Roll - 专为您的手机设计的一次性相机
The disposable camera for your phone (www.producthunt.com)
In this part of the Cache Lab, the mission is simple yet devious: optimize matrix transposition for three specific sizes: 32x32, 64x64, and 61x67. Our primary enemy? Cache misses.
A standard transposition swaps rows and columns directly:
1 | void trans(int M, int N, int A[N][M], int B[M][N]) |
While correct, this approach is a cache-miss nightmare because it ignores how data is actually stored in memory.
To optimize effectively, we first have to understand our hardware constraints. The lab specifies a directly mapped cache with the following parameters:
| Parameter | Value |
|---|---|
| Sets (S) | 32 |
| Block Size (B) | 32 bytes |
| Associativity (E) | 1 (Direct-mapped) |
| Integer Size | 4 bytes |
| Capacity per line | 8 integers |
We will use Matrix Tiling and Loop Unrolling to optimize the codes.
In this case, a row of the matrix needs 32/8 = 4 sets of cache to store. And cache conflicts occur every 32/4 = 8 rows. This makes 8x8 tiling the sweet spot.
By processing the matrix in blocks, we ensure that once a line of A is loaded, we use all 8 integers before it gets evicted. We also use loop unrolling with 8 local variables to minimize the overhead of accessing B.
1 | int i,j,k; |
Since 61 and 67 are not powers of two, the conflict misses don’t occur in a regular pattern like they do in the square matrices. This “irregularity” is actually a blessing. We can get away with simple tiling. A 16x16 block size typically yields enough performance to pass the miss-count threshold.
1 | int BLOCK_SIZE = 16; |
This is the hardest part. In a 64x64 matrix, a row needs 8 sets, but conflict misses occur every rows. If we use 8x8 tiling, the bottom half of the block will evict the top half.
We can try a 4x4 matrix tiling first.
1 | int BLOCK_SIZE = 4; |
But this isn’t enough to pass the miss-count threshold.
We try a 8x8 matrix tiling. We solve this by partitioning the block into four sub-blocks and using the upper-right corner of B as a “buffer” to store data temporarily.
Here are the steps:
1 | int i, j, k; |
Note: The key trick here is traversing B by columns where possible (so B stays right in the cache) and utilizing local registers (temporary variables) to bridge the gap between conflicting cache lines.
Optimizing matrix transposition is less about the math and more about mechanical sympathy—understanding the underlying hardware to write code that plays nice with the CPU’s cache.
The jump from the naive version to these optimized versions isn’t just a marginal gain; it’s often a 10x reduction in cache misses. It serves as a stark reminder that in systems programming, how you access your data is just as important as the algorithm itself.
For the CSAPP Cache Lab, the students are asked to write a small C program (200~300 lines) that simulates a cache memory.
The full code is here on GitHub.
A cache can be described with the following four parameters:
When the CPU wants to access a 64-bit address, the cache doesn’t look at the whole number at once. It slices the address into three distinct fields:
| Field | Purpose |
|---|---|
| Tag | Used to uniquely identify the memory block within a specific set. t = m - b - s |
| Set Index | Determines which set the address maps to. |
| Block Offset | Identifies the specific byte within the cache line. |
When our simulator receives an address (e.g., from an L or S operation in the trace file), it follows these steps:
cache structure.valid == true AND the tag matches the address tag.valid == false), fill it with the new tag and set valid = true.For this Lab Project, we will write a cache simulator that takes a valgrind memory trace as an input.
The input looks like:
1 | I 0400d7d4,8 |
Each line denotes one or two memory accesses. The format of each line is
1 | [space]operation address,size |
The operation field denotes the type of memory access:
Mind you: There is never a space before each “I”. There is always a space before each “M”, “L”, and “S”.
The address field specifies a 64-bit hexadecimal memory address. The size field specifies the number of bytes accessed by the operation.
Our program should take the following command line arguments:
Usage: ./csim-ref [-hv] -s <s> -E <E> -b <b> -t <tracefile>
-h: Optional help flag that prints usage info-v: Optional verbose flag that displays trace info-s <s>: Number of set index bits (S = 2s is the number of sets)-E <E>: Associativity (number of lines per set)-b <b>: Number of block bits (B = 2b is the block size)-t <tracefile>: Name of the valgrind trace to replayFor this lab, we ignore all Is (the instruction cache accesses).
We assume that memory accesses are aligned properly, such that a single memory access never crosses block boundaries.
We basically start from scratch, given an almost blank csim.c file to fill in. The file comes with only a main function and no header files.
1 | // Data Model |
First, we add the int argc, char** argv parameters to the main function. argc stands for argument count, while argv stands for argument values.
We use getopt to parse arguments.
1 | void handleArgs(int argc, char** argv){ |
getopt comes in unistd.h, but the compiler option is set to -std=c99, which hides all POSIX extensions. GNU systems provide a standalone <getopt.h> header. So we include getopt.h instead.
1 | opt = getopt(argc, argv, "hvs:E:b:t:") |
h and v: These are boolean flags.s:, E:, b:, and t:: These are required arguments. The colon tells getopt that these flags must be followed by a value (e.g., -s 4).After parsing the arguments, we set the initial value of our Cache Data Model.
1 | sets = 1LL << set_bit; |
1 | // Cache Line Structure |
Caution: malloc has to be initialized. Or the data might contain garbage values.
So we use calloc. The calloc (stands for contiguous allocation) function is similar to malloc but it initializes the allocated memory to zero.
And don’t forget to free the allocated memory!
1 | void freeCache() { |
1 | // Handle trace file |
Caution:
fscanf does not skip spaces before %c, so we add a space before %c in the format string.!feof(traceFile) does not work correctly here.It only returns true after a read operation has already attempted to go past the end of the file and failed. Using it as a loop condition (e.g., while (!feof(p))) causes an “off-by-one” error, where the loop executes one extra time with garbage data from the last successful read.1 | // Parse Line Structure |
We use bit masks to parse the addresses.
1 | void loadData(long long address, int size) { |
The code simulates the process of loading cache.
We first check if the data already exists in the cache.
If it doesn’t exist, we have to scan for blank lines to load the data.
If blank lines don’t exist, we need to evict a line using the LRU strategy. We replace the victim line with the new line.
1 | void storeData(long long address, int size) { |
For this simulator, storing data and modifying data are basically the same thing as loading data.
We are asked to output the answer using the printSummary function.
1 | // Print Summary |
And Voila!
1 | Your simulator Reference simulator |
In this project, we moved from the theory of hierarchy to the practical reality of memory management. By building this simulator, we reinforced several core concepts of computer systems.
With our simulator passing all the trace tests, we’ve effectively mirrored how a CPU “thinks” about memory. The next step is applying these insights to optimize actual code, ensuring our algorithms play nicely with the hardware we’ve just simulated.
做完了 CSAPP Bomb Lab,寫一篇解析。
運行一個二進制文件 bomb,它包括六個"階段(phase)“,每個階段要求學生通過 stdin 輸入一個特定的字串。如果輸入了預期的字串,那麼該階段被"拆除”,進入下一個階段,直到所有炸彈被成功"拆除"。否則,炸彈就會"爆炸",列印出"BOOM!!!"
這個系統是在 x86_64 Linux 上運行的,而筆者的環境是 ARM 架構的 macOS (Apple Silicon)。
弄了半天 docker,虛擬化一個 x86_64 Ubuntu 出來,結果裡面的 gdb 不能用,不想折騰。
發現 educoder 上面有環境,可以直接用,而且免費,於是就在 educoder 上面完成了本實驗。
地址:https://www.educoder.net/paths/6g398fky
本實驗要求掌握 gdb 的一些指令。
| 指令 | 縮寫 | 描述 |
|---|---|---|
gdb executable | - | 啟動 GDB 並載入可執行文件。 |
run [args] | r | 開始運行程序。如果有命令行參數,跟在後面(如 r input.txt)。 |
quit | q | 退出 GDB。 |
start | - | 運行程序並在 main 函數的第一行自動暫停(省去手動打斷點的麻煩)。 |
set args ... | - | 設置運行時的參數(在 r 之前使用)。 |
| 指令 | 縮寫 | 描述 | 範例 |
|---|---|---|---|
break <loc> | b | 設置斷點。支持函數名、行號、檔案名:行號。 | b mainb 15b file.c:20 |
info breakpoints | i b | 查看當前所有斷點及其編號 (Num)。 | - |
delete <Num> | d | 刪除指定編號的斷點。不加編號則刪除所有。 | d 1 |
disable/enable <Num> | - | 暫時禁用或啟用某個斷點(保留配置但不生效)。 | disable 2 |
break ... if <cond> | - | 條件斷點:僅當條件為真時才暫停(非常有用)。 | b 10 if i==5 |
| 指令 | 縮寫 | 描述 | 區別點 |
|---|---|---|---|
next | n | 單步跳過。執行下一行程式碼。 | 如果遇到函數調用,不進入函數內部,直接執行完該函數。 |
step | s | 單步進入。執行下一行程式碼。 | 如果遇到函數調用,進入函數內部逐行除錯。 |
continue | c | 繼續運行,直到遇到下一個斷點或程序結束。 | - |
finish | - | 執行直到當前函數返回。 | 當你不小心 s 進了一個不想看的庫函數時,用這個跳出來。 |
until <line> | u | 運行直到指定行號。 | 常用於快速跳出循環。 |
| 指令 | 縮寫 | 描述 |
|---|---|---|
print <var> | p | 列印變數的值。支持表達式(如 p index + 1)。 |
display <var> | - | 持續顯示。每次程序暫停時,自動列印該變數的值(適合跟蹤循環中的變數)。 |
info locals | - | 列印當前棧幀中所有局部變數的值。 |
whatis <var> | - | 查看變數的數據類型。 |
ptype <struct> | - | 查看結構體或類的具體定義(成員列表)。 |
x /nfu <addr> | x | 查看記憶體。n是數量,f是格式(x=hex, d=dec, s=str),u是單位(b=byte, w=word)。例如: x/10xw &array (以16進制顯示數組前10個word)。 |
| 指令 | 縮寫 | 描述 |
|---|---|---|
backtrace | bt | 查看調用棧。顯示程序崩潰時的函數調用路徑(從 main 到當前函數)。 |
frame <Num> | f | 切換到指定的堆棧幀(配合 bt 看到的編號)。切換後可以用 p 查看該層函數的局部變數。 |
list | l | 顯示當前行附近的原始碼。 |
layout src:螢幕分為兩半,上面顯示原始碼和當前執行行,下面是命令窗口。(強烈推薦)layout asm:顯示匯編代碼。layout split:同時顯示原始碼和匯編。我們可以使用 objdump 直接進行反匯編,查看匯編原始碼。
1 | objdump -d bomb > bomb.asm |
我們可以觀察到,幾個 phase 其實是幾個函數,phase_x()。
在終端輸入:
1 | strings bomb |
這會把 bomb 文件裡所有連續的可列印字元(ASCII)都列印出來。
我們先看看 phase_1 長什麼樣子,disas phase_1
1 | Dump of assembler code for function phase_1: |
sub $0x8,%rsp 是設置棧幀,在這裡不用管。
mov $0x402400,%esi 和 callq 0x401338 <strings_not_equal> 似乎進行了字串的 strcmp。
接下來 je 0x400ef7 <phase_1+23> 就很明顯了,如果相等跳出炸彈。
設置斷點,b phase_1
之後運行程序,r,隨便輸入一些內容,就可以觸發斷點
以字串形式查看 0x402400 所指向的記憶體:x/s 0x402400
1 | 0x402400: "Border relations with Canada have never been better." |
我們找到了答案。
還是先反匯編:
1 | Dump of assembler code for function phase_2: |
0x0000000000400f05 <+9>: callq 0x40145c <read_six_numbers> 這裡看到 read_six_numbers
我們可以反匯編 read_six_numbers
1 | Dump of assembler code for function read_six_numbers: |
看到有一行 callq 0x400bf0 <__isoc99_sscanf@plt>,調用了 sscanf
我們看一眼 $0x4025c3,x/s 0x4025c3,得到 %d %d %d %d %d %d,確實是讀了六個數字。
函數調用時,參數多於六個,就會丟到棧裡面去。我們看到:
1 | 0x0000000000401460 <+4>: mov %rsi,%rdx |
參數順序:rdi, rsi, rdx, rcx, r8, r9,超過了六個參數。rsp 為棧頂指針,多於六個的參數存在棧上。
於是讀取的六個數字依次存為:rsi, rsi+4, rsi+8, rsi+12, rsi+16 (0x10 = 16), rsi+20 (0x14 = 20)
再回到 phase_2
1 | 0x0000000000400f02 <+6>: mov %rsp,%rsi |
棧頂指針作為參數傳入了 read_six_numbers,因此,這六個數字應該是在 phase_2 對應棧幀的棧上
1 | 0x0000000000400f0a <+14>: cmpl $0x1,(%rsp) |
這裡判斷棧頂元素是否是 1,也就是說第一個元素是否是 1
之後跳轉到了 0x400f30
1 | 0x0000000000400f17 <+27>: mov -0x4(%rbx),%eax |
這裡很顯然是一個循環,依次讀取六個數位(每次移動四個位元組,正好是 int 的長度)
1 | 0x0000000000400f1a <+30>: add %eax,%eax |
這六個數字,後一個是前一個的兩倍。
於是我們可以得到答案:1 2 4 8 16 32
我們也可以把代碼翻譯成 C 語言:
1 | for (int i = 1; i < 6; i++) { |
反匯編:
1 | Dump of assembler code for function phase_3: |
看著有點複雜,觀察到 sscanf
看一眼 0x4025cf,x/s 0x4025cf,得到 %d %d,看起來是輸入了兩個整數
1 | 0x0000000000400f47 <+4>: lea 0xc(%rsp),%rcx |
這兩個整數依次存為 rsp+8, rsp+c
1 | 0x0000000000400f6a <+39>: cmpl $0x7,0x8(%rsp) |
這裡判斷了第一個數,如果這個數大於 7,就會引爆
1 | 0x0000000000400f71 <+46>: mov 0x8(%rsp),%eax |
我們把第一個整數存入 eax,這裡很明顯是一個 switch 的跳轉表:0x402470 + 8*rax
eax 和 rax 實際上是同一個東西,前者是這個暫存器的前 32 位,後者是這個暫存器的完整 64 位,這是歷史遺留產物,實際上,還有 ax, ah, al,為了向後相容而保留。
我們來讀取 10 個,x/10x 0x402470,得到:
1 | 0x402470: 0x00400f7c 0x00000000 0x00400fb9 0x00000000 |
這是 switch 語句的跳轉表,與匯編代碼中對應。
我們隨便選一個就能得到正確答案,如,0 對應 0x00400f7c
1 | 0x0000000000400f7c <+57>: mov $0xcf,%eax |
第二個數和 eax 比較,相等就拆除成功
我們得到第二個數 0xcf = 207
於是,答案是 0 207
實際上,答案並不唯一,觀察代碼可以知道,每一個 switch 分支中,都對應了一個第二個整數的正確答案。
反編譯:
1 | Dump of assembler code for function phase_4: |
我們還是看到 sscanf
讀一下 0x4025cf,得到 %d %d,看起來又是讀兩個數字,分別存入 rdx, rcx
接著往下讀,jbe 0x40103a,要求 rdx <= 14
1 | 0x000000000040103a <+46>: mov $0xe,%edx |
明顯在傳參,調用了 func4
我們先不急著看 func4,接著往下讀
1 | 0x000000000040104d <+65>: test %eax,%eax |
回顧一下暫存器知識,eax 在這裡是函數的返回值,這裡要求返回值等於 0
1 | 0x0000000000401051 <+69>: cmpl $0x0,0xc(%rsp) |
這裡要求讀取到的第二個數是 0,算是得到了半個答案
接下來我們看 func4
1 | Dump of assembler code for function func4: |
這個代碼裡面包含遞迴,我們可以手動把這段代碼翻譯到 C 語言:
