本文中,我们简单介绍了 VoIP,并研究了 VoIP 中影响通话质量的问题表现、原因,也讨论了几种对于此问题的解决方法。语音通话是一项要求强实时性的业务,用户可以忍受一定程度上的丢帧,我们必须在延迟和丢帧影响上做平衡。因此,也许我们可以使用更好的方法处理丢帧问题,但由于会引入延迟、消耗算力,实际应用中有时不会采用这些方法。
本文并未深入介绍 VoIP 的相关原理,也只提到了几种解决丢帧问题的方法。在这些方法之外,还有其他从信号处理或人工智能角度解决问题的方法,有兴趣的读者可以自行了解。
第一件事是和 panda 去了一趟成都,在当地群友的带领下广泛地尝试了各种当地特色食物,体验极佳。后来又去了一趟武汉,算是亲眼看到了疫情之后的武汉的样子。由于自己也是湖北人,在山里疫情都有如此严重的程度,其实很难想象武汉的实际情况。但 7 月再去的时候,武汉看起来缓了过来,看上去街上的人都在正常生活,除了随处可见的关张的门面提示着经济的崩溃。这次旅行和朋友同行,一路确实很开心,缓解了一些疫情期间积累起来的压力。
不过在浑浑噩噩的生活里,也有一些好事发生。这学期里也吃了不少好吃的东西,并且尝试着开始在空间里连载美食博主 KS 系列说说。认识了一个在做游戏的学长,并且在学长的建议下蹭到了软件学院万老师的图形学课程,发现自己对图形学的兴趣很大,也因此确定了未来发展的方向,同时也增加了一些压力,因为可能需要读一个硕士研究生。另外就是抽空去考取了业余无线电操作证书,开始了作为 HAM 的活动,包括接收 ISS 下发的 SSTV 图片和借助卫星远距离通信。我觉得这些兴趣与技能的发现确实比较突兀,不知道为什么就去接触了这些事情,觉得很好玩于是就做了下去。此外,这学期对信件和无线电通信的兴趣也说明我比较喜欢仪式感,信件上的邮戳和获得许可、进行合法的通信都可以看成是仪式感的来源。
此外,本学期中特别关注的一点事是自己飞速增长的物质欲与消费欲。我不清楚是否是疫情期间许多愿望无法满足的原因,还是获得了一些可支配收入的原因,在整个学期中各种广告与念头对我的吸引力大幅提升了,也因此冲动消费了好几次。不过好在我还是以比较理性的状态面对这件事情的,不至于刷爆花呗到还不起的地步,但也同时需要做其他的努力来填补冲动消费带来的空缺了。目前看来,还好我对自己还是有一点 B 树的,消费都在可以承受的范围内,且欲望没有无限膨胀。
蒙特卡洛方法往往需要均匀分布在一定空间中的随机数,准随机数生成器(Quasi-Random Number Generator,QRNG)便是用于生成这样一系列随机数的工具。具体而言,常用的准随机数序列包括:Halton 序列、Sobol 序列等。[6][7]这些序列在选取不同参数时,呈现出低相关性,因此可以用于生成随机数。
Van der Corput 序列
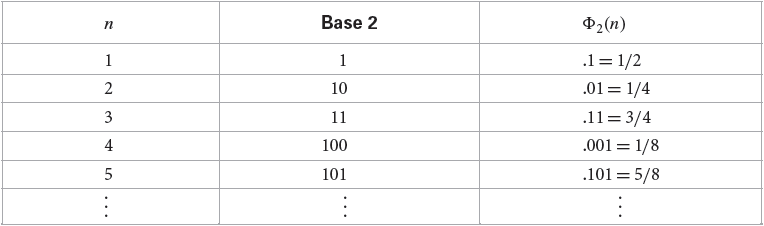
我们先给出 Van der Corput 序列的定义:给定一个正整数 $b$ 作为基,对于一个整数 $i$,其可表示为 $b$ 进制数 $i=\sum a_l(i) b^l$,则 Van der Corput 序列可以由正整数序列通过下列变换获得
