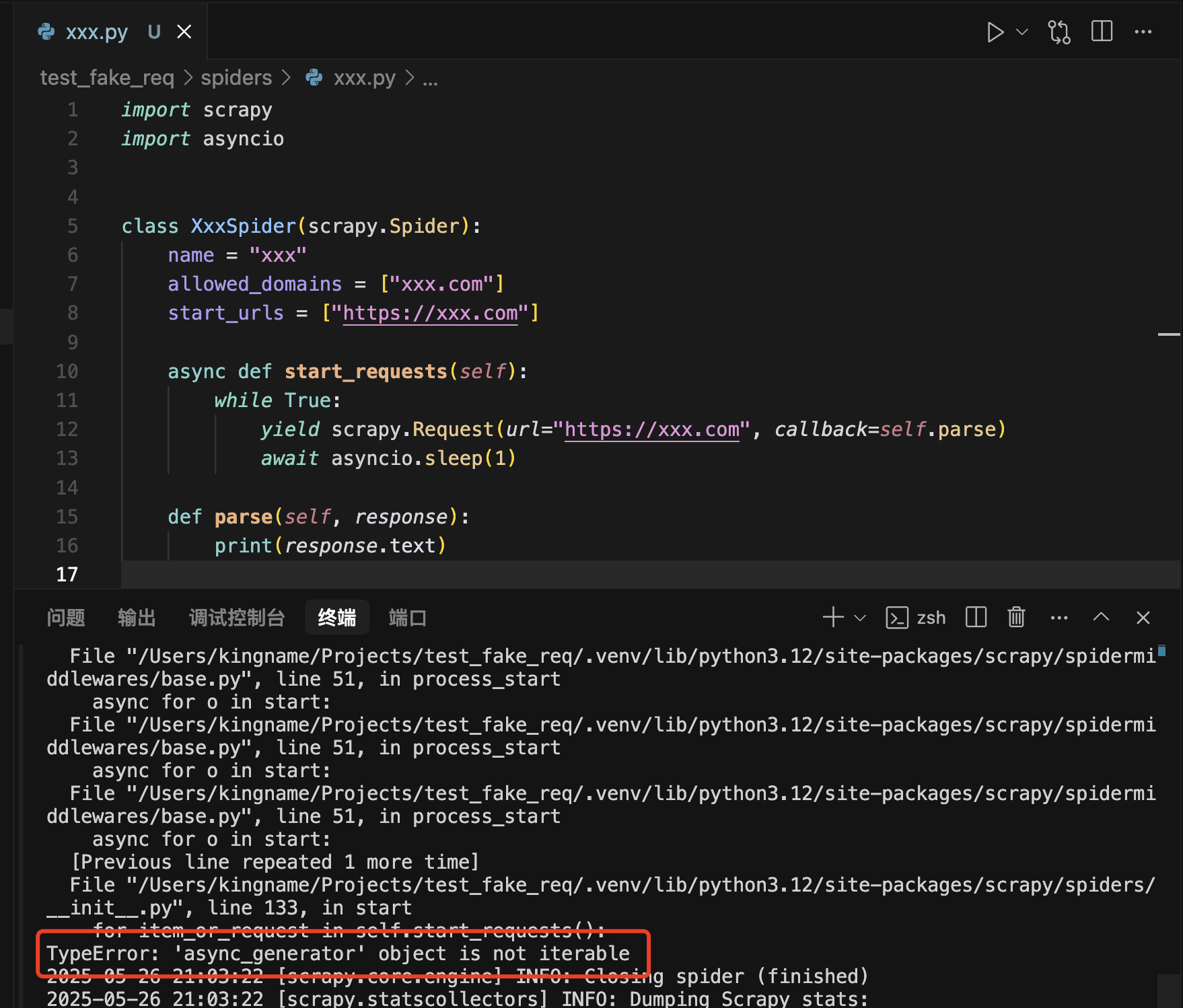
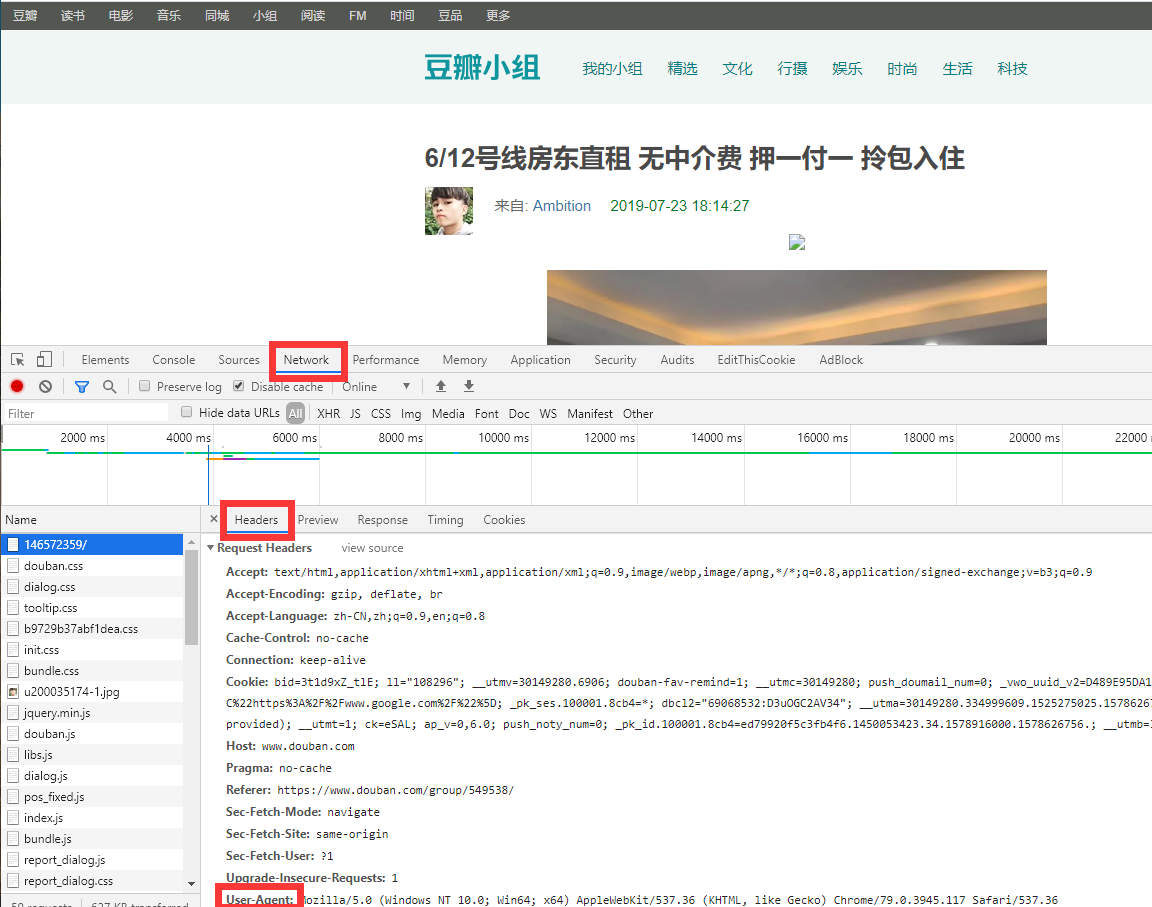
def parse(self, response):
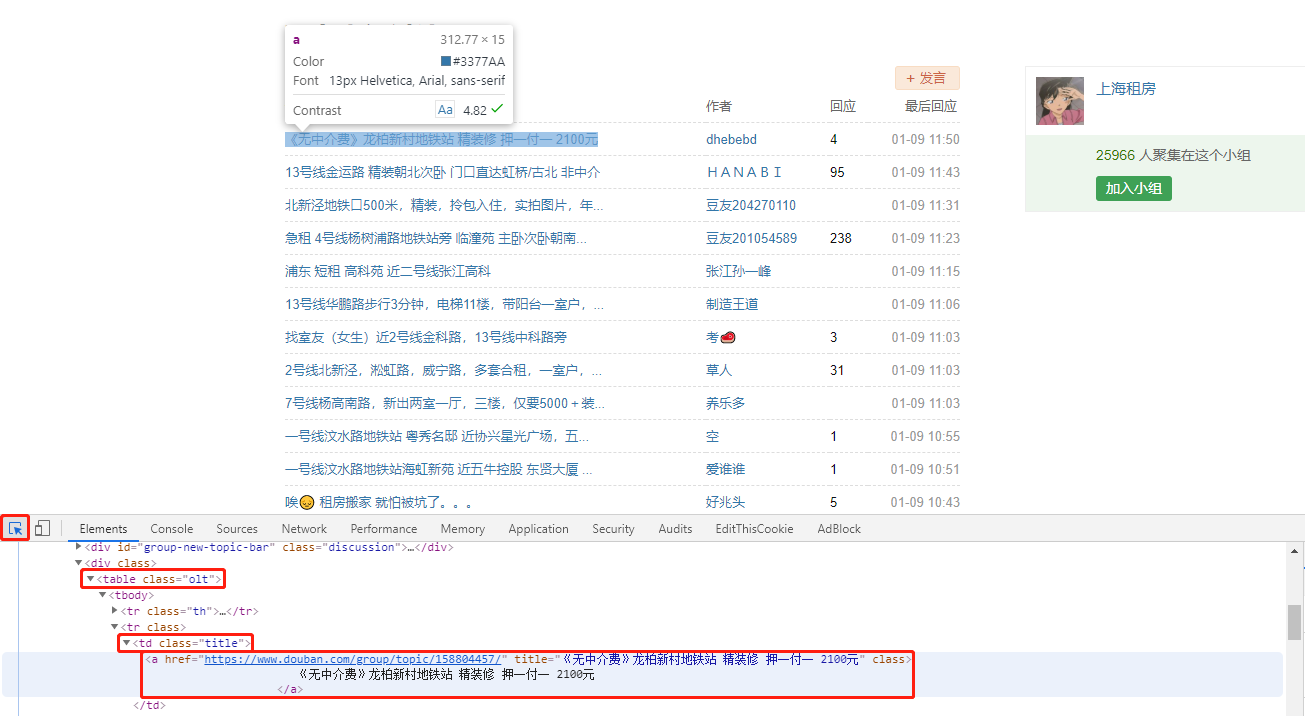
for title in response.css('.olt .title'):
yield {'title': title.css('a::text').getall(), 'link': title.css('a::attr(href)').getall()}
这个方法的含义是获取 olt 的子元素 title 下的 a 标签的文本和 href 属性,即内容和链接。getall 代表获取符合上述条件的所有元素的内容和链接。
到这里,爬取的功能已经全部编写完毕了,一共是 7 行代码。但我们所需要的功能是在获取到新发布的帖子的信息时,收到推送或提醒。Scrapy 中内置了 mail 模块,可以很轻松地实现定时发送邮件的功能。那我们可以考虑先把爬取到的信息存储到文件中进行分析,再将由关键词筛选得到的信息与上一次筛选过后的信息进行比较,如果存在更新,就更新存储筛选信息的文件,并发送邮件。我们可以用以下的命令来将爬取到的信息输入到 JSON 文件中:
