What Zendaya Leaves Unsaid - Her films rarely center on—or even acknowledge—her race, seemingly out of concern that focussing on identity might limit her characters’ emotional palettes. But why couldn’t it expand those palettes? (www.newyorker.com)
vmwgfx 0000:00:04.0: [drm] FIFO at 0x0000000020000000 size is 2048 kiB vmwgfx 0000:00:04.0: [drm] VRAM at 0x0000000010000000 size is 262144 kiB vmwgfx 0000:00:04.0: [drm] *ERROR* Unsupported SVGA ID 0xffffffff on chipset 0x405 vmwgfx: probe of 0000:00:04.0 failed with error -38
blacklist vmwgfx 后用的是 efifb:
[ 0.465898] pci 0000:00:04.0: BAR 1: assigned to efifb [ 1.197638] efifb: probing for efifb [ 1.197705] efifb: framebuffer at 0x10000000, using 7500k, total 7500k [ 1.197708] efifb: mode is 1600x1200x32, linelength=6400, pages=1 [ 1.197711] efifb: scrolling: redraw [ 1.197712] efifb: Truecolor: size=8:8:8:8, shift=24:16:8:0
虚拟机的 IP 地址,从宿主机也可以直接访问,通过 WVMBr 访问,目测是直接 Tap 接出来,然后建了个 Bridge,外加 NAT,只是没有 DHCP。
// vertex shader#version 320 esinvec4vertex;// xy is position, zw is its texture coordinatesoutvec2texCoors;// output texture coordinatesvoidmain(){gl_Position.xy=vertex.xy;gl_Position.z=0.0;// we don't care about depth nowgl_Position.w=1.0;// (x, y, z, w) corresponds to (x/w, y/w, z/w), so we set w = 1.0texCoords=vertex.zw;}// fragment shader#version 320 esprecisionlowpfloat;invec2texCoords;outvec4color;uniformsampler2Dtext;voidmain(){floatalpha=texture(text,texCoords).r;color=vec4(1.0,1.0,1.0,alpha);}
在这里,我们给每个顶点设置四个属性,包在一个 vec4 中:
xy:记录了这个顶点的坐标,x 和 y 范围都是 -1 到 1
zw:记录了这个顶点的 texture 坐标 u 和 v,范围都是 0 到 1
vertex shader 只是简单地把这些信息传递到顶点的坐标和 fragment shader。fragment shader 做的事情是:
// vertex shader#version 320 esinvec4vertex;// xy is position, zw is its texture coordinatesinvec3textColor;outvec2texCoors;// output texture coordinatesoutvec3fragTextColor;// send to fragment shadervoidmain(){gl_Position.xy=vertex.xy;gl_Position.z=0.0;// we don't care about depth nowgl_Position.w=1.0;// (x, y, z, w) corresponds to (x/w, y/w, z/w), so we set w = 1.0texCoords=vertex.zw;fragTextColor=textColor;}// fragment shader#version 320 esprecisionlowpfloat;invec2texCoords;invec3fragTextColor;outvec4color;uniformsampler2Dtext;voidmain(){floatalpha=texture(text,texCoords).r;color=vec4(fragTextColor,alpha);}
首先,黄教主上来以后,先举着一个大盾牌,把一堆的芯片拼成盾牌那么大,就像美队一样,举着个盾牌就上来了。这个东西是什么呢?叫Grace Blackwell NV link 72。当然了,GBNV link 72呢,长得并不是真的这个样子,他只是说跟大家表演一下这个东西,把芯片铺开了应该是这样。
