的计算逻辑,或者说你能发挥多少GPU算力,都取决于这里怎么实现。
不同的模型或者算法,底层计算逻辑可能是不一样的,需要结合硬件对算法进行优化、加速,那么英伟达就提出来了一种基于英伟达GPU的通用接口,只要你按照这个逻辑去调用GPU,就能完整发挥这个GPU的硬件性能,否则每次算法或者模型都需要对不同的GPU做适配,这不得累死。
CUDA就成了英伟达的护城河之一,CUDA在整个领域中占比可能有90%之多,之前AMD搞得兼容CUDA的兼容层,都是为了想办法抢一部分他的客户,你不兼容CUDA,那你就要重新写底层优化,那就不具备通用性,那谁愿意用呢。
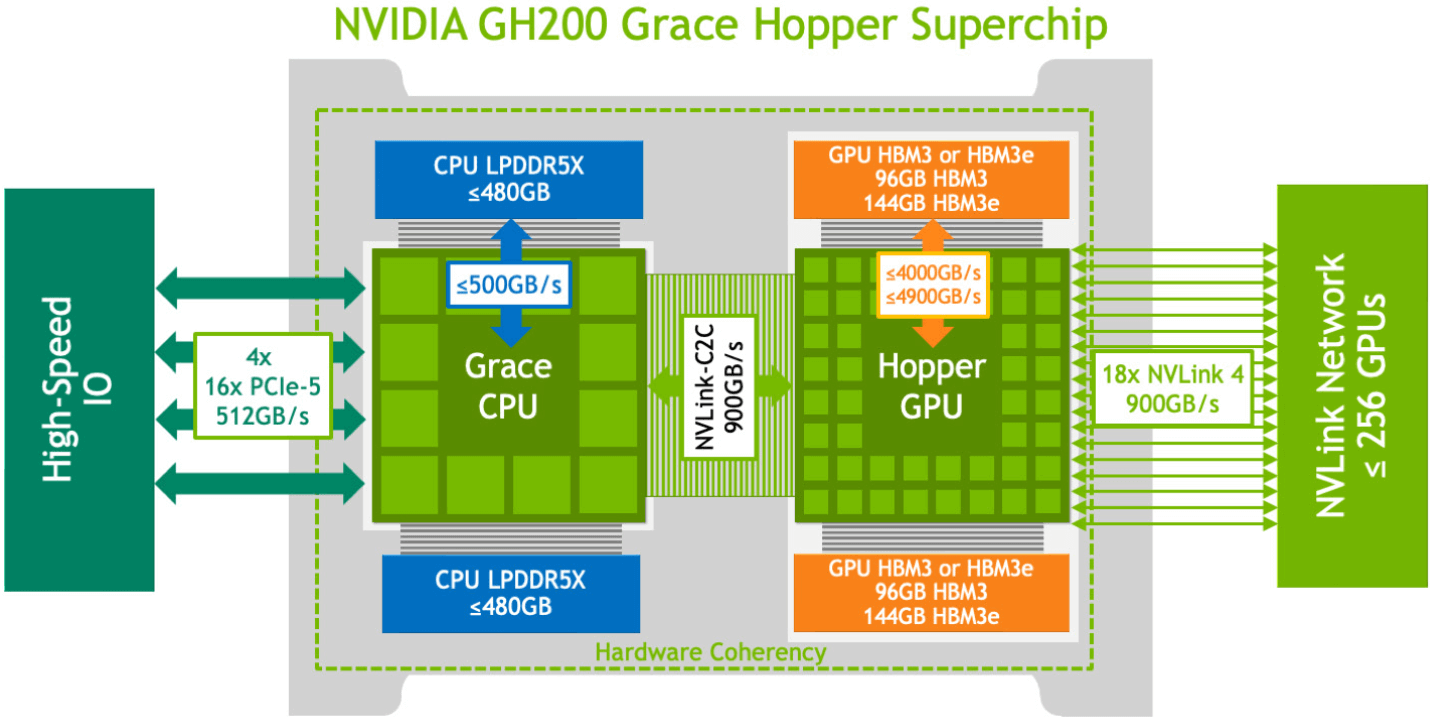
到GH200 这里,英伟达就意识到了之前服务器的局限,这里直接用自己的CPU和GPU,然后把内存也内置进去,然后这些内部访问都是可以直接通过NvLink的,不走什么PCIE了,相当于抛弃了传统服务器那一套东西,我自己玩了,充分降低了整个系统间互相通信的延迟。
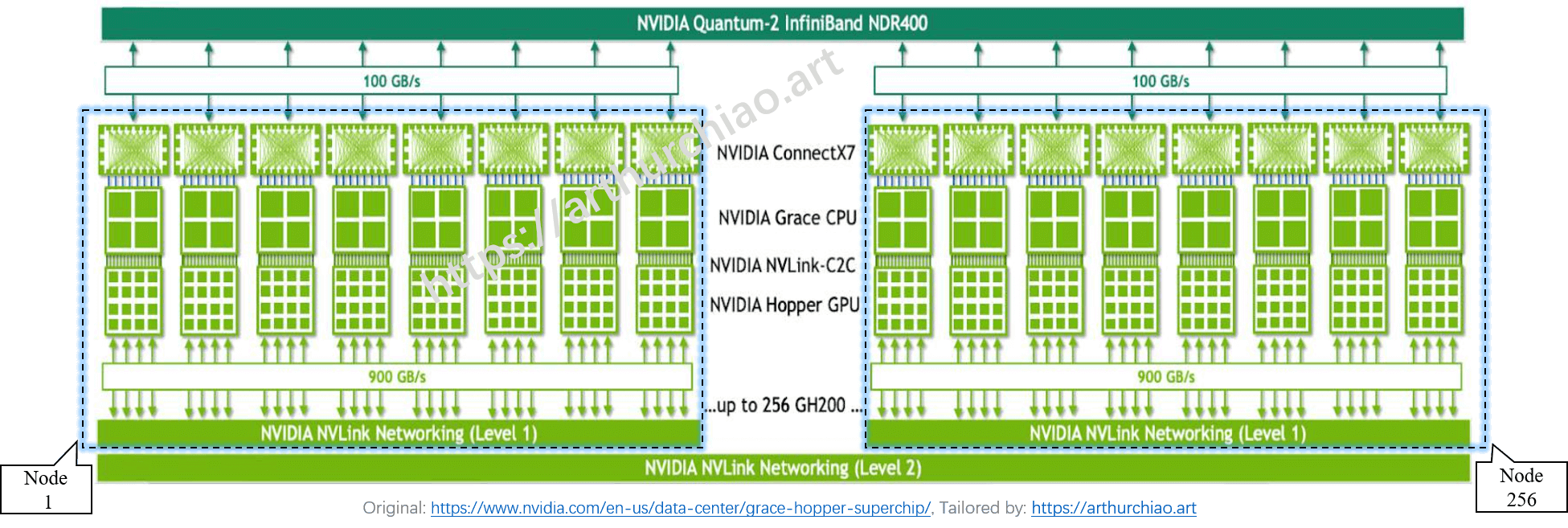
基于GH200 构建了一个机柜NVL32,他直接就能提供19.5TB的内存+显存,而且任意一个GPU都可以访问,而且还能再扩展显存。这个机柜还能再次组成集群,从而适用于超大规模的模型的训练和推理
后续有新发现再补充
arthurchiao.art写的很详尽,拿来入门很适合,作者应该是携程的赵亚楠,看他的blog里基础和翻译文比较多,下面几篇基础都写的挺好的,值得一看
https://arthurchiao.art/blog/gpu-advanced-notes-1-zh/
https://arthurchiao.art/blog/gpu-advanced-notes-2-zh/
https://arthurchiao.art/blog/gpu-advanced-notes-3-zh/
https://arthurchiao.art/blog/gpu-advanced-notes-4-zh/
https://developer.nvidia.com/zh-cn/blog/nvidia-nvlink-and-nvidia-nvswitch-supercharge-large-language-model-inference/
https://www.nvidia.cn/data-center/nvlink/
https://www.bilibili.com/video/BV1SZdwYTEM8
黄教主已经在CES上吹响了号角,准备好钱包了没有?大家好,欢迎收听老范讲故事的YouTube频道。今天咱们来讲一讲CES上,全村最靓的仔黄仁勋。黄教主都发布了一些什么东西?我们是不是要准备好钱包去买东西了,还是说咱们稍微冷静一下?