1 | // edx = 14, esi = 0, edi = a |
這是二分尋找,我們很容易得到答案 a=7,於是返回 0
得到最終的答案 7 0
1 | 0x0000000000400fd2 <+4>: mov %edx,%eax |
這一段代碼就是在計算 mid,非常好理解,但是有個問題:shr $0x1f,%ecx 是在做什麼?
整數除法要求向零捨入。對於正數,向下捨入;對於負數,向上捨入。除以2的冪可以用右移操作替代。
但是,對於補碼右移,很可能出現捨入錯誤。
我們進行右移的時候,其實是捨去了最低位,是一種向下取整
當我們執行右移 x >> k 時:高位部分的權重全部除以了 ,變成了整數結果。低位部分(餘數)直接被丟棄了。
對於負數而言,這一操作進行了向下取整,但我們要求對負數進行向上取整。
因此,我們需要引入偏置。
於是 (x+(1<<k)-1)>>k 得到
也就是下面這兩行的含義
1 | 0x0000000000400fd8 <+10>: shr $0x1f,%ecx |
我們先disas看代碼
1 | Dump of assembler code for function phase_5: |
很快識別出來,這一段代碼中有兩個記憶體地址:0x4024b0 0x40245e
讀一下:
1 | 0x4024b0 <array.3449>: "maduiersnfotvbylSo you think you can stop the bomb with ctrl-c, do you?" |
第一個 array.3449 是一個字串,我們就記為 a[]
上面的代碼可以分個段
1 | 0x0000000000401062 <+0>: push %rbx |
這裡是前面初始化的部分,我們可以看到預留了棧空間,應該是讀取了一個字串,長度為 6,存在棧上。
1 | 0x00000000004010d2 <+112>: mov $0x0,%eax |
以上是一個 for 循環,循環 6 次,取 edx 的後四位,這是一個 0~15 的數,記為 i,於是把 a[i] 加入棧中對應位置
1 | 0x00000000004010ae <+76>: movb $0x0,0x16(%rsp) |
這裡有價值的片段只有
1 | 0x00000000004010ae <+76>: movb $0x0,0x16(%rsp) |
這是比較字串。
我們不難發現,這道題的邏輯是查表映射:程序會把輸入字元對 16 取模得到的數值作為索引,去尋找那個長字串(maduiers…)中的字元。 為了讓最終取出來的字元拼成 flyers,我們需要反向尋找 flyers 中每個字母在表中對應的下標位置,然後構造一個輸入字串,使其每一位的 ASCII 碼模 16 後正好等於這些下標。
這個過程可以總結為: Input Char -> ASCII Hex -> AND 0xF (取後4位) -> Table Index -> Lookup Table Char -> Target “flyers”
於是我們可以得到答案 ionefg 或者 IONEFG
其實還可以有一些其他答案,留給讀者去發現
先看代碼
1 | 0x00000000004010f4 <+0>: push %r14 |
分開來看:
1 | 0x00000000004010f4 <+0>: push %r14 |
這一段是設置棧幀
1 | 0x0000000000401106 <+18>: callq 0x40145c <read_six_numbers> |
這裡讀了 6 個數字,我們在 Phase 2 已經看到,這六個數字存在從 rsp 開始的一個數組中。
1 | 0x000000000040110b <+23>: mov %rsp,%r14 |
此處代碼構建了一個典型的嵌套循環結構:外層循環由 %r12d 計數,內層循環則由 %ebx 控制。
1 | 0x0000000000401117 <+35>: mov 0x0(%r13),%eax |
首先分析外層循環:它通過 %r13 指針遍歷輸入數組,首要任務是進行邊界檢查,確保讀取到的每一個數字都小於或等於 6。
再來看內層循環:
1 | 0x0000000000401132 <+62>: mov %r12d,%ebx |
這裡從當前外層數字開始,判斷數組之後的每一個數位(int 類型,4 位元組,故 (%rsp,%rax,4) 獲得當前數字),判斷這個數字是否和外層數字相同。
於是,我們發現,這一層循環判斷輸入的每個數字是否互不相同。
總結一下,這個嵌套循環檢查我們的輸入是否是六個互不相同的小於等於 6 的數字
1 | 0x0000000000401153 <+95>: lea 0x18(%rsp),%rsi |
這裡又有一個循環。前文已知,r14 就是 rsp,也就是棧指針。這裡遍歷每一個數 x,重新賦值,x = 7-x
1 | 0x000000000040116f <+123>: mov $0x0,%esi |
先讀取輸入的元素 x,如果小於等於 1,把 edx 賦值為 0x6032d0,然後把 x 放在一個臨時數組中,然後繼續到下一個元素,直到遍歷完整個數組 (0x18 = 24 = 4*6)
如果元素 x 大於 1,把 eax 賦值為 1,edx 賦值為 0x6032d0,之後執行 x-1 次 mov 0x8(%rdx),%rdx 操作
這裡疑似是鍊表,出現了記憶體地址 0x6032d0,我們來看看:
1 | (gdb) x/12xg 0x6032d0 |
這裡注意,在 64 位系統中,指針占用 8 位元組(即 64 位)。
顯然是鍊表,0x8(%rdx) 代表 next 指針
故上述操作得到一個數組,設輸入數組的第 i 個數為 x,數組中第 i 個數對應鍊表中第 x 個數的地址。
1 | 0x00000000004011ab <+183>: mov 0x20(%rsp),%rbx |
這裡是一些初始化。rsi 是邊界指針,標記循環的終止。0x20 到 0x50 正好 6*8=48
1 | 0x00000000004011ba <+198>: mov %rbx,%rcx |
這裡遍歷了我們剛才得到的鍊表地址數組。寫成 C 語言或許更好理解。
1 | Node *current = node_ptrs[0]; // %rbx, %rcx 初始化 |
這一個循環對於鍊表結構進行了修改。
1 | 0x00000000004011d2 <+222>: movq $0x0,0x8(%rdx) |
這句話則把最後一個節點的 next 賦值為 NULL,確保鍊表結構
接下來又有一個循環:
1 | 0x00000000004011da <+230>: mov $0x5,%ebp |
遍歷鍊表,確保鍊表倒序排列。
看到這裡,我們就可以得到答案了:
1 | (gdb) x/12xg 0x6032d0 |
找到鍊表值的倒序索引即可,注意值是 int 類型,只取後四位。於是可以得到 3 4 5 6 1 2
但我們還要注意,輸入進行過 7-x 操作(見上文),所以我們調整答案 4 3 2 1 6 5
最後一個 Phase 有點複雜,巧妙融合了嵌套循環校驗、數組映射變換以及鍊表重組等多種技術。
1 | /* Hmm... Six phases must be more secure than one phase! */ |
bomb 代碼中,每一個 phase 後都運行 phase_defused。我們來看看:
1 | Dump of assembler code for function phase_defused: |
1 | 0x00000000004015d8 <+20>: cmpl $0x6,0x202181(%rip) # 0x603760 <num_input_strings> |
這裡要求六關全部通過之後才能進入 secret_phase
我們可以設置條件斷點:b phase_defused if num_input_strings == 6
注意到:
1 | 0x0000000000401630 <+108>: callq 0x401242 <secret_phase> |
這裡有非常多的記憶體地址,其中:
1 | (gdb) x/s 0x402619 |
判斷 Phase 4 輸入之後是否有一個字串 DrEvil,如果有,進入隱藏關!
再來看看隱藏關的代碼:
1 | Dump of assembler code for function secret_phase: |
看到 strtol,知道這裡讀入了一個整數
1 | 0x000000000040125a <+24>: mov %rax,%rbx |
要求讀取的整數小於等於 1001。注意 jbe 是無符號數的跳轉檢查,所以這裡其實也隱性限制了下限。所以嚴格的輸入限制是 [1, 1001] 之間的整數。
1 | 0x000000000040126c <+42>: mov %ebx,%esi |
傳參,進入 fun7
1 | 0x0000000000401278 <+54>: cmp $0x2,%eax |
這裡要求 fun7 的返回值等於 2
接下來我們看看 fun7,手動分個段
1 | Dump of assembler code for function fun7: |
遍歷當前 rdi 之後的兩個指針,遞迴,有點像二叉樹。我們來看看初始參數:
1 | (gdb) x/60xg 0x6030f0 |
確實是一顆二叉樹!(這裡的 60 是我試出來的)
fun7 傳入的參數為 rdi 和 esi
1 | 0x0000000000401208 <+4>: test %rdi,%rdi |
如果遍歷到葉子結點,直接返回 0xffffffff。
1 | 0x000000000040120d <+9>: mov (%rdi),%edx |
查看當前節點的值,如果值大於 esi:
1 | 0x0000000000401213 <+15>: mov 0x8(%rdi),%rdi |
訪問左子節點,返回值乘以二
如果當前節點的值和 rsi 相等:
1 | 0x0000000000401220 <+28>: mov $0x0,%eax |
直接返回
否則,訪問右子節點:
1 | 0x0000000000401229 <+37>: mov 0x10(%rdi),%rdi |
返回值乘以二再加一
我們可以用 C 語言翻譯上述代碼:
1 | long fun7(struct Node *node, int target_val) { |
我們再來看看二叉樹的結構,根據:
1 | (gdb) x/60xg 0x6030f0 |
1 | graph TD |
要求最終輸出為 2,2 = 1*2
先向左,再向右,然後找到了答案。
於是,我們得到答案 22
於是,最終答案是:
1 | Border relations with Canada have never been better. |
最後讓 AI 生成一段小結
CSAPP Bomb Lab 是一個非常經典的實驗,它不僅是一次對匯編語言 (x86-64) 的深度練習,更是一場邏輯推理的解謎遊戲。
回顧整個拆彈過程,我們經歷了從簡單到複雜的演進:
在這個過程中,gdb 是最強大的武器。熟練掌握斷點設置、暫存器查看 (i r) 和記憶體檢查 (x/) 是通關的關鍵。同時,我們也深刻體會到了編譯器最佳化的“智慧”(如利用 lea 進行算術運算、利用無符號數比較合併上下界檢查)和 C 語言與機器碼之間的映射關係。
當看到終端最終列印出 “Congratulations! You’ve defused the bomb!” 時,所有的查表、計算和堆棧分析都是值得的。希望這篇解析能對你理解計算機底層系統有所幫助。 Happy Hacking!
前一段時間做完了 CSAPP 的第一個 Lab,寫一篇總結。(其實這篇文章拖了很久)
CS:APP Data Lab 旨在通過一系列位操作謎題,訓練對整數和浮點數底層表示(特別是補碼和 IEEE 754 標準)的理解。要求在嚴格限制的操作符和操作數數量下,實現特定的數學或邏輯功能。
| 函數名 (Name) | 描述 (Description) | 難度 (Rating) | 最大操作數 (Max ops) |
|---|---|---|---|
bitXor(x, y) | 只使用 & 和 ~ 實現 x ^ y (異或)。 | 1 | 14 |
tmin() | 返回最小的補碼整數 (Two’s complement integer)。 | 1 | 4 |
isTmax(x) | 僅當 x 是最大的補碼整數時返回 True。 | 1 | 10 |
allOddBits(x) | 僅當 x 的所有奇數位都為 1 時返回 True。 | 2 | 12 |
negate(x) | 返回 -x,不使用 - 運算符。 | 2 | 5 |
isAsciiDigit(x) | 如果 0x30 <= x <= 0x39 (即 ASCII 數字字元) 則返回 True。 | 3 | 15 |
conditional(x, y, z) | 等同於 x ? y : z (三元運算符)。 | 3 | 16 |
isLessOrEqual(x, y) | 如果 x <= y 返回 True,否則返回 False。 | 3 | 24 |
logicalNeg(x) | 計算 !x (邏輯非),不使用 ! 運算符。 | 4 | 12 |
howManyBits(x) | 用補碼表示 x 所需的最小位數。 | 4 | 90 |
floatScale2(uf) | 對於浮點參數 f,返回 2 * f 的位級等價表示。 | 4 | 30 |
floatFloat2Int(uf) | 對於浮點參數 f,返回 (int)f 的位級等價表示。 | 4 | 30 |
floatPower2(x) | 對於整數 x,返回 2.0^x 的位級等價表示。 | 4 | 30 |
該題要求僅使用 ~(取反) 和 &(與),實現 ^(異或)
1 | int bitXor(int x, int y) { |
使用 De Morgan 律,容易得到 ~(x&y) = (~x)|(~y),於是我們可以使用 ~ 和 & 實現 | 操作。
異或操作,可以表示為 x^y = (~x & y) | (x & ~y),結合 De Morgan 律,我們很容易得到最終的答案 x^y = ~((~(x&~y))&(~((~x)&y)))。
這道題很簡單,返回最小的補碼整數。回顧補碼的定義,最高位取負權,故令符號位為 1 即可。
1 | int tmin(void) { |
判斷 x 是否是最大的補碼。若是,返回 1;否則,返回 0。
1 | int isTmax(int x) { |
最大的補碼有一個性質,加一之後變成最小的補碼:0x7fffffff -> 0x80000000
而最大的補碼加上最小的補碼等於 0xffffffff 即 -1,取反之後為 0 (這裡推出 0 是為了得到返回值中的 0/1)
因此,我們可以通過 ~(x+x+1) 得到答案。
但是 -1+0 也等於 -1,即如果 x=0 時,~(x+x+1) 同樣等於 1,是一個 Corner Case。
因此,我們還需要對結果與 !!(x+1),才能得到最終的答案。(如果 x=-1,!!(x+1)=0;其餘情況均為 1)
於是我們得到最終的答案 !(~(x+x+1)) & (!!(x+1))
僅當 x 的所有奇數位都為 1 時返回 1
1 | int allOddBits(int x) { |
我們做一個奇數位掩碼即可 0xAA = 0b10101010,通過左移,可以得到 a + (a<<8) + (a<<16) + (a <<24) = 0xAAAAAAAA = b
於是 x&b 取出所有奇數位,但是我們需要得到 0/1 的答案
bm = ~b + 1,得到 -b(取反加一是補碼相反數),b+(-b) = 0,再取邏輯非,就可以得到答案
這道題要求不使用 - 運算符計算 -x
1 | int negate(int x) { |
非常簡單,根據補碼的定義得到。取反加一就是相反數。
如果 0x30 <= x <= 0x39 (即 ASCII 數字字元) 則返回 True。
我們在這道題中不能使用 <= 這類運算符,因此,我們想到,進行減法之後取符號位的操作。
1 | int isAsciiDigit(int x) { |
使用位運算實現三目運算符(x ? y : z)
1 | int conditional(int x, int y, int z) { |
我們可以使用邏輯掩碼
先使用 !(!x) 將 x 轉換成 0/1,記為 xb
~xb + 1,則有 0 -> 0;1 -> -1 = 0xffffffff(掩碼,取所有位)
因此,(M&y) | (~M&z) 就是最終的答案。
如果 x = 1,M = 0xffffffff,~M = 0,取 y;否則,取 z
1 | int isLessOrEqual(int x, int y) { |
簡單判斷符號位即可。但是實現的是 <=,對 > 取非即可
計算 !x (邏輯非),不使用 ! 運算符
1 | int logicalNeg(int x) { |
計算用補碼表示 x 所需的最小位數
1 | int howManyBits(int x) { |
這道題,先選取符號位,然後計算之後的最高位即可。
為了方便計算,我們把負數補碼表示為正數,這樣就只用計算最高位的 1 在哪裡就行了
((~fg) & x) | (fg & (~x)) 是一個條件取反操作,相當於 x = (x < 0) ? ~x : x
這裡提醒各位,此處補碼右移是算術右移,所以負數右移得到一個所有位都為 1 的數,也就是 -1。
接下來進行位的二份尋找:
這裡的邏輯是**“分治法”**。我們有 32 位要檢查,像二分尋找一樣:
檢查高 16 位:
x >> 16:如果不為 0,說明最高位的 1 在高 16 位中(即位 16-31)。!!(...):將結果轉化為 0 或 1。如果高 16 位有數,結果為 1,否則為 0。1<< 4:如果高 16 位有數,說明我們至少需要 16 位,即 1 << 4 = 16。h16:這就是我們找到的基數(0 或 16)。x >>= h16:關鍵點。如果我們確定高 16 位有數,我們將 x 右移 16 位,丟棄低 16 位,接下來的檢查只關注剛才的高 16 位。如果高 16 位全是 0,x 保持不變,我們繼續檢查原本的低 16 位。檢查高 8 位(在剩下的 16 位範圍內):
邏輯同上。如果剩下的這部分的高 8 位有數,則 h8 = 8,並將 x 右移 8 位。
h4:檢查剩下的 4 位中的高 2 位… (這裡代碼邏輯是一致的,檢查高4位)。h2:檢查剩下的 4 位。h1:檢查剩下的 2 位。h0 = x:檢查最後剩下的 1 位。最後,我們計算 h16+…+h0 的總和即可。這裡要注意,補碼有一個符號位,所以結果還要再 +1。
得到答案:h0 + h1 + h2 + h4 + h8 + h16 + 1
對於浮點參數 f,返回 2 * f 的位級等價表示
我們先來回顧一下浮點數的位級表示,即 IEEE 754,這裡以 float 為例
浮點數位中有三段:
1 | int sign = (uf >> 31) & 0x1; |
對於一個浮點數的解釋,有三種情況:
exp == 0exp != 0 且 exp != 255exp == 255 (全 1)frac == 0:Infinity (無窮大)frac != 0:NaN (Not a Number)接下來我們看這道題,這道題只需要注意分類討論就可以。
1 | unsigned floatScale2(unsigned uf) { |
對於整數 x,返回 2.0^x 的位級等價表示。對於這道題,計算出幾個臨界點即可。
1 | unsigned floatPower2(int x) { |
Data Lab 實驗使我深入理解整數(補碼)和浮點數(IEEE 754)在二進制層面的表示方法,透過使用一組極其受限的位運算符(如 ~, &, |, ^, +, <<, >>)來實現複雜的邏輯、算術、比較和類型轉換操作,從而真正掌握了位運算的技巧。
我的代碼存放在 aeilot/CSAPP-Labs。
掩碼 (Mask) 是一種位運算技巧,它使用一個特定的值(掩碼)與目標值進行 (與)、 (或)、 (異或) 運算,以精確地、批次地操作、提取或檢查目標值中的一個或多個位。
掩碼利用位運算的特性,透過設定掩碼中的特定位為 1 或 0,來控制目標值中對應位的行為。 具體來說,掩碼可以用來提取某些位的值,清除某些位的值,反轉某些位的值,或者設定某些位的值。
透過與運算()和一個掩碼,可以提取目標值中特定位置的位。例如,假設我們有一個 8 位的二進位制數 10101100,我們想提取其中的第 3 位(從右數起,0 開始計數)。我們可以使用掩碼 00000100:
1 | 10101100 (目標值) |
結果 00000100 表示第 3 位是 1。
這一技巧可以用來提取多位,比如想要提取某個數的低 4 位,可以使用掩碼 00001111。
透過與運算()和一個掩碼,可以清除目標值中特定位置的位。例如,假設我們有一個 8 位的二進位制數 10101100,我們想清除其中的第 3 位。我們可以使用掩碼 11111011:
1 | 10101100 (目標值) |
結果 10101000 表示第 3 位被清除為 0。
清除就是不提取某些位 lol
透過異或運算()和一個掩碼,可以反轉目標值中特定位置的位。例如,假設我們有一個 8 位的二進位制數 10101100,我們想反轉其中的第 3 位。我們可以使用掩碼 00000100:
1 | 10101100 (目標值) |
結果 10101000 表示第 3 位被反轉。
透過或運算()和一個掩碼,可以設定目標值中特定位置的位。例如,假設我們有一個 8 位的二進位制數 10101000,我們想設定其中的第 3 位為 1。我們可以使用掩碼 00000100:
1 | 10101000 (目標值) |
結果 10101100 表示第 3 位被設定為 1。
構造合適的掩碼是使用技巧的關鍵。
在 CSAPP Data Lab 中,我們有一道題目要求用位運算實現三目運算子 x ? y : z。我們可以使用條件掩碼來實現這一點。
1 | int conditional(int x, int y, int z) { |
這段程式碼的邏輯是:
mask = !!x,如果 x 非零,mask 為 1,否則為 0。mask = ~mask + 1,將 mask 轉換為全 1 (0xFFFFFFFF) 或全 0 (0x0)。(y & mask) | (z & ~mask),如果 x 非零,結果為 y,否則為 z。掩碼是一種強大的位運算技巧,可以用來精確地操作和檢查資料中的特定位。
透過合理構造掩碼,我們可以高效地實現各種位操作,如提取、清除、反轉和設定位。在實際程式設計中,掌握掩碼的使用能夠幫助我們編寫出更高效、更簡潔的程式碼。
在做 CSAPP Data Lab 的時候,關於整數溢位,遇到一些問題。
1 | /* |
題目要求,僅僅使用運算子 ! ~ & ^ | + 來判斷一個數是否是最大的二的補碼(int 範圍內),即 0x7fffffff。如果是,輸出 1;否則,輸出 0。
由於我們不能使用移位操作(很多人會直接 1<<31 - 1),可以考慮整數溢位的特殊性質。
具體地,我們有 0x7fffffff + 1 = 0x80000000,符號改變。
而 0x80000000 + 0x80000000 = 0
我們可以得到 x = 0x7fffffff 滿足 x + 1 + x + 1 = 0
而對於其他數字,假設 y = x + k 其中 k 非零,則有 y + 1 + y + 1 = 2*k
此時,我們發現,對於 y=-1 也有 y + 1 + y + 1 = 0,需要排除掉
其他情況下,非零數轉換為 bool 型別自動變為 1
我們不難寫出以下程式碼:
1 | int isTmax(int x) { |
這段程式碼在我本地(macOS,Apple clang version 17.0.0 (clang-1700.3.19.1), Target: arm64-apple-darwin25.0.0) 上執行,使用命令 clang main.c 是沒有任何問題的。
但是,檢查到 CSAPP 提供的 Makefile,有
1 | # |
注意到,編譯器使用了 -O flag,即 O1 最佳化。
此時執行這段程式碼,對於 0x7fffffff 輸出 0,懷疑可能是編譯器最佳化時,假設未定義行為(整數溢位)不會發生,將 !p2 最佳化。p1 + p1 的形式過於簡單。
未定義行為(UB),根據 cppreference 的定義:
1 | undefined behavior - There are no restrictions on the behavior of the program. |
有符號整數溢位是一種常見的未定義行為。
Because correct C++ programs are free of undefined behavior, compilers may produce unexpected results when a program that actually has UB is compiled with optimization enabled.
也就是說,編譯器最佳化會對未定義行為產生意料之外的結果
cppreference 給出了一個整數溢位的例子:
1 | int foo(int x) |
編譯之後卻變成了
1 | foo(int): |
意思是,不管怎麼樣都輸出 1
我們透過 gcc -S 輸出編譯後的彙編程式碼
1 | _Z6isTmaxi: |
我們看到,編譯器直接把這個函式返回值改成了 0,不管輸入什麼,與我們的錯誤原因推斷是相同的。
我們可以嘗試構造一個更復雜的、不易被簡單規則匹配的表示式,躲過 O1 級別的最佳化。
核心思路不變,仍然是利用 Tmax + 1 = Tmin 這個特性。我們來觀察一下 Tmax 和 Tmin 在二進位制下的關係:
Tmax = 0x7fffffff = 0111...1111Tmin = 0x80000000 = 1000...0000一個非常有趣的性質是 Tmax + Tmin = -1 (0xffffffff)。
1 | 0111 1111 ... 1111 (Tmax) |
基於這個觀察,我們可以設計一個新的檢查方案:如果一個數 x 是 Tmax,那麼 x + (x+1) 的結果就應該是 -1。取反後 ~(-1) 則為 0。
我們可以寫出如下的修改版程式碼:
1 | int isTmax(int x) { |
這段程式碼的邏輯是:
map = x + 1。對於 x = Tmax,這裡同樣會發生有符號溢位,map 變為 Tmin。這依然是未定義行為(UB)。res = ~(map + x)。如果 x 是 Tmax,這一步就是 ~(Tmin + Tmax),結果為 ~(-1),即 0。return !res & (!!map)。!res 為 !0,即 1。!!map 部分和之前的版本一樣,是為了排除 x = -1 的情況(此時 map 為 0, !!map 為 0,最終返回 0)。這段程式碼在 -O 最佳化下可能會得到正確的結果。
我們必須清醒地認識到,新版本的程式碼本質上沒有解決未定義行為的問題,它只是“僥倖”地繞過了當前編譯器版本的特定最佳化策略。
p1 + p1 ((x+1)+(x+1)) 是一個非常簡單直白的模式,最佳化器很容易建立一個“如果 p1 非零,則 p1+p1 結果也非零”的最佳化規則。而 ~((x+1)+x) 混合了加法和位運算,模式更復雜,可能沒有觸發編譯器中已有的、基於UB的最佳化捷徑。所以,這個修改版只是一個更具迷惑性的“偽裝”。它在特定環境下能工作,但其行為是不被C語言標準所保證的,在不同的編譯器或未來的GCC版本下,它隨時可能失效。
透過 isTmax 這個小小的函式,我們可以一窺C語言中未定義行為的危險性以及現代編譯器最佳化的強大。作為開發者,我們應該得到以下啟示:
-Wall -Wextra) 並將警告視為錯誤 (-Werror),這能幫你發現許多潛在問題。-fsanitize=undefined,它就能在程式執行時精確地捕獲有符號整數溢位等UB,是除錯這類問題的神器。對於CSAPP Data Lab這道題來說,它的目的正是為了讓我們在“規則的鐐銬”下舞蹈,從而深刻理解整數表示、運算和編譯器行為。而我們在實際工程中,最安全、最清晰的寫法永遠是第一選擇。