即,Sobol 序列的每一维都是以 2 为基的,带不同生成矩阵的类似 Van der Corput 序列。它也具有均匀分布性质,且是对于每一维的 2 的幂次等分区域都会恰好有一个样本点。为了得到分布良好的数列,且避免类似 Halton 序列前几个点出现的线性相关性,生成矩阵需要精心设计,可以在相关资料中获取设计好的生成矩阵。
很快啊,啪一下就生成了:伪随机数生成器
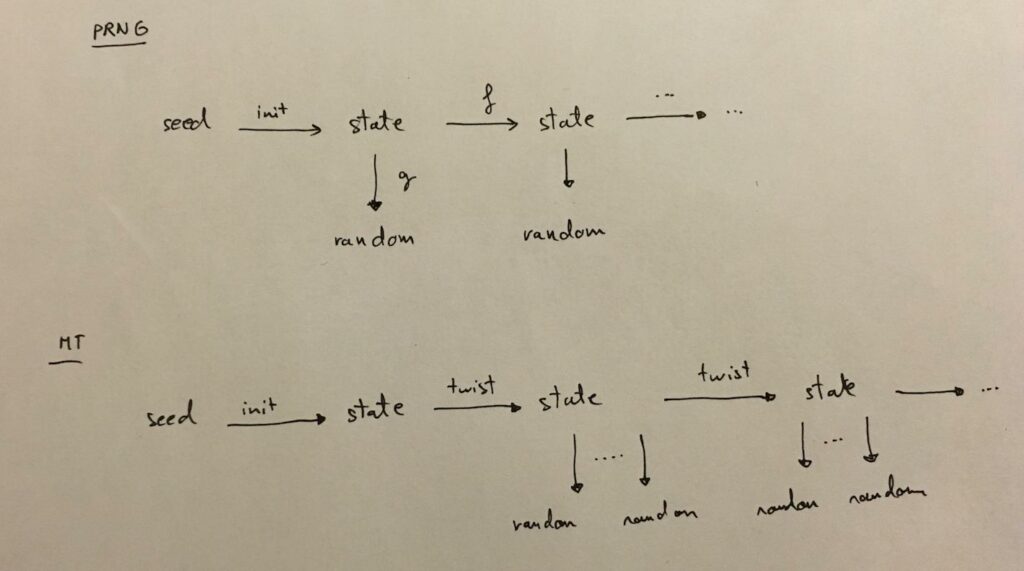
真随机数的获得需要采集物理现象,准随机数的获得可能需要大量运算,生成这些随机数的成本都较高。为了适应需要快速获得随机数的场景,我们可以降低对随机数性质的要求,则伪随机数生成器(Pseudo Random Number Generator,PRNG)就被提了出来。它用于生成近似具有随机数分布的特性,但可能可以通过分析预测的伪随机数,出于性能考量,其算法具有快速计算的特征。[9]
#include <stdint.h>
struct xorshift32_state {
uint32_t a;
};
/* The state word must be initialized to non-zero */
uint32_t xorshift32(struct xorshift32_state *state)
{
/* Algorithm "xor" from p. 4 of Marsaglia, "Xorshift RNGs" */
uint32_t x = state->a;
x ^= x << 13;
x ^= x >> 17;
x ^= x << 5;
return state->a = x;
}
本文的灵感来源为 NVIDIA Developer 上的一篇文章《Efficient Random Number Generation and Application Using CUDA》(参考资料 [18]),该文章启发我学习与研究各种随机数生成算法及其特征,以及文章本身提到的 GPU 上的随机数生成与随机数在图形学中的应用。
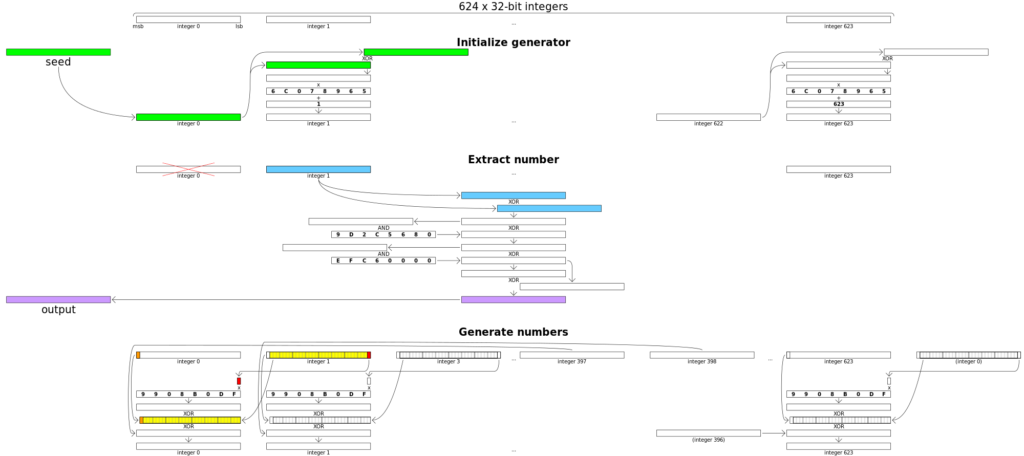
[14] Visualisation of generation of pseudo-random 32-bit integers using a Mersenne Twister. The ‘Extract number’ section shows an example where integer 0 has already been output and the index is at integer 1. ‘Generate numbers’ is run when all integers have been output. https://commons.wikimedia.org/wiki/File:Mersenne_Twister_visualisation.svg




{kind=link}
{kind=link}