现在AI嘛,市值最高的公司英伟达,作为英伟达的老板,黄仁勋在整个的CES大会上一定是最靓的仔。其他做AI的人,可能还没有他这么风光亮丽。为什么呢?因为CES呢叫做消费电子展,那些做云计算的人,你们靠后站。黄教主是要来发布游戏显卡的,他是来玩消费的,这个还是有很大差别的。而且整个的AIGC玩了两年多,唯一挣着钱的就只有黄教主自己了,其他人都在这赔本赚吆喝呢。所以呢,人家一定要风光亮丽的跟大家做一个演讲。
咱们先看一下皮衣教主,因为他走到哪穿个皮衣嘛。他这个皮衣呢,这一次是一件新皮衣,不是以前穿过的这些旧皮衣。这个叫Tom Ford设计的一个皮衣,这个皮衣呢叫鳄鱼皮印花皮夹克。就是我们可以看到这个皮夹克上有很多非常大的花纹,这个东西呢叫鳄鱼皮印花。就是你如果买了什么鳄鱼皮钱包或者是鳄鱼皮的皮鞋,上面就是这种大花。我还真没见过鳄鱼皮夹克,他这个皮夹克呢应该不是鳄鱼皮的,应该是牛皮的,只是呢把这个大花纹给你印上了而已。
但是这个夹克也不便宜了,8,990美金一件夹克。但是这个对于现在全世界市值最高的公司的创始人和CEO来说,不穿这样的夹克,估计也真的压不住场子了。首先上来讲的第一个,肯定还是数据中心业务。虽然这是消费电子展,但是数据中心业务才是英伟达现在真正的核心价值。那么消费电子展呢,游戏显卡是跑不掉的,5090这个一定要上来好好跟大家show一下50系显卡。
然后呢,是整了一个非常奇怪的新品,叫project DigITs。这个东西长得像Mac mini那么大的一个超强算力的AI主机,因为看Mac mini卖的很好嘛。
所以,要出来跟大家show一下。后边呢,还做了一些软件部分的发布,这一部分基本上可以忽略不计。至于其他机器人的部分呢,2025年我们看到成品满街跑的,这个可能性也不大,所以我们就后边省略掉了。
首先,黄教主上来以后,先举着一个大盾牌,把一堆的芯片拼成盾牌那么大,就像美队一样,举着个盾牌就上来了。这个东西是什么呢?叫Grace Blackwell NV link 72。当然了,GBNV link 72呢,长得并不是真的这个样子,他只是说跟大家表演一下这个东西,把芯片铺开了应该是这样。
英伟达的显卡一般叫B开头的呢,就是它的GPU,就是Blackwell框架,黑井框架。说B200、B多少,这就是GPU;G开头的呢,实际上是CPU,叫Grace。这个东西呢,是ARM的CPU。所以呢,这个叫GBNV link 72呢,就是36个Grace CPU,加上72个Blackwell的GPU拼在一起,加上这种高速连接,整个拼一块儿以后,做的一个高性能运算的主机。大家可以在这个上面去训练模型。
它呢,现在只是把这些东西都拼成了一个盾牌的样子,给大家看一眼。如果真的是一个这个GB 72这种东西的话,它是举不上来的,那个机器拼在一起是1.5吨。但是消费电子展呢,给大家看这个意思不大,看过了就知道了。
现在数据中心是谁是老大?今天的真正重头戏5090、5090D、5080、5070,也就是50系显卡。前面的40系显卡、30系显卡,我电脑上是一个3060,我儿子电脑上是4070。什么时候会去长这个数呢?就是他的显卡的架构换了。40系的是A系的显卡,叫ADA的这个芯片;到50系呢,就是B系列的,就是Blackwell黑井系列的这个显卡。
它按照黑井系列整个架构重新设计的,所以呢,5090、5090D、5080、5070这些显卡,大家可以认为,跟我们现在去买的什么GB200或者B200这样的GPU吧,是一样的这个架构。
5090跟5090D的差异呢,就是5090的就是为中国生产的阉割版本。就跟原来美国制裁中国,说你们不可以去用4090了,中国就开始卖叫4090D。D呢,现在有两种说法,一种呢说是叫精简的,还有一种说法呢是Dragon,就是专门为龙设计的这个芯片。就是它里面的CUDA的核心数量、连接的这个速度,以及里面的这个内存的大小和连接速度,都是受到限制的一个设备。