scrapy crawl douban -o douban.json
既然需要定时执行,那我们就需要在根目录中创建一个 douban_main.py,用 time 库编写一个简单的定时器,用以爬取之前清空存储爬取信息的文件,并每 21600 秒(6 个小时)执行一次爬取分析:
import time, os
while True:
if os.path.exists("douban.json"):
with open("douban.json",'r+') as f:
f.truncate()
os.system("scrapy crawl douban -o douban.json")
time.sleep(21600)
最后,我们需要指定一些关键词,为了便于理解,匹配的写法比较简易,注重性能的朋友们可以使用正则匹配。注意每次分析完毕之后,我们将迄今为止出现的符合关键词的信息写入到 douban_store.json 中,并在新信息出现时保持更新。这个过程写在爬虫程序结束之后调用的 close 方法中。附上 douban.py 的所有内容:
# -*- coding: utf-8 -*-
import scrapy, json, os
from scrapy.mail import MailSender
class DoubanSpider(scrapy.Spider):
name = 'douban'
def start_requests(self):
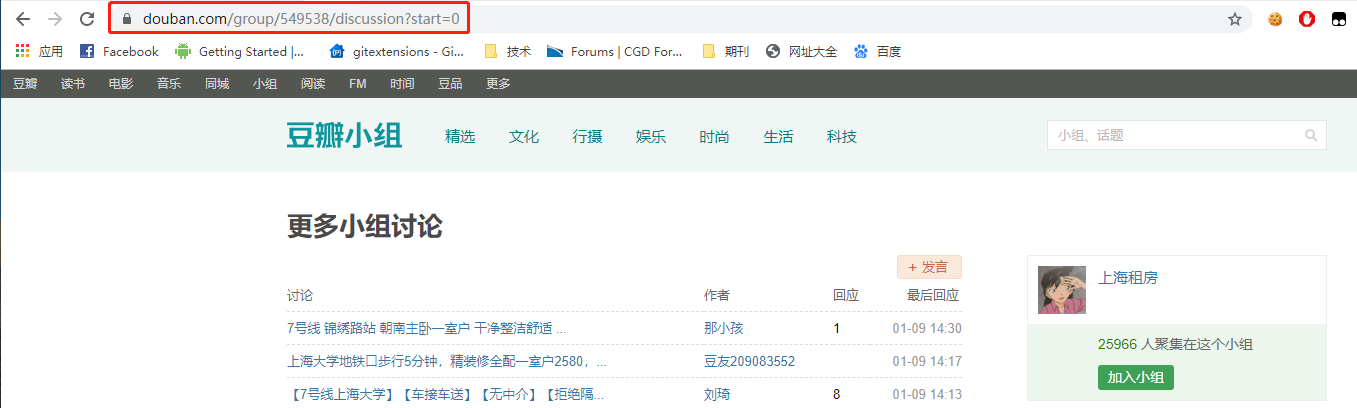
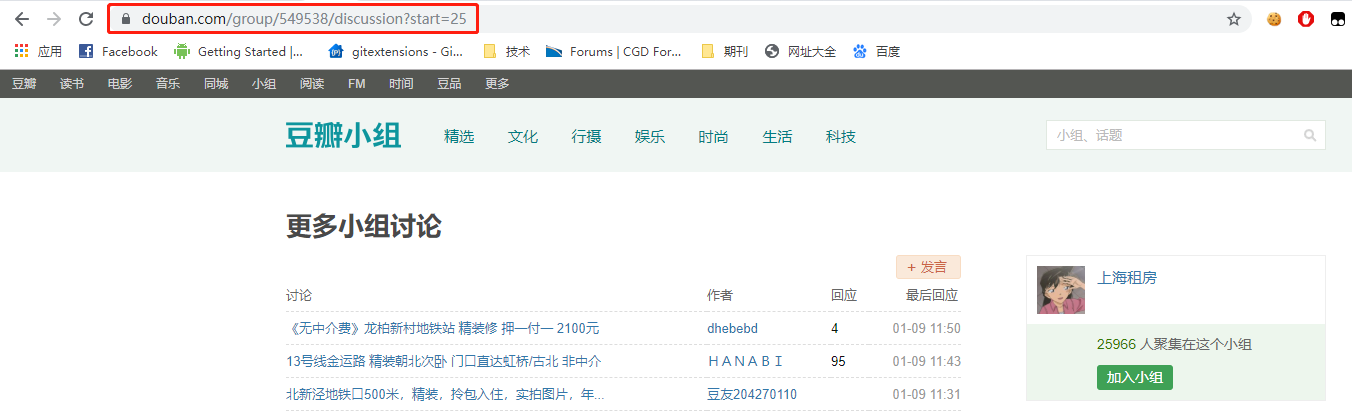
for i in range(0, 5 * 25, 25):
url = 'https://www.douban.com/group/549538/discussion?start={page}'.format(page=i)
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for title in response.css('.olt .title'):
yield {'title': title.css('a::text').getall(), 'link': title.css('a::attr(href)').getall()}
def close(self):