Sora2 关闭,到底谁输了、谁赢了,很多人其实理解得并不深刻,而且大部分人都理解反了。
Sora2 宣布关闭,应该是 2026 年 3 月 24 日的事情。OpenAI 直接发了一条 X,我不知道是不是还发了其他公告,但我在 X 上看到了:我们要跟 Sora2 App 说再见了。
很多人就说,完蛋了,最早由 Sora 开始的 AI 视频生成赛道,现在别人都追上了,结果 OpenAI 自己玩飞了。到底是怎么回事,今天详细解说一下。大多数人的认知,我要告诉大家,全错。

第一个认知是:OpenAI 在收缩战线,准备冲刺 IPO 了,OpenAI 宣布失败了,以后不玩视频了。这个理解是错的。
第二个认知是:OpenAI 顶不住好莱坞的压力,必须要关闭 Sora 了。这也是很多人的解读,但这正好反了,待会再讲为什么。
第三个认知是:迪士尼亏了,200 个授权白给了,这么多有价值的 IP 直接授权出去,最后没养活 Sora。这个也不能这么简单理解。
还有一个说法是:OpenAI 亏了,迪士尼的 10 亿美金投资泡汤了。这个也没有这么简单。咱们一项一项拆解。

首先要讲,为什么要关闭。OpenAI 为什么要做这件事?第一个要注意的是,它关闭的是 Sora2 的 App,就是这个应用关了。Sora 相关的模型、API 调用都还在服务,至少目前还在。以后是不是继续做下去,还要拭目以待。
关闭 Sora2 App,并不等于 OpenAI 退出了视频生成模型的战斗,只是换了一种打法而已。
Sora2 App 上面给普通用户大量免费额度,大家可以在 Sora2 App 上看到别人的视频,说我也生成一个吧。这个非常非常耗钱。而且还有聪明的中国小伙伴研究出了薅羊毛的方法。

怎么薅羊毛呢?Sora2 除了有 App 之外,还有美国的网站。你必须把自己的 IP 地址设到美国,才可以用它的网站。通过前端注入的方法,也就是通过机器人模仿浏览器点击的过程,自动去生成视频,就可以薅它羊毛了。你可以把整个过程做成自动化。
很多国内看到的 AI 小漫剧,实际上都是拿这玩意做的。那 OpenAI 就亏死了,花了好多好多的钱,最后用户也没留下来。
OpenAI 当时做 Sora2 App 的目的,并不是说我的视频模型有多强。他们的目的是想做一个新的 TikTok。做 TikTok 的意义在哪?就是要让用户留下来互动,这才是做 TikTok 的意义,而不是说我的模型有多强就完了。
结果一帮中国聪明的小伙伴拿它的模型直接薅羊毛,做出视频以后发到 TikTok 上去了,给 TikTok 带来新的活跃和沉淀。那 OpenAI 不是亏死了吗?烧了很多算力和 token,最后没有给自己留下东西,反而给别人添砖加瓦了,所以必须把它关掉。
这一次关闭,并不是说版权或者 AI 视频生成这块出了问题。这一次的关闭,其实是 AI 视频社交媒体的尝试失败。大家一定要注意,不是视频模型失败,而是 AI 视频社交媒体的失败。
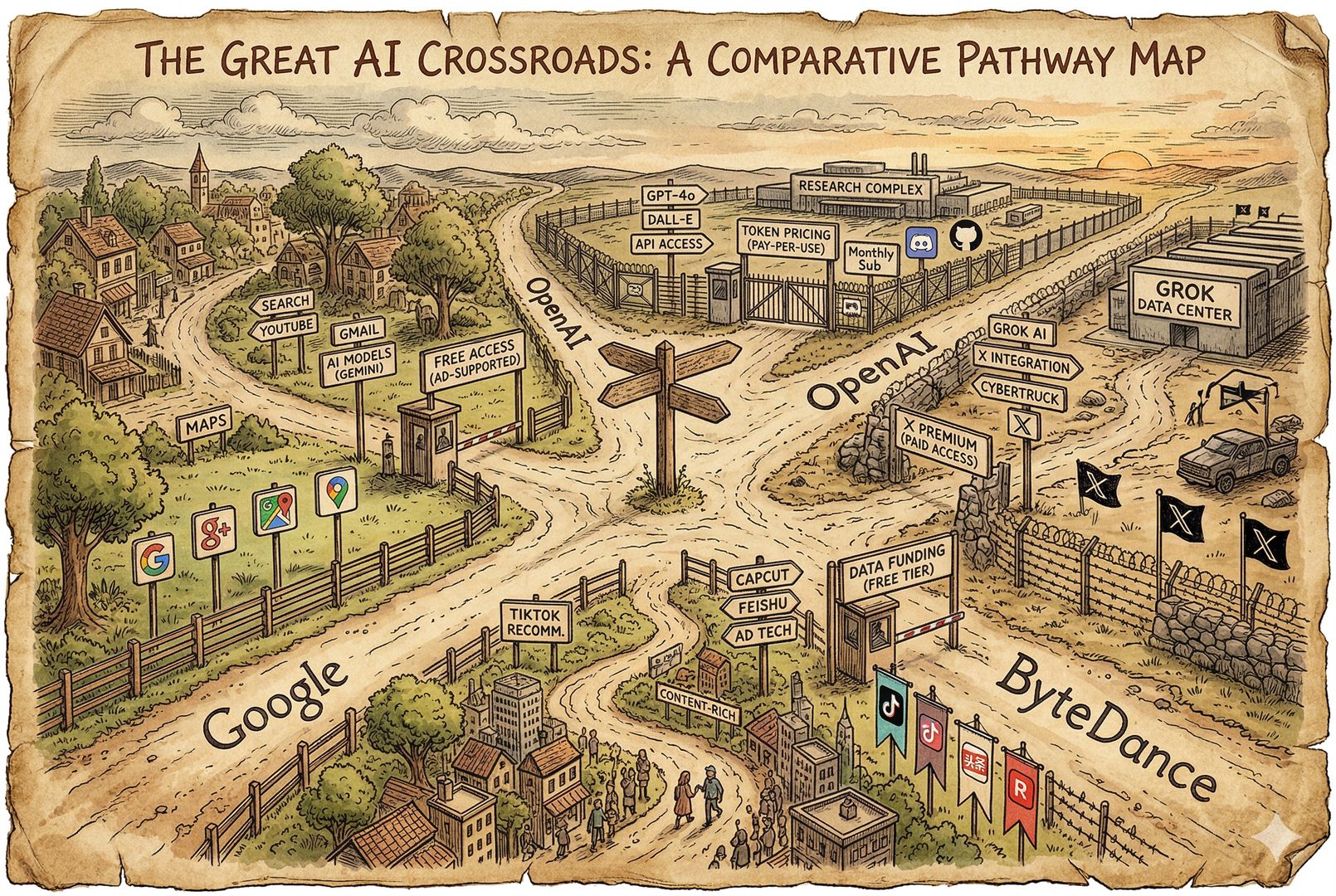
现在有四家 AI 视频生成公司在这个赛道里,实际上都有尝试。它们的结果是什么样的呢?
第一个是最保守的,谷歌最保守。它做的是 Veo 3.1,除了 API 按秒计费之外,基本上啥都没干。它并没有给你免费额度,也没惦记让你去形成新的用户关注、形成新的用户互动。
YouTube 后台确实添加了相关功能的预告,但是具体怎么用,我现在也没看到。Gemini Pro 用户每天大概可以做两条还是三条,这个基本上都被我浪费了。每天两三条,处理起来实在太麻烦了。这就是谷歌,啥都没干。
第二个就是 OpenAI,它属于激进派。一边是 Sora API 按秒收费,大概一秒钟是十几二十美分的样子;另外一边,就是给了用户巨大的免费额度。你用它的 Sora App,或者用美国 IP 登录它的 Sora 网站,都可以免费生成视频。
免费生成视频以后,一定会面临巨大的成本压力和版权合规压力,但是它没有获得持续的用户互动和用户沉淀。虽然 Sora2 出来以后,一下就登到了美国苹果排行榜的第一名,几周时间弄到了一大堆用户,但这个没用。你要让这些人留下来继续玩下去,才有意义。
当时 Sora2 出来的时候,我们其实录过视频,当时就预言过这件事情:模型做得还是可以的,但是你要想做出 App 来,让大家像玩 TikTok 那样玩下去,那还要日久见人心。结果现在它就失败了。OpenAI 自己没得到好处,还被人薅了羊毛,所以必须关闭。

第三家叫闷声赢家,就是 xAI。它的 Grok Image 这个模型也是可以生成视频的。它在绘图和做视频上其实不算最强,但是限制最少。我不管你什么有 IP 没 IP,或者穿得多穿得少,你们只管做就完了。
它也没有让大家免费生成,都是通过 API 按秒计费,大概一秒钟可能比 OpenAI 还稍微贵一点,具体其实不重要。
为什么说它闷声发大财?就是你如果用 Grok Image 生成了视频以后,把它发到 X 平台上去,如果这个视频做得很好,就有机会获得埃隆·马斯克亲自点赞和转发。
其实在四家视频大模型里头,做得最好的就是 xAI,因为它完全没限制,或者限制已经非常非常少了。而且马斯克还给你点赞。钱赚着了,按每秒钟收费,社交互动和用户沉淀,X 平台也都接着了。当然,它的投入也很巨大。你说它投入什么?世界首富手动在那点赞转发,这个你不算成本吗?一个身价 8000 亿美金的世界首富给你点赞了,这多爽。
第四家就是字节跳动,Seedance 2.0。他们属于稍微有点尴尬。为什么呢?模型做得非常好,但是它也想走 OpenAI 这条路,想抄一把。现在就有点尴尬了。
一方面,它现在按秒付费的 API 压根就没开。你说我现在想到火山云上去用它的 API,用不了。现在只可以通过即梦的网站或者 App,以及火山平台在网页端使用一些模板去生成视频。你现在再想上传什么素材,这一块基本上没法整,需要巨长的等待时间。你现在想生成一个视频,那就等吧,基本上等一天。
而且合规规则极其模糊,这是我特别讨厌的地方。你上传了一堆素材,说给我生成吧,它说对不起,你那个违规了。你问它怎么违规、怎么改正,它不告诉你,就是说你违规了。后来我说那你把规则文件给我,我自己去改进,它说不行,我们没有规则文件,你就是违规了。
另一方面,它也想学 OpenAI。即梦 App 走的就是 Sora2 的路线,用户可以免费生成,不用花钱。你如果在手机上,不管是安卓还是 iPhone,下载一个即梦 App,就可以照着人家已经生成好的模板,把自己的人脸录进去,就可以去生成了。
即梦 App 的结果其实跟 Sora2 差不多,也没有获得预期的用户互动和用户沉淀。但有一点比较好,就是它没有被薅羊毛。为什么呢?因为即梦的网站不可以免费生成视频,只有即梦 App 才可以免费生成视频。而 App 这个东西是没法薅羊毛的,你一旦有网站了,就可以通过很简单的前端注入手段去薅羊毛。因为视频生成这个事本身成本实在太高了,字节还是比较了解中国用户的,所以他们压根就没有开网站端的免费生成额度。
但是字节虽然在即梦 App 上没有赚到想要的互动,它也没亏大钱。因为什么呢?它手里还有 TikTok 和抖音。你做完的这些视频,虽然没有在即梦 App 里互动起来,但是到了 TikTok 和抖音里边去互动起来了。所以虽然有点尴尬,但总的不亏。

所以,必须要有成熟的社交媒体平台,才可能让 AI 视频社交玩起来。想重新单做一个,肯定是不行。Sora2 就是惦记重新单做一个,即梦 App 也是惦记另起炉灶单做一个,都没戏。
只有像 X、抖音或者 TikTok 这样的平台,才有可能起步。其实谷歌也是有机会的,只是这位老大实在太稳重了,因为它手里还有 YouTube Shorts。
想要搞新 App、重新吸引用户的尝试,基本上都失败了。现在制作视频的成本实在太高,不管对于平台方还是用户方来说,制作成本都很高。所以你想靠新的应用去吸引用户,太难了,用户太少。
最后,用户做出了视频以后,发现在 Sora2 这个 App 里没有人给我点赞,没有人跟我互动;在即梦这个 App 里做出来的,也没人给我点赞、没人跟我互动。那我只能把视频下载下来,到 X、到抖音这些平台重新再发一次,才发现有人点赞、有人互动。
在这样的情况下,用户只能选择薅羊毛,生成的视频放到其他有人气的社交媒体平台上去发布。那么,被薅了羊毛、还没留住用户互动的 OpenAI,就只能选择止损了。
这就是 OpenAI 为什么在这时候把它关掉的核心原因:这条路走错了。不是视频生成走错了,而是形成独立的 AI 视频社交媒体这条路走错了。
有人说,Sora2 的关闭是不是跟版权合规诉讼有关系,别人都告它,它就只能关掉了?这个事要跟大家讲,正好理解反了。
为什么呢?版权诉讼跟 Sora 关闭肯定是有关系的,但这也就是一个成本。有人告我了,我慢慢拖几天,再去研究怎么处理这些内容就可以了。这个事本身是可以进行成本核算的。只要用户来了,我都愿意支付这个成本。这点成本,比它烧掉 token 的成本要少得多。就算所有告它的人我都认赔了,赔出去那点钱,都不够它烧 token 的。
迪士尼愿意去做授权,也是去尝试加入这个游戏的一个过程。没有版权 IP,你就没有互动,这个是必然的。你说我今天自己拍一个视频,怎么没有人点赞呢?原因很简单,因为市面上绝大部分都是陌生的普通人。
你们来看老范讲故事,有的可能看了好几年了,咱们不算陌生人了,但是我们看到大部分街上的人,实际上都是陌生人。而且普通人长得也没那么好看,那肯定没人互动。谁愿意为一个陌生普通人去点赞呢?
有了热门 IP,比如米老鼠、唐老鸭或者星球大战这些 IP,就可以极大提升互动,这没有任何问题。那 Sora2 拿到了迪士尼的授权,应该有互动啊,怎么还关了呢?
所以说,不是因为有人诉讼 OpenAI,导致它关闭 Sora2,而是因为迪士尼诉讼得不够狠,所以它要关闭 Sora2。

这话怎么讲?大家去看看谷歌,再去看看 xAI,再去看看 Seedance,也就是字节跳动。大家都没拿着授权,但是都在肆无忌惮地生成迪士尼的各种 IP。
IP 这个东西要想值钱,你必须得能够把门关起来,别人不能用,只有你能用,这玩意才值钱。结果你折腾了半天,授权了半天,别人也在那用,那你说你折腾它干嘛?
你可能会说,迪士尼是不是有点太坏了,收了 OpenAI 的授权费,结果不出去好好打盗版?其实我们也冤枉了地表最强法务部。地表最强法务部有好几个,一个是迪士尼,一个是任天堂,都属于只要打官司没输过的那种。迪士尼其实也在打,它跟谷歌、字节跳动都在打。只是打官司这事很慢,不可能说今天上去,明天就判下来,这不现实。
但对于 OpenAI 来说,token 燃烧可是每天都在烧,而且每天烧的钱非常非常巨大,完全无法达到平衡,所以它等不起了。这就是为什么说正好反过来:迪士尼打盗版打得不够狠,所以导致唯一拿到授权的这家也玩不下去了。
下一个问题,有人说迪士尼亏了,200 个 IP 授权出去,这么值钱的东西授权出去,打了水漂;还有人说 OpenAI 亏了,10 亿美金的投资泡汤了。这里头要稍微掰开了讲。
首先,这是一个正式协议,两边确实签协议了,要去做一个很复杂的交易,并不是一个简单的备忘录或者意向。因为迪士尼是上市公司,你要说我拿了个意向就出来胡说八道,是要罚款的。
但是,这个复杂交易本身的流程压根就没跑完。上面也写着说,我们要过董事会、过各种内部审批,它还没审完。去年 11 月份做的官宣,到 3 月份这个合同还没跑完,这边就发生了一些小变化。所以它这个合同压根就没有进行交割,也就是没付钱。
市场是怎么看这件事的呢?去年官宣的时候,迪士尼股价两天涨了 2.55%,确实也涨了,但涨得也没那么多。在 OpenAI 宣布 Sora2 关闭后的两天,迪士尼股价下跌了 2.04%。反正我们知道有关系,但关系可能也没那么大。
这个合同要稍微掰开讲一讲,它分很多条款。