当然,即使受到限制了呢,它也要比这个传统的4090还是要快的。这就是5090和5090D。然后5080和5070呢,要比5090 GPU的扩大的核心要更少一些,而且呢价格也相对来说比较便宜。现在呢,很多人就觉得天塌了,为什么?因为显卡这个东西呢,其实一直是作为一种金融产品,或者叫理财产品来去处理的,它有很强的金融属性。而这一次呢,黄教主干了一个事情,就是降价。他的5090呢,其实降的并不多,应该比4090还要贵一些的,但是呢,他号称说5070价格还是非常便宜的。对于原来那些囤4090的人来说,这个天就塌下来了。
整个的性能来说的话,我觉得我们就没有必要去跟大家讲说,它到底有多少CUDA核心,怎么算呢,这个其实没什么意义。它里边做了一个新的东西,叫大力水手4DLSS 4,可以在显卡内部进行更多的这种直插帧的运算。游戏原来输出的比较低的帧率、比较低的这个分辨率的这个图片,它可以通过插帧、插分辨率的这些功能,让我们看到一个非常非常高帧率、非常清晰的一个画面,是他们真的这个新功能。而大力水手4必须在50系显卡上才可以走,而这个40系显卡最高可以看到大力水手3.5。如果想使用大力水手4,你就要老老实实的去买50系的显卡。
也是很多人在去批判,说黄教主你这个刀法实在是很精准,也是如此了。有多少人需要去买5090呢?其实原来买4090的这些人,在挖币已经过时之后,他们到底能不能把这个4090的钱挣回来,其实是很难说的。
虽然他有金融属性,但是原来主要是拿他挖币。以太坊已经不用4090去挖币了,人家换了新的这种凭证方式了。那么4090可能也就是说,第一个打游戏用,第二个呢,拿它去做一些本地的渲染,或者是本地的大模型,比如说Stable Diffusion。我在本地跑一跑,也就干一些这样的事情。
那么现在上5090到底有没有这个需求呢?其实这一块的需求和动力是不足的。为什么呢?就是你在本地去用这样的一个设备,你真的需要那么大的分辨率、那么高的刷新率,然后有那么好的游戏吗?其实没有。游戏跟显卡之间呢,都是矛跟盾的两面,要来回翻来翻去的。首先是游戏更新了,然后说OK,我们现在需要更好的显卡,否则的话这个游戏跑不到最高帧率。
现在这几年呢,其实游戏并没有这样的东西出来。可能大家可以去期待一下GTA6,当然GTA他们一般优化做得还可以,所以呢,未必需要这么高规格的显卡才能带得动他。可能3060、3070都可以跑得起来,因为做游戏的人他也想清楚说,如果我做一款游戏只有5090才能玩的话,那我这游戏能卖几套?而且呢,游戏如果帧率太高的话,其实人眼已经看不到了,所以这个帧率是有极限的。而这个分辨率呢,其实你到4K也算是到极限了,你再往上其实已经做不上去了。
所以现在呢,其实在游戏这一块上说,需求动力不是那么足。至于说从大模型或者这一块来说呢,更多的人还是愿意去使用像A100、H100这样的专门的算力卡,而不是说来去使用这种游戏显卡。因为游戏显卡其实它的设计侧重还是不一样的,你拿这种东西去做大模型的话,并不那么划算。
50系列呢,到1月30号,5090的这个显卡就可以在外面买到了,可能要到3月份5080、5070的这些显卡会逐步的面世。再往后一段时间呢,会出笔记本用的50系显卡。现在呢,像什么ROG,这个叫败家之眼,他们已经在开始官宣他们搭配50系列显卡的这些笔记本了。
我估计在买到差不多得到年中了吧。5月份才能买到,而且以英伟达这个显卡升级的速度的话,我觉得可能过一两年再去买这个东西,也还是来得及的。一般是说显卡提升了以后,这帮做游戏的再想一想,说:“哎,我是不是可以再去做一些更复杂的游戏出来?”慢慢地去淘汰这个低端显卡,一般是这样的一个情况。这是今年的重头戏。