英伟达的显卡一般叫B开头的呢,就是它的GPU,就是Blackwell框架,黑井框架。说B200、B多少,这就是GPU;G开头的呢,实际上是CPU,叫Grace。这个东西呢,是ARM的CPU。所以呢,这个叫GBNV link 72呢,就是36个Grace CPU,加上72个Blackwell的GPU拼在一起,加上这种高速连接,整个拼一块儿以后,做的一个高性能运算的主机。大家可以在这个上面去训练模型。
5090再往后呢,就发布了一个很奇怪的东西,叫project DigITs。这个东西呢叫做数字项目或者数据工程。我估计黄教主呢也是看旁边苹果整的Mac mini M4出尽了风头,这么小的主机,这么强的算力。很多人把它买回来去做大模型,甚至把几台M4 mini的这个主机拼在一起,还可以跑一些更大的模型出来。黄教主说:“这个我也行的。”这种设备呢,从结构设计上,甭管是谁设计的,但是从生产上来说呢,一定是台湾或者是大陆的这些果链企业去生产的。所以黄教主说:“你们谁去给我整个这玩意出来?”这个应该并没有什么难度。
那你有钱人说我买一个摆家里供起来,没毛病。至于其他的人呢,就真的没必要买这东西了。为什么呢?首先要注意,它里边用的操作系统是一个拿乌班图修改过的定制操作系统,一个用户量不大的操作系统,各种兼容性问题可以把普通用户折腾死。如果你说我不是一个专门的工程师,我就是一个使用 Mac 的用户,或者使用 Windows 的这种桌面用户的话,你就别用这玩意了,这个不是一般人能搞得定的,只有工程师才可以使用这种定制操作系统。
关注苹果 MacBook Air 产品线的同学应该知道,从前两年开始,MacBook Air 已经换上了 retina 显示屏,设计也改头换面了。不过在产品线布局上,MacBook 系列发生了一些变化:12 寸 MacBook 已经退出人们视野(这个产品系列应该已经开始和 iPad Pro 打架了,所以退出也是必然的),MacBook Air 正式接棒了 12 寸 MacBook 的 fanless 无风扇设计。
说是无风扇设计,其实 MacBook Air 还是有风扇的,只不过这个设计相当奇特——后面我们再谈。但有一个核心资讯是 MacBook Air 用户需要在意的:如今的 MacBook Air 全部采用 Intel 超低压酷睿 Y 系列处理器。注意是超低压,而不是低压 U 系列(MacBook Pro 13″ 一直在用低压 U 系列)。也就是说,MacBook Air 已经正式成为 Mac 家族中性能最弱的设备,加上其价格——尤其 2020 款 MacBook Air 起价 7999 元,MacBook Air 成为了 Mac 系列中最低端的一个系列。
这也算是产品布局的一个精准调整了,当年乔布斯从信封里拿出 MacBook Air 之时,这个产品的价格可实在是不菲的,定位绝对不亚于 MacBook Pro。
总之,MacBook Air 现在在用的处理器是一种更省电的方案。TDP 9W 听起来好像的确可以不需要风扇了,人隔壁 iPad Pro 的 A12X 大概 7、8W 的平均功耗就没风扇。当然了,这里咱不说,这个 TDP 本身现在所具备的参考价值可能越来越脱离于其原本热设计功耗的意义,毕竟现在大家都把睿频当基频在看,连什么 cTDP up/down 之类的数据看起来都不靠谱。
来源:iFixit[2]
不过 MacBook Air 从改头换面以来的风扇设计就相当之奇特,上面这张图是 2018 款 MacBook Air 拆开后壳以后的内部结构图。内部左上角位置显然就有风扇,不过你知道 CPU 在哪儿吗?CPU 本尊并不在风扇附近,而在中央那块散热片下面,下图用红框将其标出了。
CPU 上方的散热片
需要注意的是,从各种拆解来看,CPU 之上并没有一根导热管连接至风扇。那么这枚风扇究竟在给谁降温?迷之风扇!针对这个问题,我查了一些资料,发现网上对此的猜测颇多。YouTube 有一些技术向的 up 主提到,这颗孤独的风扇 “just for ventilation”,它负责带走 MacBook Air 内部主板的整体热量,而且在内外造成气压差,这样内部也会主动“吸入”一些冷风。
Reddit 上面也有一张帖子是专门讨论此事的[3]:这张帖子是针对 2019 款的 MacBook Air,表明这种设计后续没有变。这张帖子里有人提到,这种设计可能是依赖于内部的密闭结构,空气流向通路上会带到 CPU 上方的散热片。不过无论如何,这种设计针对 CPU 的散热效率都是比较低的,可能与 MacBook Air 追求极致轻薄有关(但实际上我们后面还会提到,MacBook Air 如今真的不能算薄)。
单就 CPU 而言,这还真的算是 fanless,因为虽然有风扇但却不是针对 CPU 的;所以 CPU 真的仍然可以说是被动散热;或许在超低压处理器范畴内,这种设计是合理的,真的是这样吗?
与 MacBook Pro 的性能差距
网上已经有部分 up 主,包括上周我在参与 WEB VIEW 的播客节目时,都谈到了,今年的 MacBook Air 真的十分超值;主要是因为 SSD 最低容量升级到 256GB,内存也换用了 LPDDR4x,存储性能会有较大提升(虽然 MacBook Air 的 SSD 速度一直以来都比 MacBook Pro 慢一截);另外就是处理器更新到了酷睿十代,除了最低配的酷睿 i3,更高 i5 配置都开始改用四核处理器(所以苹果宣称快 1 倍),核显也明显上了一个台阶。而且,价格更便宜。
就纸面数字来看,我之前甚至还提到,2020 MacBook Air 已经比 2019 MacBook Pro 13″ 更牛了。不过当时我并没有意识到,2020 MacBook Air 用的虽然是四核处理器,但却是超低压版的酷睿 Y 系列。而 MacBook Pro 用的是低压酷睿 U 系列(2019 款 MacBook Pro 13″ 用的八代酷睿低压 U 系列)。那么除了 TDP 功耗数字差异,这两者到底如今是个什么样的关系呢?