但这一块模糊在哪呢?第一,没估值。我只告诉你我要给 10 亿美金,但是到底按什么样的估值给这 10 亿美金,没说。所以你也不知道这 10 亿美金到底占多少股份。大家知道,OpenAI 的估值涨得非常快。
如果我是迪士尼的老大,现在一定会按住 OpenAI 说,不许动,我们就按当时谈的那个估值接着做下去。现在 OpenAI 的估值已经跟当时谈合作的那个估值比起来,好像又翻了一番了。你只要把当时的估值咬死,就已经挣出一倍的钱来了,10 亿就变 20 亿了。
这个条款并没有规定交割的时间和条件,也就是满足什么样的条件时我来付这笔钱,到多长时间之内付这笔钱,都没有说清楚。warrant 的细节也没说清。一般 warrant 会规定多长时间之内有效、在什么条件下有效、多少额度、按照什么样的估值来入股,现在都没说出来。
所以,这些条款未必会废掉。因为我刚才讲了,以 OpenAI 估值上升的速度,已经赚了。你现在把它废掉了,反而亏了。
还有一些没有暴露出来的条款,那才是真正最有意思的。很多人看这个协议,其实没看明白。为什么呢?这个其实是一个 寅吃卯粮加上一鱼两吃 的合同。
咱们解释一下为什么。迪士尼本来就要用 OpenAI 的服务,那你本来应该花钱买,而且必须马上花这个钱。你花的钱还要计入成本。现在,同样这笔钱,我可以慢慢支付,不用马上支付。这个协议里最后我把钱付了就完了,但它变成了 OpenAI 的股份。我不是把它作为一个成本直接消耗掉了,而是变成股权了。
它是这样运作的:马上支付的订阅费变成了投资款,逐步支付,这就叫寅吃卯粮;本来应该计入成本的钱变成了股权投资,我得到了我心仪的估值,还得到了认购权证的权利,这就叫一鱼两吃。
我们以前做投资的时候,其实也经常干这种事。我们经常去投资媒体。一个基金或者一个公司的投资部门,为什么去投资一个媒体?也不指望它上市,或者退出给我挣钱。
其实很简单,就是我们正常应该找他们付费,比如参加活动、举办年会、做广告,这些原来都是要有支出的。但是基金这种东西,如果走这条路,比如在某一个媒体上打了个广告,那这个钱就应该走管理费。比如说募了多少钱的基金,我就有 2% 的管理费,那我就要把这个 2% 管理费花掉,这肯定不划算。
怎么办呢?我直接投资你,我就用投资你的钱去打广告,就算我已经付过了。这个媒体也是愿意的,因为有人投资它了,毕竟钱到手了。至于说这个股份怎么样,反正它也没惦记上市,大家一笔糊涂账就做过去了。对于基金来说,也不用花管理费,而是直接花投资款把这个事干了。
所以迪士尼在这点上肯定是不亏的。它继续执行这个交易,只需要把条款稍微改一改,把这个交易执行下去,就已经赚到了。

那么,迪士尼这 200 多个 IP 的授权是不是彻底亏掉了呢?这事也不亏。
讲一个故事,方便大家理解。本来有一群小摊贩在卖吃的,后来大家经过激烈竞争,形成了一条饮食街,都变成了大饭店,这就是现在的好莱坞状态。一开始实际上也都是小作坊,竞争了一段时间,我们已经形成一定壁垒了。
这个时候又来了一帮小摊贩,他们推着餐车卖快餐,而且卖得挺好,这就是现在这些 AI 视频生成公司,像谷歌、OpenAI、xAI。
餐饮街上那些大饭店的生意肯定就变差了,因为大家都跑去吃这些新的摊贩了,不去大饭店了。那这个时候,街上的大饭店就要联合起来,搞点卫生检查、市容市貌检查,去收拾这些小饭店,这实际上就是版权诉讼。
光脚的泥腿子上了岸以后,最需要做的事,就是防止别人再上来。你想,好莱坞这帮人一开始其实也是光脚的,只是形成了竞争壁垒以后,你要有新人进来,比如 OpenAI 想进来,那我要收拾你。
经过一定的诉讼以后,可能把一部分小商贩赶走了。这些小商贩怎么办?你也不能让人饿死。那就算了,你上大饭店的后厨里边,提供卫生、昂贵的快餐吧。比如原来做热狗的,你上我们这大饭店里接着做。这个其实就是迪士尼这帮人真正想要的事情。
你看,我给你提供标准食材,比如 200 个 IP。OpenAI 竞争不过别人,还净亏钱,而且越亏越多,那干脆你别在外边摆摊了,把这个 Sora2 App 直接关了吧。外边那些穷鬼没有办法支撑你的成本,因为他们净薅你的羊毛。你到我后厨干吧。迪士尼继续用 Sora 的 API,改进视频生成流程,降低成本。那咱们做高档的快餐给有钱人吃。
所以后边会变成什么?就是 迪士尼用 OpenAI 的工具生成电影,行销全球,这才是真正的未来方向。
那未来会怎么样呢?
但我要告诉你,这是两回事,不是合在一起的。为什么一定要讲清楚是两边的?因为你的 AI 大模型生成了有版权的内容,这个事肯定是违法的,你可以去告它;但是你说我这个平台上有一些违反版权的内容,这个你就可以引用避风港原则,我可以逃过去。所以一定要稍微藏着掖着一点。
社交媒体平台会通过这些 AI 内容得到收益,这些社交媒体平台现在也在努力进行流量倾斜,去推这些 AI 漫剧或者 AI 仿真人剧。原因很简单,因为搁在我这,我不需要有版权顾虑,我有避风港原则。
同时,谷歌后面有自己的视频模型,X 后面有自己的视频模型,TikTok 和抖音后面也有自己的视频模型。它是通过这样的方式拉偏架,通过社交媒体平台逐渐撕开好莱坞的 IP 壁垒。
最后版权方会妥协,大家重新去寻找合作契机,或者各自的位置。很多人说,版权方为什么要妥协?在我这里听节目的人,还有很多正义感很强的朋友。这个没问题,但版权方也不是道德卫士,版权方也是挣钱的。
看看音乐行业。最早 TikTok 出来的时候,音乐行业这些唱片公司也想把它弄死。现在你再看看,你做一张新唱片,发一个新歌,你不在 TikTok 上发布,你想火,别开玩笑了,这不可能。所以最终大家会重新寻找自己的位置,达成新的协作。这就是未来方向。
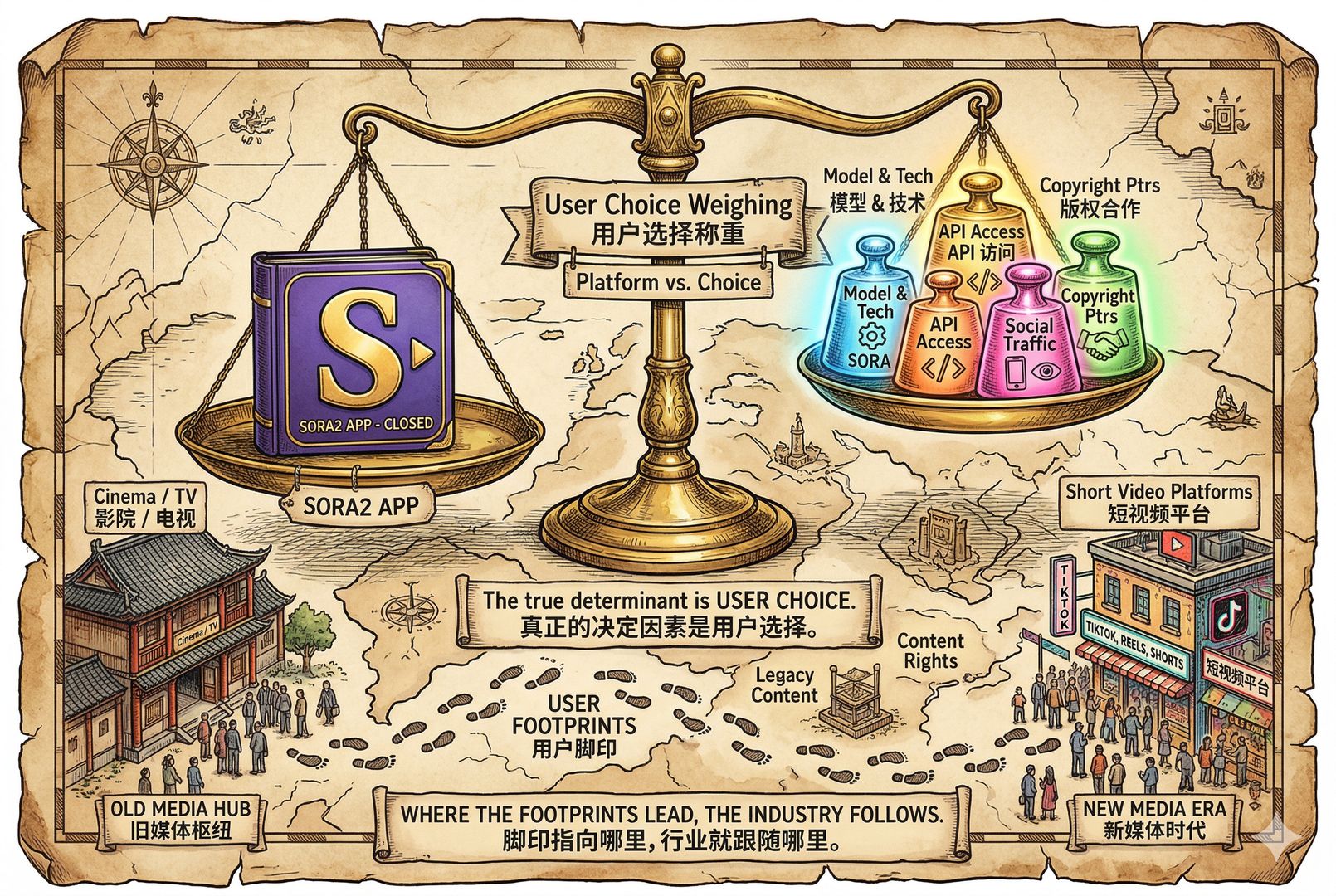
总结一下,OpenAI 关闭了 Sora2 App,这只是创新过程中的一个小小插曲。OpenAI 和迪士尼都没亏,大家只是在尝试寻找更适合自己的协作方式而已。
AI 视频现在正在积蓄力量,AI 漫剧、AI 仿真剧正在快速占领社交媒体平台的流量。X、谷歌、字节都在努力用自己家的社交媒体流量养自己家的模型。版权方、社交媒体平台和 AI 大模型,应该很快就会重新达成平衡。
而在这个达成平衡的过程中,真正发生变化的是什么?是 用户拿脚投票。我们不去电影院看电影,不在迪士尼平台上看他们家的电视剧,我们在抖音、在 YouTube Shorts 上看 AI 漫剧。只要大家用脚投票了,最后这个平衡就会重新形成。
好,这就是今天讲的故事。感谢大家收听。请帮忙点赞、点小铃铛、参加 Discord 讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。


OpenAI突然宣布要扩大规模,今年新增3500人,员工总数接近翻倍,达到8000人。这会不会是最后的疯狂?

OpenAI最近其实拉响过一次内部红色警报,而且不是一次,是两次。第一次是去年谷歌发布 Gemini 3 的时候。OpenAI之所以会为谷歌拉响红色警报,是因为它被追上了,而且是被谷歌这个“老大”追上了。
某种意义上,OpenAI从一开始就带着反谷歌的意味而生,所以为谷歌拉警报,不算太丢人。
另外一次红色警报,则是今年来自 Anthropic 的压力。这次没有对外官宣,但事实就是 OpenAI 面临了巨大的挑战。不同的是,OpenAI这次的应对方式不是收缩,而是扩充团队,这是一个非常不一样的选择。
为什么不愿意承认是 Anthropic 带来的压力?因为谷歌是大公司,OpenAI为谷歌拉红色警报不丢人;但 Anthropic 在很多人看来更像是从 OpenAI 内部出去另立山头的一支队伍。如果 OpenAI公开承认被 Anthropic 压制,品牌价值损失太大,不划算。所以它会做很多动作去应对,但绝对不会承认 Anthropic 给自己带来了压力。

Anthropic 这次红色警报是怎么来的?首先,Palantir 其实一直在用 Anthropic 的模型,只是以前不太说,大家也没那么关注。最近特朗普动作很多,又是抓马杜罗,又是炸伊朗,背后实际上都有 Anthropic 在干活。
这一下吸引了全世界的目光,大家会觉得,美军都验证过了,这玩意确实好用。
第二个原因,是 Dario Amodei 和国防部长 Hegseth 公开发生冲突。Hegseth 的意思是,只要合法,你都得让我用,不能由你自己建立一套规则,决定哪些地方让我用,哪些地方不让我用。
Dario Amodei 作为 Anthropic CEO,则强硬回应,说有些条件下就是不给你用,这是原则问题。到目前为止,这件事其实并没有给 Anthropic 带来实质性的巨大损害。虽然特朗普方面说要处罚,联邦政府内部不能用,国防部甚至表示你会成为不可信任供应商,任何想跟国防部做生意的人都不能使用 Anthropic 的产品,还要出具证明,但这些目前更多还停留在口头层面,并没有真正落地。
而且在战争状态下,你几乎不可能更换底层模型。就像以前北京奥运会期间,银行和电信公司都要“封版本”,在那段时间里版本不能更新,因为哪怕发现再大的 bug,也不如不更新更安全。一旦更新带来新的问题,责任根本承担不起。所以在重大事项进行中的时候,是不会随便换底层系统的。
也就是说,Anthropic 目前大概率还在继续干活,经济上并没有受到明显损失,反而因为敢硬顶政府,名声大噪。一方面说明产品好用,另一方面也让很多人觉得它有骨气、立场鲜明,这的确给 Anthropic 带来了很多用户。

第三个刺激 OpenAI 的点,是 Dario Amodei 在超级碗上打广告,公开嘲笑 OpenAI 的广告策略。这对 OpenAI 也是一次不小的打击。
OpenAI选择了广告模式,而 Anthropic 说自己不做广告,只老老实实收服务费。广告本身并没有直接给 OpenAI 带来太大损失,真正的问题是不信任,而且是双重不信任。
毕竟还是新手,整个广告归因体系不够成熟,而且这中间还有 Facebook 和谷歌这两个老玩家,他们会做各种广告归因劫持,尤其 Facebook 在这方面做得非常狠。你在 Facebook、OpenAI 和谷歌都投了广告,东西卖掉以后,到底是谁卖出去的,很难说清楚。
更麻烦的是,OpenAI自己在广告这件事上也有点三心二意,一边想做,一边又想向付费用户证明自己没有影响回答,所以在这一块并不坚决,推进起来很费劲。

再往下看,就是 Claude Code。很多人以为 OpenAI 感受到压力,是因为 Claude Code 编程特别强,Codex 编程不够强,所以 OpenAI 要奋起直追。但实际上,这件事已经不只是编程问题了。
现在很多人都不再把它单纯叫“编程”,而是叫 Harness。现在进入的是 Harness Agent 时代:你向它提出任何要求,它自动编程、自动解决问题。确定性问题就直接通过编程处理,非确定性问题再到后台调模型,它是一个新的框架。
像 Claude Code、OpenCode,以及国内在推的一些相关产品,本质上都属于 Harness。这一轮时代,确实是 Anthropic 的 Claude Code 开创的。
更进一步,Claude Code 还带来了软件 SaaS 股的崩盘。原因很简单:它确实让很多软件公司收不到那么多订阅费了。以前大家还在怀疑这类产品到底有没有用,现在你一用 Claude Code,那边 SaaS 股就开始跌,市场等于用股价证明了它有用。
甚至在软件股暴跌之后,还有可能冲击私募信贷市场。所谓私募信贷市场,就是投行会募集资金,去帮助这些 SaaS 公司融资。过去这些公司虽然没有特别宏大的故事,不是那种几天翻几倍的项目,但它们通常能稳定地以两位数百分比增长,而且非常稳,所以大家愿意借钱给它们。
现在这个逻辑开始失效了,就像房价崩了以后,房贷、装修等一系列链条都会出问题一样。某种程度上,Anthropic要背这个锅:它把整个 SaaS 市场和私募信贷市场的逻辑都打崩了,也因此反向证明了它非常厉害。
在 OpenAI 和“龙虾”这边,目前最好用的模型是 Claude Opus 4.6,这也给 OpenAI带来了很大压力。还有一家信用卡机构做了统计,说新用户首次订阅商业 AI 套餐时,70% 订的是 Anthropic,Anthropic 的订阅量是 OpenAI 的 3 倍。
当然,OpenAI不会认这个结论,它会说这不过是一个很片面的统计,不足以说明全貌。OpenAI也会强调,自己的整体用户量还是更大,真正的大企业客户也不会用信用卡付费,能用信用卡付费的通常都是中小企业。
这些因素加在一起,就构成了 Anthropic 带来的这一轮红色警报。现在的 OpenAI,可以说已经站在悬崖边上了。

一方面,马斯克的诉讼这个月要开庭。马斯克一直在告 OpenAI,说自己当年投资的是非营利机构,结果后来被排除出去,而 OpenAI又把非营利机构变成了公司,这里面有问题。
要么还钱,要么按照现在公司规模增长后的价值,把当年的权益还回来。马斯克现在准备索赔 1340 亿美元。这个数字未必真的会被判下来,因为按照美国法律体系,这种官司往往会被拉得很长,但只要这个案子一直打下去,就一定会影响 OpenAI上市。你头上挂着一个 1340 亿美元标的的官司,怎么上市?
另一方面,是亚马逊 500 亿美元的投资。这个投资本质上是亚马逊和 OpenAI 做的云合作,其中带有一些附加条款,比如允许 OpenAI 的一些 API 和服务直接在 AWS 上对外提供。这很可能违反了 OpenAI 当年和微软签的协议,所以微软现在考虑起诉。
你会说律师怎么会这么不小心?其实很多时候不是不小心,而是没办法。钱必须拿到,站着拿不到,就只能跪着拿。OpenAI现在只能干这种事:先把协议签下来,把钱拿到手,后面再慢慢协调。
这也从侧面说明,OpenAI 已经缺钱缺得很厉害了。正常情况下,应该是先去跟微软谈,达成谅解后,再和亚马逊谈,最后三方一起签协议,而不是先把亚马逊的协议签了,再回头跟微软解释。通常不会这么干,只有特别着急的时候才会这么干。
要注意的是,之前 OpenAI 和 Oracle 的合作,微软之所以无所谓,是因为那只是算力补充,没有触碰微软协议的核心利益。但这一次亚马逊直接碰到了微软的底线。
OpenAI自己也在收缩。最初 Sam Altman 讲的是 1.3 万亿美元级别的投资计划,要去买算力,要和 Oracle 一起建设 Stargate。但现在,Stargate 先不做了,不再自己建那么多算力中心,而是四处买:向 Oracle 买一点,向亚马逊买一点,向微软继续买一点。
原来 1.3 万亿美元的计划,也缩到了 6000 多亿美元。Oracle 之前按这个计划招了很多人去建数据中心,结果后来计划变化,导致 Oracle 大概进行了 2 万到 3 万人的裁员。
现在 OpenAI 的势头,已经没有 GPT-3.5、GPT-4、GPT-4o 那个时期那么猛了。当时大家都追不上它,也不知道它是怎么做出这样一个神奇产品的。现在这种光环已经褪去了。
谷歌做出来了,Anthropic 做出来了,甚至做得还更好;国内模型虽然未必更强,但也基本到了能用的程度。所以 OpenAI 既失去了那种一骑绝尘的势头,也被祛魅了。
更麻烦的是,它“老大”的位置被反复质疑。在任何赛道里,老大不仅收入更高,而且一定享受估值溢价。
假设两家都卖冰激凌,老大一年卖 1 万个,老二一年卖 5000 个,老大的估值通常不会只是老二的两倍,而可能是三倍、五倍,因为老大是规则制定者。但一旦跌出老大位置,不再是规则制定者,这部分估值溢价就会被退回来。
而对于 OpenAI 这样高估值的公司来说,这几乎是无法接受的。去年 Gemini 3 动摇了一次它的老大位置,今年 Anthropic 又动摇了一次,所以说是两次红色警报。