5090再往后呢,就发布了一个很奇怪的东西,叫project DigITs。这个东西呢叫做数字项目或者数据工程。我估计黄教主呢也是看旁边苹果整的Mac mini M4出尽了风头,这么小的主机,这么强的算力。很多人把它买回来去做大模型,甚至把几台M4 mini的这个主机拼在一起,还可以跑一些更大的模型出来。黄教主说:“这个我也行的。”这种设备呢,从结构设计上,甭管是谁设计的,但是从生产上来说呢,一定是台湾或者是大陆的这些果链企业去生产的。所以黄教主说:“你们谁去给我整个这玩意出来?”这个应该并没有什么难度。
黄教主这个时髦肯定还要改一下。那么它这个里边使用的芯片是什么呢?叫GB10。G就是CPU,它里头是有ARM CPU的;B呢是Blackwell的这个算力芯片,也都在里面。但是呢,GB10是没法去打游戏的,它没有这个图像渲染的能力,或者说它图像渲染的性能并没有那么好。大家主要还是要用它去做数据分析,去做大模型的训练和推理。
这个机器有128G的统一内存,这个还是很贵的一个东西。因为像我们在苹果上买统一内存,那玩意简直像金子做的一样,非常非常昂贵。你说我升硬盘,这个价格还可以接受,但是你要想给苹果的Mac mini或者是MacBook这种容易升内存,那真的是肉都疼。它这个里边128G的统一内存,4T的存储,这块不太值钱。然后里边的操作系统呢,是英伟达自己定制的一个操作系统,在乌班图的基础上去改的一个Linux操作系统。据说呢是可以跑200B的模型,这个已经是非常非常吓人了。
像我现在的MacBook只能跑三十几B的,72B的已经跑不起来。他这可以跑200B的模型,如果把两台连接在一起,就直接可以跑405B。因为现在我们有一个405B的模型,就是Llama3 405B,你们两个串一块就可以跑了。这个还是很吓人的。
当然,价格呢,肯定也得对得起它这些高端配置,3,000美金可真的是一点都不便宜。Mac mini应该是500美金还是600美金开始吧,最高的这个款式大概可能到不了2,000美金。他这个直接上来就3,000美金,这个大家自己看着办。
但是呢,发布会上有一些东西是没说的。什么东西没说呢?就是这个设备的功率和散热到底怎么样,他没说。英伟达向来不是以省电著称的,英伟达一直都是非常非常耗电的。像我们前面讲的5090什么这种东西,经常是可能五六百瓦。但是他这样的一个GB10的芯片,塞了这么点的一个机器里头,到底是有多少功率?到底是需要配多大的风扇?这个东西能有多吵,大家可能心里要有一个准备。
当然了,你想3,000美金我都花了,如果想动小了的话,可能很多人会觉得我这个钱没有花到地方。我花了钱以后,第一个重量要够。这个英伟达的老黄还是非常非常有经验的。你们去看那个4090也好,5090也好,那个显卡那么老大个,你把这个显卡拿起来,也是贼沉贼沉的。为什么?因为都是巨大的散热铜管以及风扇,还有很多的金属散热片。所以那个东西非常非常的重。
现在它发布了这样的小型主机,这个到底有多重?到底有多么吵闹?大家自己去思考一下。还有一个问题他没说是什么呢?就是这个东西到底能不能出口中国,这事不知道。刚才5090的时候我们讲了,专门得设计一个叫5090D的东西,是可以出口到中国的。5090的咱们中国的游戏玩家们就别想了。project digITs到底能不能到往中国出口,还得要再等一等,看这个东西也没有那么快了,应该还要再等几个月。
现在我们就是看一个形状就可以了。那么好了,大家是不是应该把钱包掏出来看一看了?我们到底是不是应该要去买这些东西了呢?什么人真正适合去买这个 Project DigITs 呢?