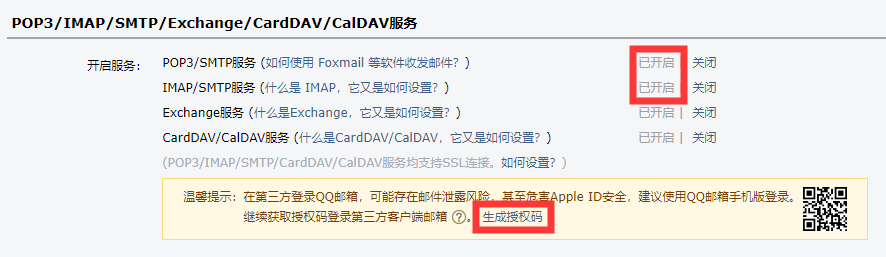
mailer = MailSender(
smtphost="smtp.qq.com",
mailfrom="xxxxxx@qq.com",
smtpuser="xxxxxx@qq.com",
smtppass="xxxxxxxxxxxxx",
smtpssl=True,
smtpport=465
) # 配置邮箱
obj_store, new_info = [], []
key_words = ['枫桥路', '曹杨路', '11 号线']
if os.path.exists("D:\\ForumSpider\\douban_store.json"):
with open("D:\\ForumSpider\\douban_store.json", 'r') as f:
obj_store = json.load(f) # 读取之前爬取的符合关键词的信息
with open("D:\\ForumSpider\\douban.json", 'r') as load_f:
load_dict = json.load(load_f)
for info in load_dict:
content = info["title"][0].replace('\n', '').replace('\r', '').strip() #按标题进行筛选
for k in key_words:
if k in content:
tmp = {"title": content, "link": info["link"][0]}
if tmp not in obj_store: # 如果之前的爬取没有遇到过,则加入到新信息列表
new_info.append(tmp)
obj_store.append(tmp)
if len(new_info) > 0:
with open("D:\\ForumSpider\\douban_store.json", 'w') as writer:
json.dump(obj_store, writer) # 更新到旧信息列表
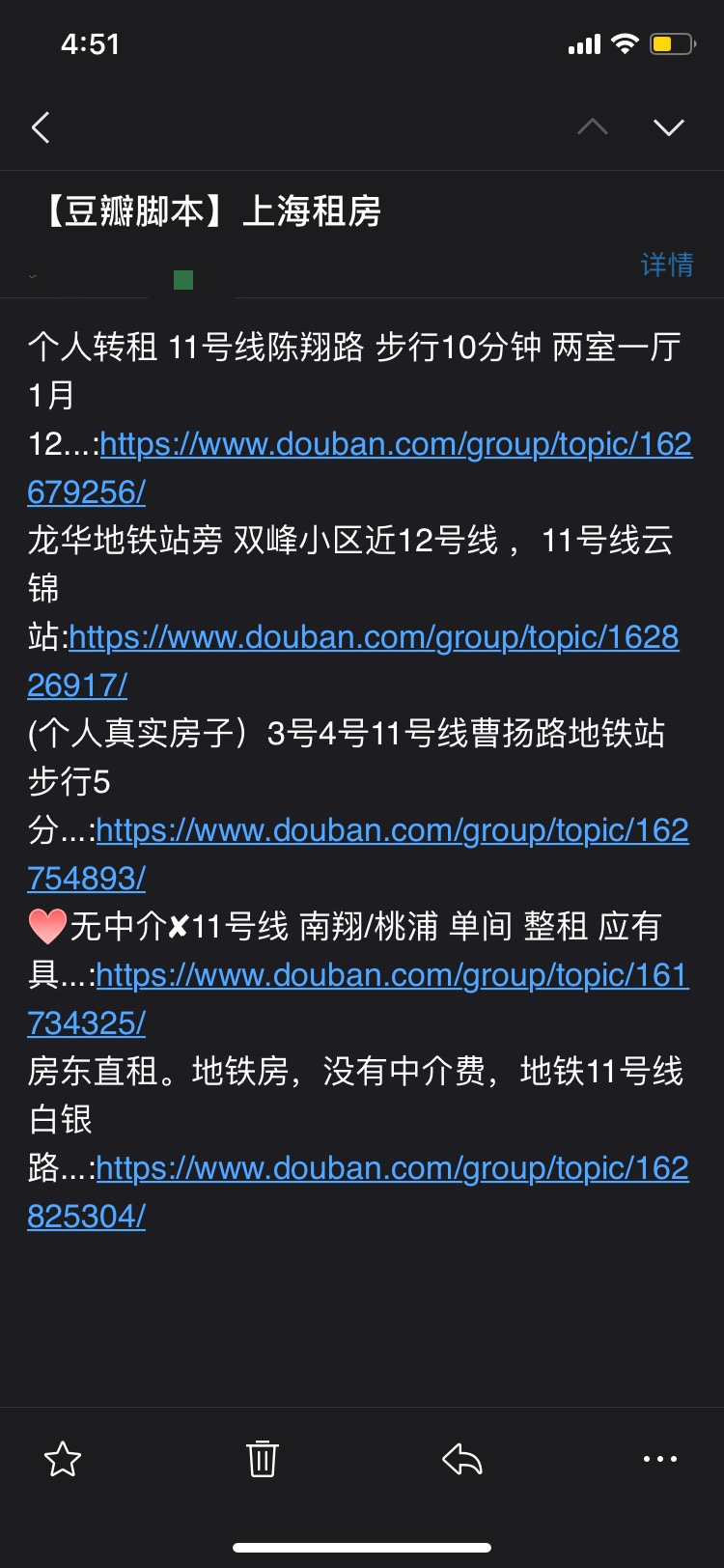
return mailer.send( # 发送邮件
to=['lolilukia@foxmail.com'],
subject='【豆瓣脚本】上海租房',
body='\n'.join([str(x['title'] + ':' + x['link']) for x in new_info])
)