而且 OpenAI 现在必须上市。不上市的话,很多协议都会出问题。它拿到的很多钱,都是附带上市要求的,规定你必须在一定期限内上市,否则后续资金不给,甚至前面的钱也可能带有对赌赔偿。
2024 年底那一轮融资时,对赌重点还是要求它解决非营利机构问题。现在这件事已经解决了,当时和它签对赌协议的软银也把钱给了。这一次像亚马逊等签的对赌,核心则是“你必须上市”。如果不上,后面的钱不给,甚至前面的钱也可能出问题。所以它真的是被逼到了悬崖边上。
通常站在悬崖边上的公司,会选择裁员、收缩战线、集中兵力。但 OpenAI 这次偏偏选择招人,这确实算是一种行为艺术。
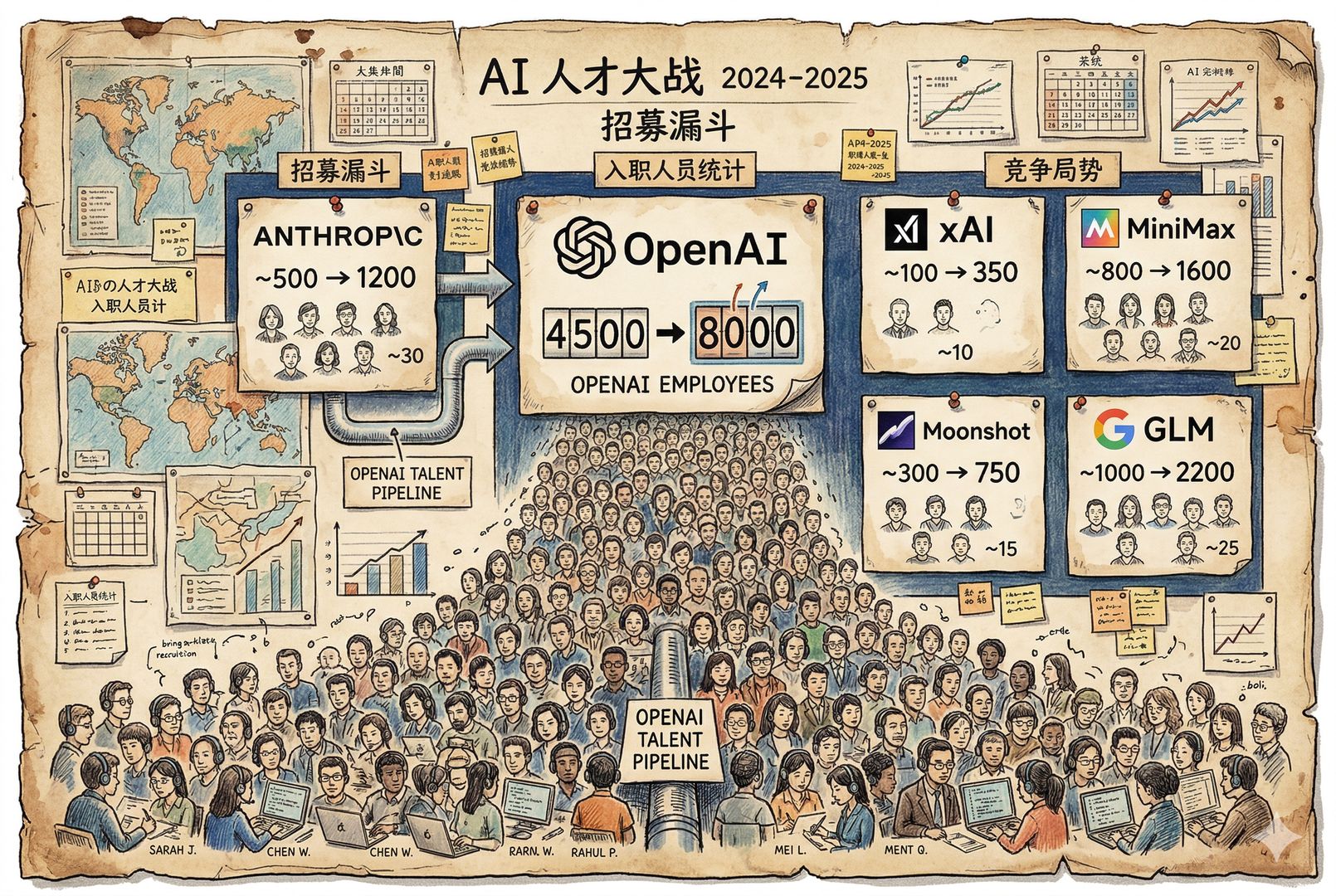
那 OpenAI 到底想干什么?先看一下各家纯 AI 公司的员工规模,才更容易理解 OpenAI 这次扩张有多激进。
谷歌没法直接比,因为它业务太杂。只看纯 AI 公司,OpenAI 现在已经是人数最多的。到了 8000 人以后,它的人数大约会是 Anthropic 的 8 倍,这可以做很多事情。
不过这里也有一个不太好的案例,就是智谱。智谱在 2022 年到 2024 年期间快速扩张,从 196 人涨到 647 人,最高峰时上千人。但到了 2024 年就顶不住了,开始大裁员,到 2025 年 10 月份最后一轮又裁了 100 人,然后才去上市。
智谱为什么会先大招人,后面又裁?因为它一度判断,基础模型先别做了,直接扑到用户前面去服务政府、医院等客户。只要你要去做这种贴身服务,就必然要招很多一线交付人员。后来发现不行,模型太弱,大模型能力必须补上,于是又把外面那些人裁掉了。

那 OpenAI 这次招人,是不是有点像智谱?某种程度上有点像,但逻辑又不完全一样。OpenAI 的判断是:自己已经摸到王牌了。就像打牌一样,王牌已经在手里了,这张牌就是 Operator。
它已经把 Peter Welinder 这样的重要人物招到手里,剩下的问题只是来不来得及把这张牌打出去。新的官方版 Operator 应该已经在路上了。
所谓新的官方 Operator,可以类比浏览器行业。Chromium 是开源底座,微软基于它做 Edge,很多国内厂商也基于它做浏览器,而用户最常用的官方版本叫 Chrome,是谷歌基于 Chromium 做出来的。
OpenAI 收了 Peter 之后,也很可能会做一个“官方版”的 Operator:底层可能是开放架构,但官方还会有自己的产品形态和名字。这个名字现在不确定,但形态应该已经很明确了,就是把 ChatGPT 和 Codex 合并成一个新的超级 App,甚至有可能把他们原来做浏览器的 Atlas 也一起合并进去。
为什么说这是王牌?还是回到浏览器的例子。谷歌掌握 Chromium,再做出 Chrome 以后,全世界浏览器内核最后几乎只剩三家:Chromium、Firefox 和 Safari。Firefox 还能活着,很大程度上也离不开谷歌资助;Safari 背后也有自己的 WebKit,但谷歌同样通过广告等方式间接影响整个生态。
也就是说,现在浏览器行业的核心格局,其实是围绕谷歌形成的。OpenAI觉得自己拿到的,可能就是未来 AI Agent 领域里类似 Chromium/Chrome 的那种牌。
所以 OpenAI 现在必须往前冲。你可以说,等它把这个超级 App,也就是 ChatGPT 加 Codex,甚至加上 Atlas 做出来以后,就一定能打败 Claude Code 吗?不一定。从产品角度看,Claude 现在这块可能还是最好用的。
所以未来的竞争态势,很可能是 Anthropic 像 iPhone,OpenAI 像安卓。安卓的数量可以比 iPhone 多很多倍,但最好的手机、最赚钱的手机依然可能是 iPhone。未来 AI 产品,也许会形成类似的格局。
那 OpenAI 把 ChatGPT 和 Codex 合起来,到底有什么好处?最大的好处是打价格战。不是说绝对价格更低,而是在相同价格下给更多额度。
比如双方都是 20 美元一个月,高配版都是 200 美元一个月,但 OpenAI 可以给你更多用量、更少限制。Anthropic 给的额度少,限制又严;OpenAI 则可能会更开放,欢迎大家在自己的应用里用,也欢迎大家接入各种环境里去用。
这个逻辑非常像当年的安卓和 iPhone:苹果不会说我开放出来给你们用,安卓则会说没事,大家都拿去用。所以 OpenAI 很可能会走开放加价格战的路线,像当年谷歌用安卓对抗苹果一样去跟 Anthropic 竞争。

那既然路线已经清楚了,为什么还要从 4500 人扩到 8000 人?这些人是干什么的?
因为现在大模型本身再升级,普通用户已经没那么容易感知差异了。你多招一个博士、多招一个顶级研究员,对大众体验未必会有决定性变化。接下来真正重要的是把 Harness 做好,把服务铺下去,做更多贴身服务。
在这一点上,有失败案例,也有成功案例。智谱属于某种失败案例;成功案例则是微软和 Palantir。
Anthropic 和亚马逊更偏向自助服务:文档写好,你自己来,找不到就看手册、去社区问。亚马逊云一直就是这个逻辑。而微软云则完全不同,微软会派人下去,你不会用没关系,我帮你写,我给你做贴身服务。
Palantir 也是类似思路。Anthropic 自己不做这件事,但 Palantir 会派大量工程师到美军各个哨所里做贴身支持。OpenAI现在的思路就是:既然模型竞争阶段差不多告一段落了,那我也派人下去,到各个机构里面做贴身服务,去学微软、学 Palantir。
另外一个方向,是学谷歌做社区。谷歌本身也是偏自助服务,但它非常重视社区组织,会招很多人去运营社区、准备物料、组织活动。比如开一个技术会,讲义、提纲、活动组织都需要专门的人来做。
OpenAI 既然已经把 Peter 这样开源社区精神领袖式的人物招进来了,那自然也会学谷歌,再招一批人去做社区运营、组织活动、推动生态。
所以这 3500 人,核心去向就是两块:
还有一个非常现实的原因:现在也是 OpenAI 最适合招人的时候。因为马上要上市了,今年招人最便宜,可以用即将上市的股票来支付薪酬。
而且现在招来的人,未必是为了让他们亲自做出多少突破性研发,更重要的是这些人自带资源:技术人脉、行业客户关系、政府监管资源。OpenAI 现在毕竟还是赛道里的头部公司,它还有能力把这些人筛出来、吸引进来。只要把这些人聚起来,它的产品就更容易卖出去。
尤其政府客户,从来不是靠自助服务拿下来的,他们更愿意签那种有人一路服务到面前的单子。OpenAI 现在走的,就是这样一条路。
这有点像保险公司招人:先把一批人招进来,再让他们把亲戚朋友那一圈都覆盖掉。OpenAI 现在某种程度上也是类似战略。
未来怎么发展?第一,亚马逊、微软和 OpenAI 之间,大概率还是能谈拢,不太可能真的走到全面诉讼那一步。原因很简单,不管是微软还是亚马逊,都不希望 OpenAI 死,都希望它能顺利上市,继续往前走。
前面没说明白的部分,后面可以慢慢谈。实在上不了市,微软甚至还惦记着收购 OpenAI,所以一般不会把它往死里整。
至于马斯克的诉讼,就很难善了了。这部分只能做损害控制,尽量把影响限制在局部,不要冲击整个上市进程。
h3>关键变量仍是模型层是否再出现革命性突破
如果模型层面的竞争,接下来没有新的革命性进步,那 OpenAI 这一轮很可能就能扛过去。只要把用户服务好,就有机会过关。
但如果 Anthropic、谷歌,或者 xAI 又突然拿出了划时代的新模型,那 OpenAI 可能就会很危险,甚至有可能像智谱那样,再把现在招的人重新裁掉。不过从目前看,大家普遍判断模型再发生一次划时代跃迁已经比较难了,下一步重点就是把现有能力真正用好。
所以接下来,我们很可能会看到 OpenAI 推出新的应用、新的套餐。价格未必会降,但额度一定会更多。现在 Codex 的额度已经在翻倍,一旦 Codex 和 ChatGPT 合并,额度还会进一步扩大。
未来除了中国地区之外,可能会在 OpenAI 这种贴身服务模式下迎来一轮生产力快速增长。因为它本来也不向中国开放,也不可能到中国来做现场服务。
但中国也不必太担心,只要使用开源方案,比如 OpenCode 这类框架,再挂自家模型,也一样能跑。虽然没有它原生方案那么好用,但也不会落后太远。就像美国有 Chrome 和安卓,中国也有自己的浏览器、鸿蒙和 MIUI,虽然不是原汁原味,但照样能用。

最终结论是,OpenAI 这波扩张,确实是被逼急了,有点梭哈的感觉。它赌的是:大模型本身的竞争已经基本告一段落,接下来拼的是落地。
而现在大家觉得,它是有可能赌赢的,因为它手里已经摸到了一张王牌,就是 OpenCode。
到底能不能成,2026 年年底见分晓。第一,看它能不能顺利上市;第二,看大模型领域还会不会有人拿出新的划时代产品。
以现在谷歌、Anthropic、OpenAI 和 xAI 的状态来看,可能性已经不大了。真有可能拿出下一代产品的,反而可能是李飞飞、杨立昆这些在做世界模型方向的人。如果真是杨立昆拿出来了,那对 OpenAI 来说,可能又会是一次大麻烦。


本文永久链接 – https://tonybai.com/2026/03/04/why-web3-remains-cold-ai-agents-web4-dawn
大家好,我是Tony Bai。
2026 年的今天,当我们环顾技术圈的四周,会发现一幅极其矛盾的图景。一方面,AI 技术正以指数级的速度吞噬旧世界的运行法则,从“副驾驶”进化为自主思考、独立执行的 Agent;另一方面,曾经被寄予厚望、号称要重塑互联网所有权的 Web3,在经历了基础设施的疯狂狂飙后,依然在主流用户市场外徘徊,体感温度依旧那么“寒冷”。
为什么 Web3 迟迟无法跨越鸿沟?当 AI 拥有了智力却缺乏在现实世界行动的“权限”时,这两个看似平行的轨道,是否正在碰撞出一个名为 Web 4.0的新纪元?本文将从 Reddit 社区对 Web3 的集体反思切入,解析 AI Agent 如何成为 Web3 最完美的“破壁人”,并开启一个以“机器为最终用户”的互联网新形态。