第一个,如果你是有钱人,这个不需要理由,只管买就完了。哪怕买完了以后,你从来都不开机,供奉在那里没毛病。你说我为什么供奉这么个东西在那呢?为你这个仓里边的满仓英伟达股票去祈祷一下不好吗?英伟达这个发布会发完了以后,老黄直接身价上升了,因为股票在暴涨。他已经是世界市值第一的公司了,基本上股票还在三个点几个点蹭蹭涨上去,这是多么神奇的事情。
那你有钱人说我买一个摆家里供起来,没毛病。至于其他的人呢,就真的没必要买这东西了。为什么呢?首先要注意,它里边用的操作系统是一个拿乌班图修改过的定制操作系统,一个用户量不大的操作系统,各种兼容性问题可以把普通用户折腾死。如果你说我不是一个专门的工程师,我就是一个使用 Mac 的用户,或者使用 Windows 的这种桌面用户的话,你就别用这玩意了,这个不是一般人能搞得定的,只有工程师才可以使用这种定制操作系统。
为什么呢?因为它各种的软硬件的配套以及升级,还有这种兼容性都很麻烦。如果真的需要进行大模型训练或者数据分析,这些人说是不是应该去买呢?因为老黄在上面讲了说,我们就是为他们设计的。建议呢,你们还是老老实实的去买通道式服务器。就算你想在家里干这个事,你也去买那个通道式服务器。
为什么呢?因为通道式服务器和 Project DigITs 这种东西,它都是非常非常吵闹的。你要想发挥出这么多算力来,你再怎么设计,它这个功率还是在这的,还是要去散热的。那你干脆就用通道式服务器就完事了,就把它塞到车库、地下室、阁楼,反正这种地方,因为这样的东西,它不适合放在卧室、起居室或者是客厅里边,因为太吵了。而且呢,做这种大模型训练的人最好是用云端的服务器,不要放家里头。
就算是你的数据非常非常的保密,非常敏感,也不建议你在家里边去部署这种东西。为什么呢?因为咱们使用这样的设备呢,都是临时性的,不可能说我一天24小时不停地算这个东西,从来不停,这个事的可能性非常非常小。你可能连续算一周,或者算两周,算完了以后呢,你还是要停下来的。
如果用云计算的这个机房,你只需要为这一两周的时间买单,就可以了。剩下的时间你就不用管它了。那么云计算的这些服务商,就可以把这个主机租给别人了,这个还是非常开心的一件事情。那你说:“哎,我把这东西买回来搁这了。”那你如果不用的时候,难道不是觉得心疼吗?
像这样的主机,正常情况下,如果没有那么高负载的时候,可能也很安静。但是你一看到这个东西很安静的时候,你就想:“哎呀,我这3,000美金是不是花亏了呢?”家里的骡子和马都歇了,这事不行。他会有这样的心理矛盾在这里。
即使你真的是数据科学家,也必须要配一个IT维护工程师,否则你真的没法使这种设备。你就想吧,各种软件的安装,硬件的兼容,这个是很麻烦的。如果我们在云主机上用这个东西,我们是怎么来干这个事的?我们是使用刀客各种镜像来干活的。
这个什么意思呢?就是我们随时需要云主机的时候,我们去跟服务商说:“来,给我搞台新机器来。”然后他把新机器给你了,你就告诉他说:“请按照什么什么样的方式,给我把这个环境搭建好用。”用完了以后呢,说:“现在请回收这台主机。”这个主机就又变成干干净净的了。你下次什么时候再用,你再去跟他说:“哎,给我再去整一台空机器出来。”他再给你整一个干干净净的机器,重新部署。
这个是我们使用云主机的方式。但是我们要想一想,我们用桌面电脑是什么样的方式?那个电脑多长时间格式化一次,多长时间重装一次系统?像我们用麦克的这些人,可能三五年吧,会重装一次系统,这个是正常的。为什么呢?因为这个系统变化相对来说比较少,不会天天的变来变去的。但是这些数据科学家,可能今天我需要用一个这个插件,明天需要用一个那个组件。