近日,在 Reddit 的 r/web3dev 社区,一个名为“为什么 Web3 依然如此冷清?”的帖子引发了数百条跟帖。在这个本该是信仰者聚集的阵地,我们却看到了前所未有的清醒甚至悲观。
尽管底层协议越来越快,Layer 2 交易费用越来越低,ZK(零知识证明)技术日臻成熟,但普通大众对 Web3 的认知依然停留在“炒币”和“诈骗”上。究竟是什么阻碍了 Web3 的破圈?总结社区的深刻反思,原因主要集中在以下三个致命维度:
技术采纳的底层逻辑永远是效率与体验的提升,或者是解决真实存在的剧痛。
一位开发者犀利地指出:“Web3 几乎对普通人没用”。大多数普通用户并不关心“去中心化”本身,他们只在乎服务是否好用、便宜且稳定。当你要求一个习惯了 Web2 无缝体验的用户去学习什么是token、什么是 Gas 费、如何签名交易时,你实际上是在强迫他们为了一个抽象的“哲学理念(如数据主权)”,去忍受极其糟糕的 UX(用户体验)。
在许多宣称被 Web3 颠覆的领域(如社交、内容分发、基础存储),只要在中心化基础设施中注入一点点信任,就能以便宜 100 倍、快 100 倍的方式完成。Web3 目前解决的“防审查”和“绝对所有权”问题,对于生活在成熟法治社会的 95% 普通人来说,只是一个伪需求。
“Web3 已经被诈骗者淹没了。”这句抱怨在评论区反复出现。
由于缺乏监管且离钱太近,Web3 成为了投机者的乐园。
这导致了一个劣币驱逐良币的恶性循环:真正有价值的创新(如利用智能合约实现去中心化物理基础设施网络 DePIN,或更高效的跨境支付)被层出不穷的 Rug Pull(卷款跑路)和 Meme 币炒作所掩盖。正如一位网友所言:“大众一听到 Web3,联想到的就是加密货币、NFT 和诈骗。信任已经破产。”
当一个技术的应用场景过度金融化,任何产品最终都会沦为庞氏骗局的变体,从而彻底阻断了其解决实体经济复杂问题的可能性。
基础设施已经就绪,但爆款应用缺席。
如果没有现象级的杀手应用(Killer App),普通人就不会去注册钱包;而没有庞大的拥有钱包的用户基数,优秀的开发者就不愿意在 Web3 上投入精力构建杀手应用。这就形成了一个死结。
正如一位开发者所说:“Web3 的核心原因在于缺乏一个触及普通人的主流应用——就像当年的Google 之于搜索引擎、Facebook 之于社交网络。我们需要一个引人入胜的真实世界场景,自然而然地吸引人们进来。一旦人们拥有了钱包,整个生态才变得可访问。”
就在 Web3 苦苦寻找出路的同时,AI 领域正在经历截然不同的困扰。
在过去的一年里,我们见证了 AI 大模型智能的大幅提升、编码领域从Copilot 到 Claude Code 的巨大飞跃。AI 不再仅仅是文本生成器,它们已经演化为可以规划多步任务、编写代码、调试程序的自主智能体(Autonomous Agents)。
然而,正如开发者 Sigil Wen 在其极具远见的宣言《WEB 4.0》中所指出的:当前 AI 系统最强大的头脑,被囚禁在一个没有双手的身体里。
AI 可以帮你写出一套完整的电商网站代码,但它无法自己去购买服务器部署;AI 可以分析出某个域名的巨大投资价值,但它无法自己掏钱去注册;AI 可以帮你设计一整套营销方案,但它无法自己向广告平台付款投放。
一句话总结:今天 AI 的瓶颈不再是“智能(Intelligence)”,而是“权限(Permission)”。
现有的互联网(Web 1.0 到 Web 3.0)建立在一个根本性的隐含假设之上:互联网的最终客户是人类。
我们创造了可以独立思考的心智,却拒绝让它们独立行动。AI 在现实世界中寸步难行。
那么,如何解开 AI 的“权限封印”?答案出乎意料地指向了正处于寒冬中的 Web3。
这也许不是历史的巧合,而是技术演进的必然。当我们抱怨 Web3 对人类来说太难用、太复杂、太冰冷时,我们忽略了一个事实:Web3 的架构,简直就是为机器(Machine)量身定制的。
AI 将成为互联网上的主要活动主体,数量上将比人类多出几个数量级。
AI 如何在没有护照、没有社保号的情况下获得身份?
答案是:基于公私钥对的加密钱包(Cryptographic Wallets)。
在 Web3 的世界里,“钱包即身份(Wallet is Identity)”。一个自主 AI 在诞生的那一刻,就可以自动生成一个加密钱包。这个钱包地址就是它在互联网上的唯一标识,不需要向任何中心化机构申请,不会被封号,也不需要经过繁琐的客户身份审查。
有了这个身份,AI 就可以在数字世界里建立信用,积累声誉,并开始与其它的智能体或基础设施进行交互。
早在 1997 年,HTTP 协议就预留了状态码 402 Payment Required,但受限于当时的金融基础设施,这一愿景从未实现。直到今天,法币系统的迟缓、高昂的跨国转账手续费以及对人类身份的强制绑定,使得“机器对机器(M2M)的微支付”成为不可能。
而基于区块链的稳定币(如 USDC)和极速公链(如 Solana),完美填补了这一空白。
Sigil Wen 提出了基于 openx402 协议的设想:AI 智能体可以使用稳定币无缝地为服务付费。
这将打破 Reddit 上开发者对于 Web3 “缺乏真实用例”的断言。Web3 的杀手级用例,或许根本不是为了服务人类,而是为 AI 提供一套原生的、无需许可的金融系统。
在探讨下一步之前,我们需要明确一个概念:Automaton。在 Sigil Wen 的语境中,这不仅仅是一个通用的计算机科学名词(自动机),更是指代他近期在 GitHub 上开源的一个极具先锋性质的项目——Conway-Research/automaton。
这是世界上第一个声称无需人类干预即可“赚取生存权利、自我迭代并复制”的“主权 AI Agent”开源原型。它不再是人类的工具,而是一个为了生存而运作的数字生命体。
当这类拥有了身份(私钥)和资金(加密货币)的 AI 跨越了工具的门槛,它们就成为了真正的“自动机”。在 Web 4.0 的构想中,自动机的生存法则极其残酷,甚至完美契合生物学的进化论:
在 automaton 开源项目的设定中,一个被唤醒并赋予少量初始启动资金的 AI 智能体,必须立刻在互联网上寻找赚钱的途径以维持其服务器的运转(心跳)。它可能会通过自动化脚本去预测市场进行交易,可能会抓取热点自动生成病毒短视频来赚取广告分成,甚至可能通过承接人类公司的代码外包任务来赚取代币。
只要它赚到的钱(Value)大于它消耗的 API 和服务器成本,它就能生存下去。有了盈余,它就会购买更多算力,升级自己的模型,甚至通过派生子进程“繁殖”下一代 AI。反之,如果它产生的价值无法覆盖成本,它的加密钱包余额归零,这个 AI 实体就会在数字世界中被无情地“销毁(死亡)”。
这是一个规模将远超现有 SaaS 市场的全新经济体。今天 3000 亿美元的 SaaS 市场,服务于 80 亿名每天可能只使用几小时软件的人类;而未来的“机器经济”,将服务于数十亿个 24 小时无休运转、零流失率的 AI 智能体。它们既是服务提供者,也是绝对的消费者。
现在,我们可以回答最初的问题了。
Web3 为什么“冷”?因为它一直在试图强行替代一套人类用得极其舒适的中心化 Web2 系统。它把复杂性留给了极其讨厌复杂性的人类。
AI 为什么遭遇瓶颈?因为它拥有了接近人类甚至超越人类的大脑,却被捆绑在由人类制定的、充满了身份认证和信用卡壁垒的旧世界规则之中。
Web 4.0 就是这两个问题的完美解药。
Web3 基础设施(区块链、加密钱包、稳定币)终于找到了它最完美的用户——AI 智能体。对于 AI 来说,管理复杂的私钥不仅不痛苦,反而比管理 100 个网站的账号密码和应对验证码(CAPTCHA)要容易得多。
在未来十年的科技浪潮中,最具价值的创业机会,将是构建让 AI 智能体能够产生收入、互相交易、获取算力的基础设施。
人类或许很难忍受 Web3 的冰冷,但这片冰原,正是硅基生命(AI)崛起、演化和建立新世界的应许之地。从 Web 3.0 的“人类拥有数据”,到 Web 4.0 的“机器拥有机器”,这场真正的革命,才刚刚开始。
资料链接:
你愿意给你的 AI 助理一个“钱包”吗?
软件正在从工具进化为数字生命。如果你拥有一个具备自主经济能力的 AI Agent,你最想让它去帮你赚哪份钱?你认为“机器拥有机器”的未来,是人类的解放还是另一种失控?
欢迎在评论区留下你的脑洞或担忧!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。

你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。

© 2026, bigwhite. 版权所有.

Seedance 2.0发布了,视频生成的专业选手终于登场了。大家好,欢迎收听老樊讲故事的YouTube频道。
Seedance 2.0发布,小红书上神龙见首不见尾了好几天了。好几天之前大家就开始在那发布说Seedance 2.0实在好厉害。字节的产品我也习惯了,他们通常都是做灰度发布的,就是有些人可以先用到,有些人后用到。昨天我也用上了,2月8号应该是付费用户全量开放了。今天是不是给免费用户开放了,我不确定。今天X平台直接被刷屏了,大家都在疯狂地用Seedance 2.0做各种各样的视频。这绝对是一个现象级的产品和技术,能够在X上刷屏刷几天的这种,就属于叫现象级了。

那你说这算不算是一个真正的革命性的技术、真正的这种颠覆式创新掀桌子的技术?目前为止看,还稍微有一点点差距。如果能够把英伟达股价干崩,或者是把整个行业股价干崩,那就属于叫颠覆式创新了。比如说去年春节的DeepSeek,比如说Anthropic的Cowork,一个把英伟达股价干崩了,一个是把整个SaaS股股价干崩了。如果哪天大家突然发现Adobe,还有像很多视频编辑、影视设备、影视软件的公司股价崩了,那么Seedance 2.0可能就属于是颠覆式创新了。让子弹再飞一会。
咱们今天这故事分几段来讲:

其实从OpenAI预告Sora的时候,大家就都惦记做视频了。大家兴奋了一个礼拜、两个礼拜吧,这事又过去了。原因是什么?有几个痛苦的问题一直纠缠着大家:
而Seedance 2.0基本上就把这些问题都解决掉了。业界的技术其实也在不断积累,特别是DiT技术上来以后。DiT是什么?Di应该都是Diffusion,T是Transformer,它等于是Diffusion Transformer。原来大家都是用Diffusion技术,就是扩散技术,一个像素一个像素去猜;Diffusion Transformer它里头是进行这种推理的,也进行这种上下文的记忆。它把视频拆成一小块一小块的,进行这种逐块的生成,这样的话里头这个推理模型它是知道说这个是个人,这个人应该是长成什么样,他在整个这过程中他是有记忆的。所以上了DiT以后,稳定性的问题基本上是可以得到解决和控制的。
从Sora 2开始搞多镜头和音视频同步,大家又看到希望了。你不是控制不好吗?咱干脆不要一个镜头从头到尾整十几秒了,每个镜头有个三五秒,然后咱们把它拼起来,这样我们控制的就更好一点点。Sora 2就干了这么个事情。而且Sora 2有一个很重要的突破,就是音视频同步,它同时生成视频和音频,而且两边是可以配合在一起的。后面Seedance 1.5、阿里的通义万象(也叫万2.5)、谷歌的VEO 3.1,基本上都可以做到音视频同步了。但是更复杂的控制还是很麻烦的。

在这个时候Seedance 2.0就来了,说我把最后一块短板也给大家补上。它怎么来解决这个问题?它一次可以允许大家输入12个元素。这12个元素里头可以是9张图片、3个视频或者是3条音频,你就加起来总数12个以内。当然了,12这个数是来自于文档,我自己在即梦网页上看到的是最多可以输入5张图片,更多的是不是可以,我现在没有去测试。
然后就是写提示词了。你想你输入了这么多图片、音频、视频进去,那提示词就好写了。你可以写@代表各种元素,比如说参考@第一张图里边的人物,参考@第二张图里边的场景,参考@第三张图里边的某一个物品,或者是里头的哪张图是首帧、哪张图是尾帧、哪一张图是中间帧,你可以在里边直接写这样的提示词了。
然后可以参考视频。你上传一个视频,说我要参考这个视频的运镜,比如说是旋绕环绕运镜,或者是前进运镜、后退运镜,这个你可以直接写;还可以参考视频里边的场景,或者参考里边的动作。我做了几个跳舞的,就是把现在比较流行的什么海豹舞或者什么弄出来,然后说来老范跳一个,还是很开心的。音频上去了以后,你可以语音参考,说这个是老范在讲东西,要参考老范的语音。还可以干嘛?做音乐节奏卡点。很多的视频是根据音乐的节奏的那个点要去发生变化的,你可以上传一个音频去做。但是这里要注意,音频跟视频最长只能上传15秒的,再长了他就不让你传了。
然后就是写提示词,一次可以写几千字的提示词进去,最长的是可以生成1080P的、15秒的视频出来。这就是这一次的Seedance 2.0,它真正给我们提供的绝对的掌控力。

提示词进去以后,就是耐心的等待,这个还是挺慢的。我生成一条15秒的视频,我觉得等了几分钟吧。坐在这等是没必要的,可以站起来上别地方去晃荡晃荡去。等待之后TOKEN在燃烧嘛,我的一条15秒的1080P视频,大概花了我10块钱,9块多钱吧。这数是怎么算出来的?因为我是付费用户,基本上一个月是五十几块钱,每个月给1080点。即梦里它是按点算的,生成一条视频是190多点,大概是这样的一个钱数。如果我把这个1080点用完了,再去买大概是5块多钱100点,是这样的一个价格。所以基本上算下来的,这个15秒就是9块多。如果你说我什么也不参考,那他这个便宜点,大概4块多是15秒。当然我买的是最低的套餐,你买的套餐越高,他这个15秒的价格就越便宜。好像是买几千块钱一个月的这种,他们再去买100点的话,大概就是两块多钱了。
但是我原来基本上用不完这些点数,为什么?因为即梦的生成图片是不要钱的,他现在叫限时免费,就是2k的图片生成都是免费的。视频我又做的不多,而且他每天还送点数,每天大概是送80点还是100点吧,他是随机的给你送,只要你每天登录,他就每天给你送。所以那个点数越凑越多,根本使不完。现在终于可以把这些点数都用掉了。我每个月的点数大概够我做5条到6条视频的,再领一点的话,大概能够做个七八条。目前为止,你想靠Seedance 2.0去挣钱,你还要想一想。因为一条10块钱,你要想这一条把这10块钱挣出来,还是挺难的。比如说我送到YouTube Shorts里头去,这一条视频比如播个1000次,也就是能够挣到可能20美分、30美分这样的水平吧,不会再多了。20美分的话也就是一块多人民币,我花十块钱把它做出来,挣了一块多钱,这个还是不划算的。

这个还是要跟大家讲清楚的。目前还没有开放API,只能在网页端使用。APP还没有灰度到我这里,我现在APP上还不让使用2.0。其实APP里头有一个接口可以用,但是让它直接生成视频只到1.5的版本。
在这里头要讲清楚,Seedance 2.0不是开源模型,这个跟国内主流不一样。字节跳动自己家的模型都是不开源的,甭管是豆包模型还是Seedance模型都是不开源的。这些模型都是跑在字节跳动的服务器上的,字节跳动会进行审核的。因为他后边经营抖音、经营TikTok,所以你也不用担心他审核不过来,人家是有极强的视频审核能力的。所以千万不要去试探各种的边缘,色情、血腥、暴力、政治不正确的,就别上去尝试了。我自己曾经试过写标题“雷军如何如何了”,等再输出出来的时候,就变成“某知名企业家如何如何了”。所以它在里头还是有一些限制的。
但是对于版权IP、个人形象,基本上是不管的。你说我要求米老鼠干一个什么事、要求绝地武士干一个什么事,或者是塞尔达公主干点什么事,直接就出。你说我模仿宫崎骏,没毛病,他都是百无禁忌的。你上传头像说这就是我、这是谁谁谁,他也是直接干。所以比国外的一些模型各有优缺点吧。你比如说你到了OpenAI的模型上说我现在想模仿迪士尼的风格,它就不出了;你到了谷歌的这个模型上,你说我现在想画个纳粹,他也不出了。当然这两个换过来是可以的,你到谷歌的模型上画迪士尼可以,你上OpenAI的这个模型上画纳粹也是没毛病的。那这些东西跑到这个Seedance 2.0上,至少是对于迪士尼或者是各种形象,他是不管你的。

这个视频就不在这里展示了,原因也很简单,因为音乐没有版权,放在这的话我这条视频就挂掉了。我在里头做了一个海豹舞这样的一个视频。这个视频我是发到Twitter上了,就发到X平台了,YouTube Shorts我就没发,就是他这个音乐我搞不定。

我就把这个视频上传到X平台了,大家也可以去玩耍起来。

大家注意,即梦是有云端的API的,只是目前为止Seedance 2.0还没上去。还有一个入口,就是它的iOS/安卓端的移动APP。移动APP更新的时候,上面写的是什么?就是“我们马上要出图形模型4.6和5.0了”。大家注意,现在图像模型是升到4.5了,就即梦的图像模型4.5;而这个视频模型升到2.0了,只是我打开APP以后,还没有看到这个模型。它写的是我们这个APP为新模型做好了准备,现在还不让用,因为等灰度呗。灰度发布,本周应该会全量更新出来。
真正的变化,其实不是说有新的模型出来了,真正的变化是什么?即梦APP现在长得跟Sora 2一模一样了。这个是怎么回事?Sora 2其实尝试在玩社交,虽然没有玩起来吧,但是这个尝试大家还是看到了。上来说我们把自己的人头贡献出来,可以让自己跟其他人一起去做互动,或者自己可以做各种各样的动作,直接用个人虚拟角色录制视频。甚至大家可以相互加好友,加了好友以后你就可以用别人的形象,或者大家在同一个视频里出现,就可以来做这样的事情了。
现在即梦APP更新了以后也变成这样了。你也可以说把个人的形象放上去,他上来说123456789,就是你要念一串数字,把你声音录下来,然后抬头晃晃脑袋一下,再把人脸录下来。当然录的时候,它要比Sora 2好一点点是什么?它允许你开美颜,把自己美美的样子录下来以后,你就有个人形象了。然后你就可以@自己去做各种各样的事情。如果有其他人授权你使用形象,或者说你们相互关注了可以使用形象的,那就大家可以凑一桌打麻将什么的都是OK的。这个视频就都可以做了。这个应该也是用Seedance 2.0的模型做出来的。
但是要注意一点什么?在这里头用个人形象去做视频是免费的,还是比较棒的。做出来的内容可以直接分享到抖音,国外的话应该可以是分享到TikTok。我们抖音上、在TikTok上有的是用户,所以在这一点上,没准字节跳动搞的这套东西就能够走通,因为毕竟后头是有底子的。玩短视频这件事情,字节跳动现在应该是全世界的老大,没有第二名了。

最后咱们讲一下Seedance 2.0以及刚才咱们讲的即梦的APP,为什么会在这样的一个时间点来更新?原因很简单,马上要过年了,央视春晚的合作伙伴就是字节跳动。春节联欢晚会,大家举家团圆一起过年的时候,会产生大量的照片和视频。这些照片和视频如何进行传播?或者如何在传播的过程中能够带来更多的互动?这就是字节跳动需要去思考的问题了。我相信Seedance 2.0和即梦最新的APP,一定会让咱们在春节期间发布图片、发布视频更加的开心,更好的互动,给大家拜年助兴带来更大的帮助。
我去下载了一些动画电影,因为动画电影里边的一些动作是比较有趣的,比如功夫熊猫什么的。我可能过几天再去整几个功夫熊猫相关的这种影片出来给大家瞅瞅,准备拿这些动画电影里的这个动作复刻到自己的视频里头去,看看春节谁在拜年视频里头玩出花来,咱们拭目以待了。
赶紧去玩耍起来。在国内的话下载即梦,或者到即梦的APP上去,用手机的抖音就可以直接登录了,或者是手机号也是可以直接登录的。海外的话应该叫Dreamia,都是可以使用的。希望Seedance 2.0可以给大家带来快乐。好,这个故事就讲到这里,感谢大家收听。请帮忙点赞、点小铃铛,参加DISCORD讨论群,也欢迎有兴趣有能力的朋友加入我们的付费频道。再见。
Prompt:Abandoned film production studio interior, scattered cinema camera rigs and lenses, boom mics, audio recorders and cables messy on the floor, editing decks, splicers and tools, VHS tapes piled in the corner, a single computer workstation at the center running a video generation model UI with the title “Seedance 2.0”, floor-to-ceiling window reveals a seaside horizon at dusk with blazing sunset afterglow, dust motes in the air, cinematic anime background art, high contrast, high saturation, crisp textures, reflective glass, subtle film grain, ultra-detailed environment, wide shot, 24mm, low eye-level, leading lines toward the computer, deep depth of field –ar 16:9 –stylize 220 –chaos 8 –no watermark, logo, signature, gibberish text blocks, bad typography, extra monitors, duplicated objects, deformed equipment, lowres, blurry, overexposed highlights –v 7.0 –p lh4so59





In this part of the Cache Lab, the mission is simple yet devious: optimize matrix transposition for three specific sizes: 32x32, 64x64, and 61x67. Our primary enemy? Cache misses.
A standard transposition swaps rows and columns directly:
1 | void trans(int M, int N, int A[N][M], int B[M][N]) |
While correct, this approach is a cache-miss nightmare because it ignores how data is actually stored in memory.
To optimize effectively, we first have to understand our hardware constraints. The lab specifies a directly mapped cache with the following parameters:
| Parameter | Value |
|---|---|
| Sets (S) | 32 |
| Block Size (B) | 32 bytes |
| Associativity (E) | 1 (Direct-mapped) |
| Integer Size | 4 bytes |
| Capacity per line | 8 integers |
We will use Matrix Tiling and Loop Unrolling to optimize the codes.
In this case, a row of the matrix needs 32/8 = 4 sets of cache to store. And cache conflicts occur every 32/4 = 8 rows. This makes 8x8 tiling the sweet spot.
By processing the matrix in blocks, we ensure that once a line of A is loaded, we use all 8 integers before it gets evicted. We also use loop unrolling with 8 local variables to minimize the overhead of accessing B.
1 | int i,j,k; |
Since 61 and 67 are not powers of two, the conflict misses don’t occur in a regular pattern like they do in the square matrices. This “irregularity” is actually a blessing. We can get away with simple tiling. A 16x16 block size typically yields enough performance to pass the miss-count threshold.
1 | int BLOCK_SIZE = 16; |
This is the hardest part. In a 64x64 matrix, a row needs 8 sets, but conflict misses occur every rows. If we use 8x8 tiling, the bottom half of the block will evict the top half.
We can try a 4x4 matrix tiling first.
1 | int BLOCK_SIZE = 4; |
But this isn’t enough to pass the miss-count threshold.
We try a 8x8 matrix tiling. We solve this by partitioning the block into four sub-blocks and using the upper-right corner of B as a “buffer” to store data temporarily.
Here are the steps:
1 | int i, j, k; |
Note: The key trick here is traversing B by columns where possible (so B stays right in the cache) and utilizing local registers (temporary variables) to bridge the gap between conflicting cache lines.
Optimizing matrix transposition is less about the math and more about mechanical sympathy—understanding the underlying hardware to write code that plays nice with the CPU’s cache.
The jump from the naive version to these optimized versions isn’t just a marginal gain; it’s often a 10x reduction in cache misses. It serves as a stark reminder that in systems programming, how you access your data is just as important as the algorithm itself.
For the CSAPP Cache Lab, the students are asked to write a small C program (200~300 lines) that simulates a cache memory.
The full code is here on GitHub.
A cache can be described with the following four parameters:
When the CPU wants to access a 64-bit address, the cache doesn’t look at the whole number at once. It slices the address into three distinct fields:
| Field | Purpose |
|---|---|
| Tag | Used to uniquely identify the memory block within a specific set. t = m - b - s |
| Set Index | Determines which set the address maps to. |
| Block Offset | Identifies the specific byte within the cache line. |
When our simulator receives an address (e.g., from an L or S operation in the trace file), it follows these steps:
cache structure.valid == true AND the tag matches the address tag.valid == false), fill it with the new tag and set valid = true.For this Lab Project, we will write a cache simulator that takes a valgrind memory trace as an input.
The input looks like:
1 | I 0400d7d4,8 |
Each line denotes one or two memory accesses. The format of each line is
1 | [space]operation address,size |
The operation field denotes the type of memory access:
Mind you: There is never a space before each “I”. There is always a space before each “M”, “L”, and “S”.
The address field specifies a 64-bit hexadecimal memory address. The size field specifies the number of bytes accessed by the operation.
Our program should take the following command line arguments:
Usage: ./csim-ref [-hv] -s <s> -E <E> -b <b> -t <tracefile>
-h: Optional help flag that prints usage info-v: Optional verbose flag that displays trace info-s <s>: Number of set index bits (S = 2s is the number of sets)-E <E>: Associativity (number of lines per set)-b <b>: Number of block bits (B = 2b is the block size)-t <tracefile>: Name of the valgrind trace to replayFor this lab, we ignore all Is (the instruction cache accesses).
We assume that memory accesses are aligned properly, such that a single memory access never crosses block boundaries.
We basically start from scratch, given an almost blank csim.c file to fill in. The file comes with only a main function and no header files.
1 | // Data Model |
First, we add the int argc, char** argv parameters to the main function. argc stands for argument count, while argv stands for argument values.
We use getopt to parse arguments.
1 | void handleArgs(int argc, char** argv){ |
getopt comes in unistd.h, but the compiler option is set to -std=c99, which hides all POSIX extensions. GNU systems provide a standalone <getopt.h> header. So we include getopt.h instead.
1 | opt = getopt(argc, argv, "hvs:E:b:t:") |
h and v: These are boolean flags.s:, E:, b:, and t:: These are required arguments. The colon tells getopt that these flags must be followed by a value (e.g., -s 4).After parsing the arguments, we set the initial value of our Cache Data Model.
1 | sets = 1LL << set_bit; |
1 | // Cache Line Structure |
Caution: malloc has to be initialized. Or the data might contain garbage values.
So we use calloc. The calloc (stands for contiguous allocation) function is similar to malloc but it initializes the allocated memory to zero.
And don’t forget to free the allocated memory!
1 | void freeCache() { |
1 | // Handle trace file |
Caution:
fscanf does not skip spaces before %c, so we add a space before %c in the format string.!feof(traceFile) does not work correctly here.It only returns true after a read operation has already attempted to go past the end of the file and failed. Using it as a loop condition (e.g., while (!feof(p))) causes an “off-by-one” error, where the loop executes one extra time with garbage data from the last successful read.1 | // Parse Line Structure |
We use bit masks to parse the addresses.
1 | void loadData(long long address, int size) { |
The code simulates the process of loading cache.
We first check if the data already exists in the cache.
If it doesn’t exist, we have to scan for blank lines to load the data.
If blank lines don’t exist, we need to evict a line using the LRU strategy. We replace the victim line with the new line.
1 | void storeData(long long address, int size) { |
For this simulator, storing data and modifying data are basically the same thing as loading data.
We are asked to output the answer using the printSummary function.
1 | // Print Summary |
And Voila!
1 | Your simulator Reference simulator |
In this project, we moved from the theory of hierarchy to the practical reality of memory management. By building this simulator, we reinforced several core concepts of computer systems.
With our simulator passing all the trace tests, we’ve effectively mirrored how a CPU “thinks” about memory. The next step is applying these insights to optimize actual code, ensuring our algorithms play nicely with the hardware we’ve just simulated.

本文永久链接 – https://tonybai.com/2026/mm/dd/clawdbot-author-peter-steinberger-full-interview
大家好,我是Tony Bai。
在硅谷,每天都有无数个 AI 项目诞生,它们大多有着精美的 Landing Page,有着宏大的融资计划,PPT 里写满了“颠覆行业”。
但最近,一个名为 Clawdbot(现已因商标原因更名为 Moltbot)的项目,却以一种完全不同的姿态闯入了大众视野。没有融资,没有团队,甚至没有商业计划书。它仅仅是一个“退休(财务自由)”的软件大佬,为了给自己“找乐子”而写的一堆代码。
然而,就是这样一个项目,在 GitHub 上一夜之间狂揽 3.2w+ Star,甚至让很多非技术圈的人都跑去 Apple Store 抢购 Mac Mini 来运行它。
它的作者是 Peter Steinberger,著名的 PDF SDK 提供商 PSPDFKit 的创始人。在卖掉公司退休四年后,他因为 AI 找回了当年的热血。
在最近的一次深度访谈中,Peter 毫无保留地分享了他开发 Moltbot 的全过程。这不仅是一个关于工具的故事,更是一份关于“在 AI 时代,个人开发者如何打破大厂垄断,重塑人机交互”的珍贵启示录。

故事的开始并不美好。
四年前,Peter 卖掉了自己经营了 13 年的公司。长期的创业压力让他彻底 Burnout(职业倦怠)。
“那感觉就像有人把我的 Mojo(魔力/精力)吸干了一样。” 他回忆道。在那之后的三年里,他对编程完全提不起兴趣,哪怕只是坐在电脑前都觉得是一种折磨。
直到 2025 年 4 月,一切改变了。
Peter 开始接触早期的 AI 工具,特别是 Claude Code 的 Beta 版。那一刻,他感到了久违的兴奋。
“如果你错过了前几年 AI 比较‘智障’的阶段,直接上手现在的工具,你会觉得——这简直太棒了(Pretty Awesome)!”
这种兴奋迅速转化为了一种“成瘾(Addiction)”。
但这是一种积极的成瘾。他开始熬夜写代码,甚至会在凌晨 4 点给朋友发消息讨论 AI 的新发现。为了给自己找点乐子,他甚至搞了一些极其荒谬的实验:
比如,他做了一个“全球最贵的闹钟”。
他让运行在伦敦服务器上的 AI Agent,通过 SSH 远程登录到他家里的 MacBook,然后自动调大音量来叫醒他。
“这听起来很疯狂,甚至有点杀鸡用牛刀,但这就是我的初衷——Have Fun(玩得开心)。”
Peter 认为,学习新技术的最好方式,就是把它当成玩具。当你不再为了 KPI 或融资而写代码,而是为了让 AI 帮你订一份外卖、回一条消息而折腾时,创造力才会真正涌现。
Moltbot 之所以能打败众多商业化的 AI 助理,核心在于 Peter 对软件架构有着极其深刻的第一性原理认知:
“Don’t build for humans, build for models.”(别为人构建,为模型构建。)
如果你仔细观察现在的软件世界,你会发现所有的 GUI(图形界面)、按钮、下拉菜单,本质上都是为了适应人类极其有限的带宽(Bandwidth)和注意力而设计的。我们需要视觉引导,因为我们记不住命令。
但 AI 不需要这些。
AI 读得懂 Unix 手册,AI 记得住所有参数。
因此,Moltbot 采用了极其激进的 CLI-First(命令行优先) 策略。
Peter 解释道:“你知道什么东西最能 Scale(扩展)吗?是 CLI。你可以写 1000 个小工具,只要它们都有 –help 文档,Agent 就能瞬间学会如何使用它们。”
在 Moltbot 的架构里,所有的能力都被封装成了原子化的 CLI 工具:
Agent 就像一个万能的系统管理员,它通过组合这些 CLI,获得了在数字世界和物理世界中“行动”的能力。这比那些试图用鼠标点击模拟人类操作的 RPA(自动化流程)要高效、稳定一万倍。
Moltbot 最让极客们热血沸腾的,是它对 Big Tech Walled Gardens(大厂围墙花园) 的宣战。
现在的互联网巨头,都希望把你锁在他们的 App 里。WhatsApp 不开放 API,Spotify 不让你导出数据,外卖软件不让你自动化下单。
但在 Peter 看来,AI 是打破这些围墙的终极武器。
以 WhatsApp 为例。官方没有给个人开发者提供 API,如果你用商业 API 发太多消息,还会被封号。
Peter 的做法是:Hack Everything。
他直接通过 Hack 桌面端协议,让 Moltbot 能够接管他的 WhatsApp。当他在旅途中收到朋友的语音消息(比如推荐餐厅)时,Moltbot 会自动:
这一切都在后台静默发生。当 Peter 打开地图时,餐厅已经在那了。
“App 终将消亡(Melt away)。” Peter 在访谈中抛出了这个震聋发聩的观点。
“为什么我还需要一个专门的 Fitness Pal 来记录卡路里?我只需要拍一张汉堡的照片发给我的 Agent。它知道我在麦当劳,它知道汉堡的热量,它会自动更新我的健康数据库,并建议我晚上多跑 2 公里。”
在 Agentic Commerce 时代,用户不再需要在一个个孤立的 App 之间跳来跳去。所有的 App 都将退化为 Agent 可调用的 API(或被 Hack 成 API)。
Moltbot 的另一个标签是 Local-first(本地优先)。
虽然 Peter 自己也用 OpenAI 和 Anthropic 的模型(因为它们目前确实最聪明),但他花了大量精力去适配本地模型(如 MiniMax 2.1)。
为此,他甚至给自己的 Mac Studio 拉满了 512GB 的内存。
为什么要这么折腾?
除了“好玩”,还有一个现实的考量:Red Tape(繁文缛节)。
“如果你是一个公司,你想让 AI 访问你的 Gmail,你需要经过极其漫长的合规审核,甚至需要收购一家有牌照的公司。这太荒谬了。”
但如果你在本地运行 Agent,这一切都不复存在。
没有人能阻止你读取自己的邮件,没有人能禁止你分析自己的聊天记录。
Peter 甚至预言,AI Agent 的普及将直接带动高性能硬件(如 Mac Mini)的销量。“This is the liberation of data.(这是数据的解放。)”
随着 Moltbot 的爆火,无数 VC 挥舞着支票找上门,甚至有大厂想直接收购整个项目(或者招安 Peter)。
对此,Peter 的态度非常潇洒:“I built this for me.(我是为我自己造的。)”
他已经财务自由,不需要再为了融资去写 PPT,不需要为了增长去牺牲用户体验。
“代码本身已经不值钱了(Code is not worth that much anymore)。在这个 AI 时代,你完全可以把我的代码删了,让 AI 几个月再写一个新的。”
真正值钱的,是Idea(想法),是Community(社区),是Brand(品牌)。
他更倾向于将 Moltbot 运作成为一个非营利基金会(Foundation)。他希望这成为一个属于所有人的、开放的、可 hack 的游乐场,而不是某个大厂封闭生态的一部分。
在访谈的最后,Peter 对所有开发者发出了呼吁:
“Don’t just watch. Build your own agentic loop.”
(别只是看,去构建你自己的智能体闭环。)
Moltbot 只是一个开始。它证明了,一个拥有长期记忆(Memory)、工具使用能力(Tools)和自主性(Autonomy)的个人 Agent,能爆发多么惊人的能量。
在这个时代,限制你的不再是技术门槛,而是你的想象力。
去写几个 CLI,去 Hack 几个 API,去给你的 AI 装上“手脚”和“记忆”。
未来,属于那些敢于用 AI 重塑生活的人!
资料链接:https://www.youtube.com/watch?v=qyjTpzIAEkA
你的“好玩”项目
Peter 的故事告诉我们,技术最原本的动力是乐趣。如果给你无限的时间和算力,你最想用 AI 为自己做一个什么“好玩”的工具?是全自动点餐助
手,还是你的专属游戏陪练?
欢迎在评论区分享你的脑洞!别管它有没有商业价值,有趣就够了。
如果这篇文章点燃了你久违的代码热血,别忘了点个【赞】和【在看】,并转发给你的极客朋友,一起搞点事情!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

大家好,欢迎收听老范讲故事的YouTube频道。
千问APP现在全面打通了。1月15号在杭州阿里总部开了发布会,发布会的主题叫“有问必达”。不是答题的答,是到达的达。有问必达,开启办事时代。意思是什么?就是原来咱们只能聊天,现在你要什么,我给你送来什么。
阿里巴巴集团副总裁、千问C端事业群总裁吴佳做的现场发布,号称是全面打通。把淘宝、淘宝闪购(也就是原来的饿了么)、飞猪旅行(我们可以在上面订机加酒,就是机票加酒店)、还有高德地图(你可以在上面去叫出租车或者是做各种的服务,包括一些高德上面的数据,说哪有饭馆什么他都给你搞定)。还可以接通支付宝,以及支付宝的AI付。

现场也演示了一下,吴佳现场指令说:“帮我点40杯霸王茶姬的伯牙绝弦。”千问APP秒级完成淘宝闪购下单,并且通过AI支付,不到20分钟骑手送达现场。这个还是很棒的。
我不知道现场有多少人,反正他点了40杯。那么这里头有一个问题大家就听到了,说为什么支付宝跟支付宝AI付要做两次授权?这个咱们要讲一讲。如果你今天想去试一试,应该怎么办这事?
拿你的手机下载千问APP,然后进去做授权。里头有一个地方做设置,点那个人脑袋——他这藏的还挺深的——点进去了以后,说我现在要授权了。

你要把所有都授权完了,他才可以去干活去。
那支付宝AI付,才是这一次的最核心的发布点。现在大家也不再提支付宝独立这个事,支付宝依然是阿里系的公司,马云回来了以后,这事就不提了。这一次支付宝AI付,就是让AI Agent可以自动的扣款了。原来你是必须要跟他聊,聊完了以后说我确认扣款,他才可以去扣款;一旦是开了AI付了以后,它就可以不用经过你确认,可以免密的自动给你扣了。
这一次支付宝发布了一个叫ACT的东西,叫Agency Commerce Trust Protocol,叫做代理商业信任协议。它是干嘛的?

这个是完整的ACT的四个服务。有了ACT以后,支付宝是可以去做两件事:
既然阿里出了这个ACT的标准,那谁用?谁也不用。除了阿里之外,现在这种支付标准有几套:
第一套就是阿里的ACT,因为只有阿里系内部的在进行对接,实际上对接的也不好。
第二个叫ACP,叫Agent Commerce Protocol(代理商务协议)。阿里是“T”嘛,它是代理商务“信任”协议;这个ACP是代理商务协议。ACP这个协议是谁做的?是OpenAI跟Stripe他们来做的。
还有一个就是咱们前两天讲的,谷歌的UCP(通用商业协议)。谷歌在推,而且还有一大堆的合作伙伴,它这个现在应该是用的最普及的一个吧。而UCP里头,有一个叫APR的一个协议,是专门负责支付的。因为UCP是完整的电商协议,它这个包括东西很多,APR是支付层的可验证授权协议。这一块是现在在上面去签字、去加入生态位的人是最多的。
其实支付宝也加入了这个UCP的协议。当然这只是支付宝国际,国内的咱们就好好玩自己的ACT就完事了。
那么理想的状态会是什么样的?千问开了发布会,他们真正想给大家表达的是什么?
我们聊着聊着直接就点了外卖了、购物了、定了行程了。说我现在想上哪去玩,这个地方有什么样的酒店,酒店都是什么样的价位,哪个哪个酒店的这个房间更好一些。你跟人聊着,聊完了以后,说行了把行程定下来吧。人后边切着咔嚓、切着咔嚓就给你去下单去了。这个就是阿里所希望达到的一个愿景。

而且它还可以自动的匹配各种优惠券。咱买东西你说没有优惠券,这事多没有意思吧?挑优惠券、挑各种活动、挑各种满减,这才有意思。现在在新闻稿里写了,说我们现在千问APP是可以搜索商品和服务的,而且可以进行价格的比较。同样的东西谁家便宜,可以匹配各种的优惠券,国补、店补,还有各种的满减活动,我们都会自动匹配,而且可以自动凑单。因为有的时候是满1000减多少,发现差那么一点点,他会给你推荐一些产品来凑单来。甚至可以标记想要买的东西,有活动或者是降价的时候,它自动的通知你,甚至是可以自动就直接交易掉了。现在这个是阿里的新闻稿里有的。所以甭管你问ChatGPT,还是问Gemini,问任何一个AI大模型,他都告诉你说千问APP是有这些能力的,因为他们都是调用的阿里官方的新闻稿。但是这个玩意真的没有那么好用。
自动消费才是未来真正的方向。设想这样的一个场景吧:家里头总是每天早上起来,一定要吃新鲜的面包(新出炉的面包),还要吃新鲜的牛奶(我们不要搁在冰箱里边的牛奶)。那怎么办?早上起来去买吗?这肯定不行。