这个东西还不停地升级。那你这个玩意儿怎么弄?你就需要不停地格式化电脑,不停地重装电脑。如果没有一个IT工程师跟着你的话,根本搞不定这个事情。就算是正常开机的云主机,我们多长时间格式化一次?可能真的是每个月或者每周,你都会去格式化它。为什么?因为我们需要去维护这个电脑,需要去升级系统。那升级系统你再看看,哎呀,这个升级的东西跟那个兼不兼容,不费劲啊,整个格式化干净,重新整一次就完事了。这是使用云主机的方式。所以没有工程师去维护的话,这个东西摆家里一点意义都没有。
那么最终的结论是什么呢?就是光鲜亮丽的小废物。这个project Digits就算是一个光鲜亮丽的小废物,非常非常贵。如果我们赶个时髦,整一个放家里头,摆起来供起来,平时也没有什么任务让它跑,这个没毛病。你只要有这个钱,没有人能够说你什么。如果你真的想用它,那就算了,趁早打消这个念头。
至于说5090这些东西呢,我觉得你如果真爱的话就去买。现在应该没有什么游戏是必须要5090才能跑起来的。如果你说我一定要去玩stable diffusion,去画一些画,或者我要去做一些渲染的话,哼,也建议用云主机,不要用5090这样的东西出来跑。
所以呢,现在英伟达发布的这些东西,建议大家谨慎购买。至于软件的部分,虽然现在英伟达也在努力的开源,就是他现在新出了一些东西,都是open source的,但是呢,英伟达的软件除非像CUDA那样,一开始在非常小众的领域里头深耕很多年,否则不建议大家去碰这个玩意儿。为什么呢?因为英伟达的软件,用户交互这块是比较差的。英伟达向来不以用户交互这个事情见长,他们都是一帮资深的黑客,一帮这样的工程师范的人。他们认为所有人都应该是工程师。你像刚才我们讲的这个project Digits,这样的东西,如果不是工程师,你根本搞不定这个东西。如果是我整这么一个东西,可能我也得平时把它放在柜子里。
需要去做一些模型。微跳模型训练的时候,把它请出来。机器格式化,整个重装好,然后把一个任务跑完了以后,再重新盖到盒子里头,装柜子里头完事。这个才是他的正常使用方式。等下一次再把他请出来的时候,重新再隔热化机器,重新装系统,这个才可以去正常工作。
所以呢,因为他向来不是给普通用户来用的。就算是你说:“哎,我游戏显卡,难道不是给普通用户用的吗?”是,但是你玩的是显卡的吗?不是,你玩的是游戏。游戏跟显卡之间还是通过各种SDK、各种程序接口在打交道。我们普通人,是不跟那个玩意儿打交道的。而且呢,所有短平快在热点上搞的软件,都不是英伟达擅长的事情。
所以软件呢,跟今天咱们讲的CES消费电子展,这个事就没有什么关系了。就算你说:“我是玩大模型的,我是科学家,我是工程师。”这个事情呢,你可以去进行部署,可以去使用。但是英伟达做的相应的软件呢,特别是在这种热门的领域里头,也建议大家先去使用其他家的,先别用他们家的。因为这些年来,在大模型里头推出的各种软件,其实都没有怎么流行起来。现在大家使的,其实依然是CUDA这个东西。一抽遭蛇咬,十年怕井绳。CUDA大家使习惯了以后,最后就没有办法被他绑架了,必须要使,因为大家继续使下去。
现在老黄就算是摆出再怎么人畜无害的这种表情来,也没有人敢用他们家东西,而且真的不好使。所以在这一块里头,有非常非常多其他公司的这种替代产品、替代的架构可以去用。
好,这就是今天咱们讲的英伟达。黄仁勋穿着他的印花鳄鱼皮夹克,给大家发布的这些东西。然后钱包呢,捂好了,稍微关注一下。特别是project Digits这样的东西,3,000美金对于我来说是比较贵了,可能对于很多人来说好像也不是很贵。但是你先想想你用的了这玩意不?你说如果我摆着,就是为了让英伟达的股票好好的再涨一涨,那你去买,其他的就先别买这东西了。
好,这期就跟大家讲到这里,感谢大家收听,请帮忙点赞,点小铃铛。
参加Discord讨论群。也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。