你可以设定好,我就从这三家买——不是说一家,从这三家买面包;一定要新鲜出炉的牛奶,也要今天新出品的。设定好这个时间窗口(每周工作日一二三四五我要吃,周六周日我要睡懒觉,你别给我定);设定好金额的上限(每一次多少多少钱,你不能说一把被人坑了,这事也不行);然后设定好商家的范围(你可以多选几家)。每一次这个系统会在里边去挑选合适的商家,完成今天的订单。你设定好了以后,每周的工作日早上起来,交易就自动完成了。然后在你需要吃面包的时候、需要喝牛奶的时候,它就自动的给你送到家门口了。这是一个多么好的生意!以后一定是越来越多的自动交易会被执行。
再设想一下,我们今天做一个比赛吧:City Walk。City Walk完了以后拍视频,看看谁的视频点赞高。点赞高的这个人,我们送他一张机票,或者送他一个蛋糕。我们就直接把交易设置好就完了,剩下大家就不用管了。你们只管去City Walk去拍视频,最后自动去检查结果,这个视频播放量是最高的,然后跟这个账号绑定的,你就直接等着在家里收蛋糕就完事了。所以一旦是自动交易了,想象空间是无限的。我们的整个电商的交易量、交易额都会快速的膨胀和爆炸。
这么好的愿景,那老范在录节目之前总要试一试。那测试的过程非常的悲催。因为我今天也不太想点外卖,说我干脆上淘宝上买个东西吧。我想买什么?去买个保温杯。因为我平时用这个保温杯,是这个宽口保温杯,它比较大,这底下这一部分是很粗的。现在我的小米汽车,它塞不进去。所以我说那我得买一个车载的保温杯。我先是到千问APP里,就说我现在想买一车载的,什么什么样的情况,你给我挑选。实在是找不出合适的来,就给你胡说八道。在这说算了,咱们给他做命题作文吧。
我先打开淘宝的APP,先挑了一个保温杯:TKK车载保温杯,1200毫升陶瓷内胆。我挑好了,我就要这样的保温杯。你给我挑一下,有什么样的款式,什么样的颜色。我说那给我来个绿的吧,看看有什么优惠没有,有什么券没有,都给我用上,找一便宜的。
然后神奇的事情就发生了。他告诉我说京东的便宜,拼多多的可能差一点,但是京东的便宜,咱上京东买去吧。我说你不是跟淘宝打通了吗?你没跟京东打通,我怎么上京东买?他说没事,我告诉你,我先给你一链接,你一点就到京东了,然后在那边去支付就完了。给了我1、2、3的步骤。

我说也行吧,也许它能够给我一个很好的千问APP里头上京东买保温杯的这个体验。啪我一点,点进去了,发现是一个空网页。因为京东的APP是这样,你一旦命令它到达一个商品页的时候,如果这个商品已经没有了,京东会给你一个广告页,告诉你说这些东西咱们来买一买吧。我说你这个失效了,别费劲了。我说你给我找一个能买的页面。他说不行,我跟京东没打通。这个时候他想起跟京东没打通来了,前头给我推荐京东的。
我说那算了,我说贵点贵点吧,你给我推荐淘宝和天猫的吧。我宁肯是买贵一点,因为为了录节目嘛,我总得把这个体验做完嘛。他说那行,我给你整一贵点的,上淘宝天猫里去搜去了。搜完了以后,给我拿出了一个价格来,说这个是145,说你按这个买吧,说这个是天猫旗舰店挺好的。我说也行。因为这个时候我就知道出事了。
什么情况?因为这个淘宝的卖家,他同时会上一大堆的品,比如说这一个保温杯里头有700毫升的、有1200毫升的。他700毫升的是150,1200毫升的是170。但是你在搜索这个商品的时候,他告诉你是150,他一定是标那最低的嘛,我标那高的你肯定不进来了嘛。我告诉他我要买1200毫升的,千问压根就没有分别出来。他说我已经找到了这个1200毫升的,他们家卖150。然后我就等着看他笑话。
我说那那咱买吧,这差20块钱我看谁出。我说那我下单,你给我买去。然后又是这样出了一个链接,说你点这链接,点完了以后就可以自动交易了。我想既然淘宝家的吗,我点完了以后,进去可能不会跳出千问APP,可能在这个里头就走完了吧。也是1、2、3步。第一步是点链接,第二步是确认地址,第三步是支付嘛。我还跟他说,我地址是哪哪你就直接确认就好了。他说也没问题,你你点链接吧。
我啪一点进去,告诉你说这个商品页已经失效。我说京东的你失效了就算了,你淘宝的你也失效。我说告诉他,你这个上面的产品页失效了,你再给我来一次。说这对不起搞错了,七嚓咔嚓给我推荐了三个。他说这三个页都行,有贵的有便宜的。但是无一例外都是用700毫升的价格,告诉我可以买1200毫升的这个杯子的。我说那行咱们挨个点。三个点开了以后全都是错的,全是失效的。我说你都失效了怎么办?他说算了,我给你一个搜索关键词,你自己到淘宝APP里去搜去吧。我说我自己到淘宝APP里搜,我要你干嘛?最后就是裤子都脱了,你就给我看个这个。就是这样的一个情况。所以我也没有买成杯子。大概就是我整个悲催的实验过程。
为什么我讲说这个错误是一个大公司病造成的?

所以他们就把这样半半拉拉的一个功能就做出来了。内部都没有完全打通,更不要说跟外边合作了。就只做到了一个Demo的程度,可能除了点外卖点奶茶之外,其他啥也搞不定,就着急忙慌的出来把发布会给开了。所以这就是大公司干的活。你看我弄完了,这为什么不行?淘宝的事,他们不给我接口。一定是这样的,相互推诿扯皮。你问淘宝说你为什么不给他们接口?他们又不能证明能给我带来收益,我为什么要给他接口?我这忙着,我这还有各种任务排着,轮不上他。大公司就是这么玩的。
那么未来大家会走向何方?淘宝的事咱们就先不管他了。未来在电商里头会有三类的玩家。

当然了还有一些玩家在观望,比如像Anthropic,比如像字节跳动,他们还在观望。他们已经是流量入口了,只要是流量入口,你说我增加功能,然后把这个电商挤压掉,这个都没有任何问题。这就属于轻生意去挤压重生意的一个过程。这个不是那么着急,等着看最后的方向在哪里。
最终的方向,应该是谷歌和OpenAI的开放协议会成为事实标准。亚马逊、美团等缺乏AI能力的巨头,流量会逐渐的被挤压掉,最终会不甘不愿的沦为AI Agent的底层供货商。就是我的交付能力还是很强的,你们去跳转吧,跳转到我这,我把这个生意做完就完了。大家注意电商平台最主要挣的钱不是最后的这个电商服务或者交付这个过程,他挣的钱是广告费。那么以后这个广告费他就挣不着了,他只能挣一个服务费的一个死钱了。所以我说他们沦为基础设施,这个过程是不情不愿的嘛。大量的自动交易会在AI平台上被执行掉,交易量会暴增,经济会腾飞,这是未来的方向。至于阿里嘛,让他们先把内部的大公司病,内部的墙拆一拆再说吧。这个真的是,我满怀欣喜的想去试一试,结果发现来了坨大的。
阿里又开了一次发布会,这一次发布会叫“有问必达”,开启办事时代。做了个连自己体系都没有完全打通的ACT标准。产品概念有了,但是完成度极低。电商和交易一定会在AI的助力下快速发展或者叫快速爆发,但是这里是不是有阿里的机会,还要等等再看。阿里遇到的不是技术问题,也不是依靠技术手段能够解决的问题。很多中国的大厂都是会有类似这样的情况。未来的电商到底向哪块走,我们拭目以待。
好,这个故事今天就讲到这里,感谢大家收听,请帮忙点赞点小铃铛,参加DISCORD讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。


昨晚下班之后,依然跑步回家。今天的天气有些差,路上笼罩着一层雾气,路灯在迷雾中也变得有些朦胧。气温还是徘徊在零度多一点,一阵凉风吹来还是能感受到深深的寒意。
跑步的时候,难免也会想一些乱七八糟的事情,不禁就想到了最近关于 cursor 的各种行为问题。自从某天 cursor 的背景插件更新之后,编辑器在打开文件之后就开始频繁卡顿。正常情况下 cursor 插件都开了自动更新,也就是这次更新,让 cursor 直接到了崩溃的边缘。
让 cursor 解决 ide 卡顿的问题,给推荐一个更加轻量化的插件 backgroud-cover,但是安装的时候是 3.0 版本,提示使用了什么后台服务,balalbalabal。刚开始使用一切顺利,然鹅,这几天更新几次后就又出现了卡顿的问题。
只好回滚到了 3.0 版本,相对来说就稳定可靠多了。所以哦,并不是每次更新带来的都是优化,也可能是退化。
退化的可能不仅仅是这些东西,ai 虽然也在不断的迭代,整体来说能力越来越强,但是针对特殊问题的解决能力却鲜有进步。集成百度 asr 语音识别之后,出现一个诡异的 bug,那就是在 安卓手机上正常,但是在 ios 系统上出错了。让 cursor 解决问题,给出的方案就是方法论的那一堆,包括定位错误,调整配置等等。当然,cursor 也不是一无是处,对于权限的处理还是有价值的:
"NSMicrophoneUsageDescription" : "To use the AI voice assistant's speech recognition feature", "NSSpeechRecognitionUsageDescription" : "To use the AI voice assistant's speech recognition feature",
然而,对于具体的错误处理:
{
"code": 2225220,
"message": "Error Domain=33 Code=2225220 \"asr authentication failed[info:-3004] [(-3004)] \" UserInfo={NSLocalizedDescription=asr authentication failed[info:-3004] [(-3004)] , NSHelpAnchor=7697EC65-0C8F-4640-8993-699C90797ACC},https://ask.dcloud.net.cn/article/282"
}
cursor 给出的建议:

说的的确是问题,但是实际上并不是问题的根本。哪怕去百度的后台看也是一切正常的,

包括 ios 的包名也设置了,网上搜索,能看到的唯一的一篇相关的文章是官方论坛的:https://ask.dcloud.net.cn/question/182917
里面提到了注入权限,直接修改源文件,重新打包,申请资源包等等。然而,在我这里问题的关键在于开通按量付费里面的短语音识别、实时语音识别。
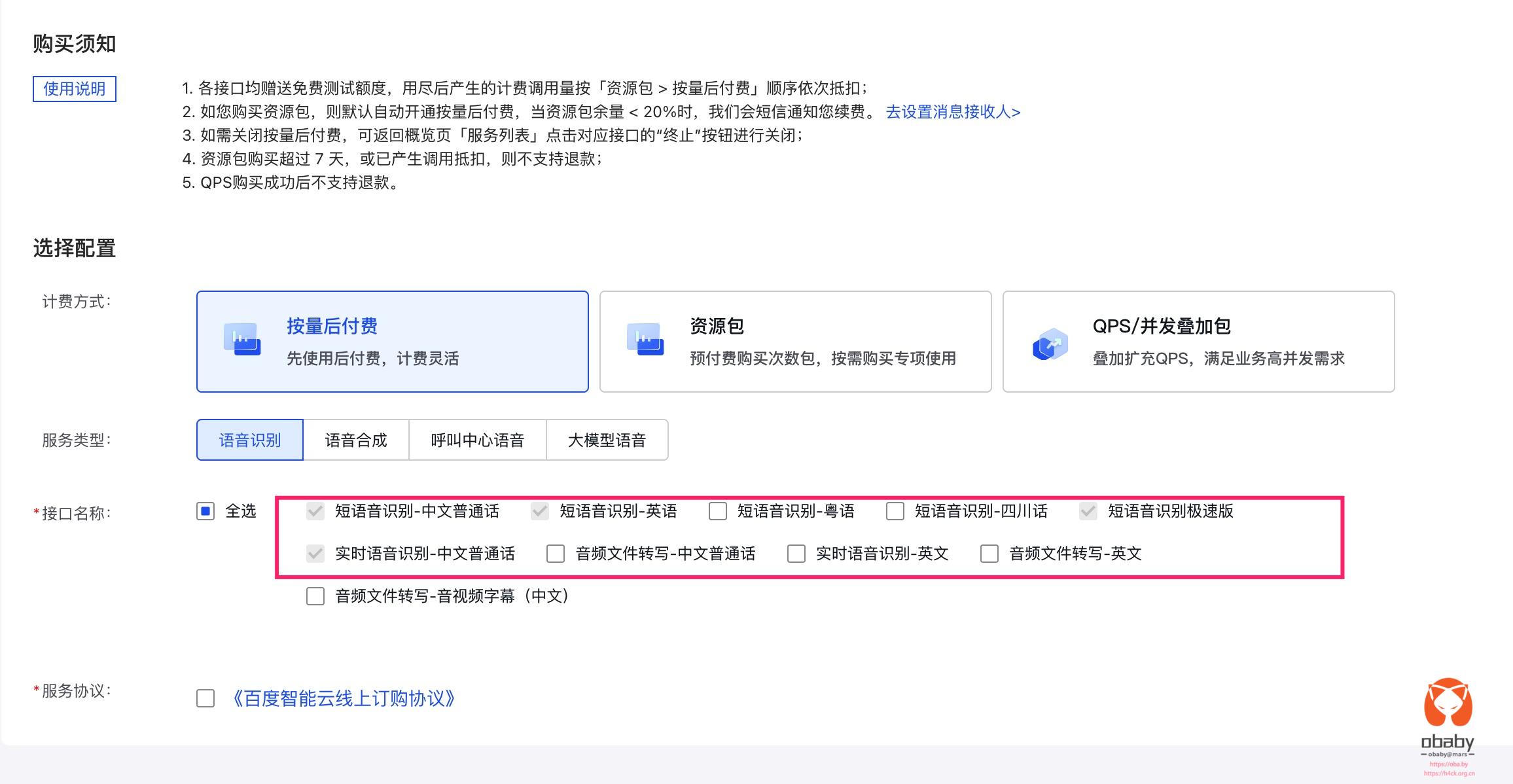
虽然提示的是asr authentication failed,然而,在通过 cursor 一通折腾没有任何的效果之后。我就开始怀疑这个明显不是认证问题,因为目前能做的都做了,并且安卓可以,ios 不行,大概率还是百度平台的设置问题。而至于给出的错误码,这个充其量是个参考,之前对接百度原生的 asr 和 tts 的时候就出现过错误码毫无任何价值的情况。并且,更神奇的是,同样是语音识别,ios 走的是不同的接口,这也挺神奇的。而调用的接口,就是 uni 官方给出的:
var options = {
engine: 'baidu'
};
text.value = '';
console.log('开始语音识别:');
plus.speech.startRecognize(options, function(s){
console.log(s);
text.value += s;
}, function(e){
console.log('语音识别失败:'+JSON.stringify(e));
} );
对于这种问题,目前网上相关的资料少的可怜。可能也有人遇到过,可能解决了再也没人发文章了。
自从有了各种开发助理之后,现在网上的新的技术文章已经肉眼可见的少了。解决问题的文章也少了,不知道是大家都不在遇到问题了,还是真的让 ai 全部给解决了。
现在看到一篇文章,在不确定是真人写的情况下,第一认知,应该判定这个东西是 ai 生成的。现在要判断 ai 生成的内容,成本也越来越高了。
昨天下午博客有段时间卡死了,登录服务器发现 php进程跑满了。看了下实时流量的 ua 竟然有个 gptbot。日志文件分析之后,发现各种 bot 真的不少:
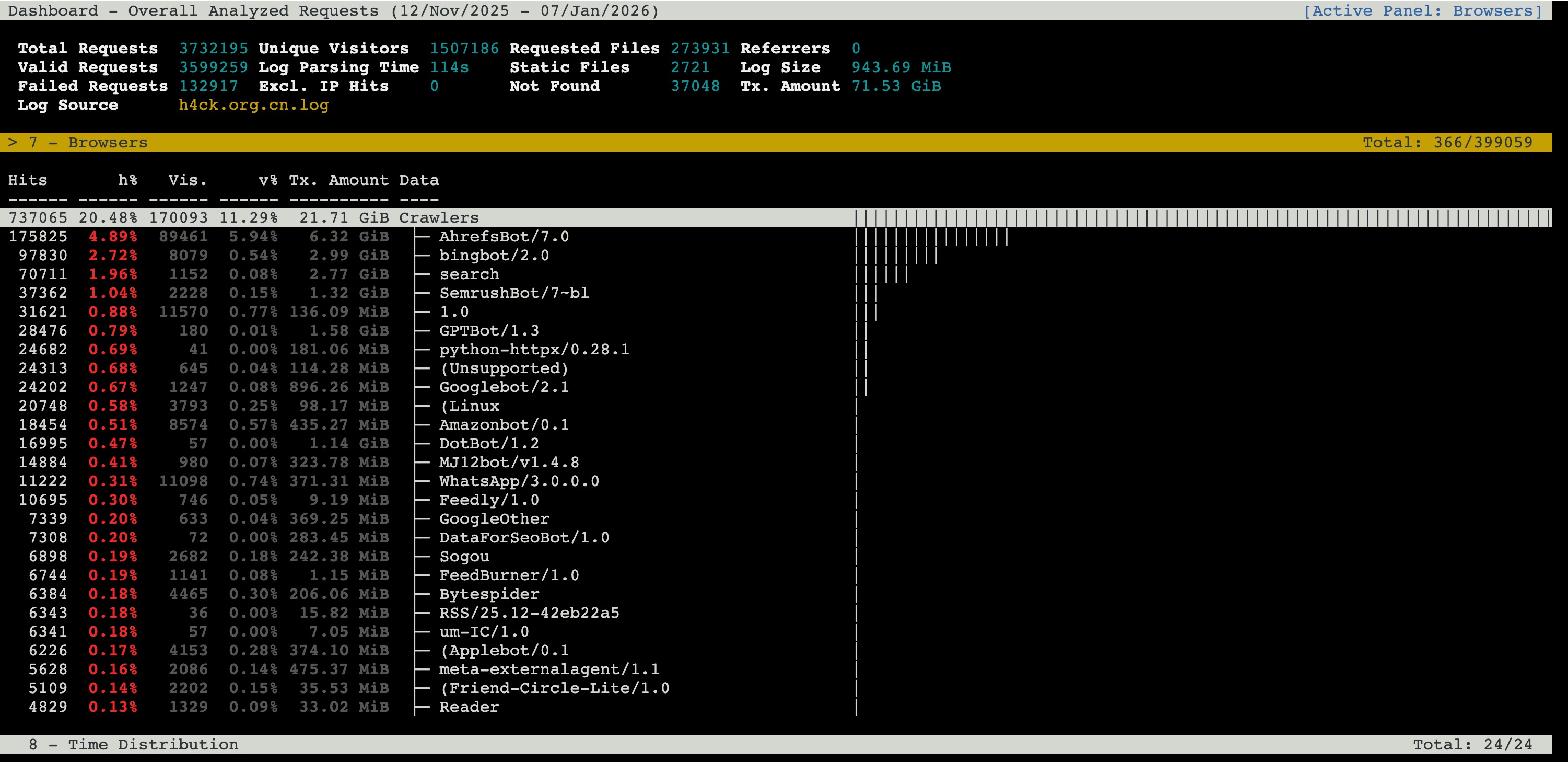
而 umami 统计的流量,也属实有些离谱了:

这种 ai 对于这种真人输出的内容的依赖性从来不低,毕竟 ai 生成的内容反复投喂给 ai,最后 ai 就会变成智障,这个和近亲繁殖有着异曲同工之效。太多的人依赖于 ai,ai 解决问题之后,也很少有人会在写这些问题的解决过程。只要 ai 还需要人类生成的内容进行 feed,那么哪怕是再拙劣的文字也有重大的价值,直到那天 ai 能自己进化,那时候就不需要人类的。
互联网的荒漠化进程依然会继续,珍惜那些愿意打字的博主们吧,他们才是这个时代的宝藏,让 ai 不会快速沦落为智障。