2020 与 2019 款 MacBook Air 内部结构对比,来源:Max Tech
另外,Max Tech 的拆解已经提到,2020 MacBook Air 仍在沿用以前的模具(chassis),所以上述这种加了个风扇,但不吹 CPU 的设计仍然存在,如上图所示。
Intel 酷睿 Y 系列四核处理器,没风扇能镇压吗?其实从理论上来说问题也不大,被动散热中的典范是 Surface Pro。之前我花了很大的篇幅来探讨无风扇的 Surface Pro 性能如何,结论是无风扇的 Surface Pro 相比同配其他有风扇的超级本,持续性能差距大约有 25%[4]。即便如此,Surface Pro 的表现依然令人满意,可以认为是被动散热设计中的楷模。而且 Surface Pro 用的还是酷睿 U 系列即低压版的处理器,MacBook Air 用的 Y 系列更不成问题了吧?
市面上貌似还没有可参照对比的十代酷睿 Y 系处理器实际性能,所以我们就只能看 2020 MacBook Air 自己的实际表现了。严肃技术向的科技媒体还没有十分严谨的测试数据——NBC 的数据库里面也还没有这几款 CPU 的成绩,这里我捡一些不够可靠的分数,都是 CineBench R20 测试:
Luke Miani 给 MacBook Air 酷睿 i3 版(Core i3-1000NG4,双核)的测试得分为 640 分,酷睿 i5 版(Core i5-1030NG7,四核)测试得分大约在 1060 分左右 ;但 Max Tech 针对酷睿 i5 版的测试得分一次是 863 分,一次是 1019 分 ——我猜这可能与设备测试前的运行状态有关(真心是不负责任的 up 主啊!),这里的 863 分很有可能是持续性能成绩,而超过 1000 分的成绩则是在设备温度较低时第一第二轮跑分能够获得的成绩。
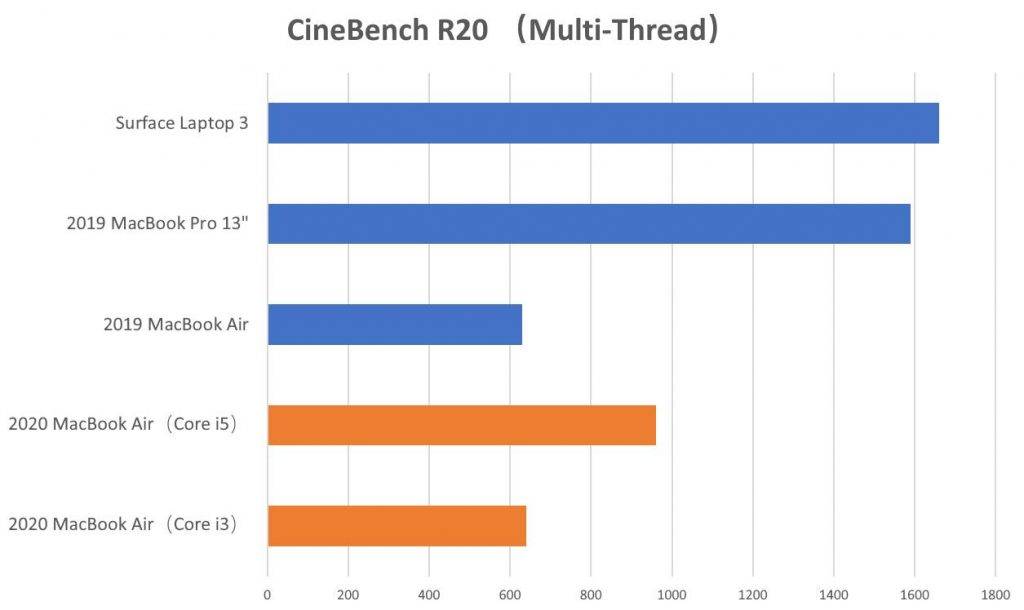
MacBook Air 与 MacBook Pro 13″ 的 CineBench 测试成绩
毕竟不是什么正经测试,那我们就取个中间值吧:960 分——恰好和一家日本测试站点 PC Watch 给的结果差不多 [7]。上一代的酷睿 i5 版(Core i5-8210Y) MacBook Air 的 CineBench R20 得分为 632 分[8]。所以粗略估算,2020 MacBook Air 酷睿 i5 版相比上一代的 CPU 性能提升幅度大约是 52%-60%,也算是很给力的成绩了(知乎上貌似有数据说是提升 200%,不知这个数据是怎么来的;另 Geekbench 5 多核测试成绩有将近 80% 的性能提升)。当然我们暂时还没有机会了解多轮测试的持续性能表现。
不过这个成绩相较酷睿低压版 U 系列处理器还是有着相当大的差距,比如 MacBook Pro 13″。这里放上 2019 款 MacBook Pro 13″(Core i5-8279U,八代酷睿低压处理器)以及我自己测试的 Surface Laptop 3(Core i5-1035G7,十代酷睿低压处理器)成绩对照,如上图。
GPU 核显部分其实也是这次提升的一个亮点,尤其酷睿 i5 版用上了满血的 64 EU(不过考虑到 Y 系列超低压处理器的 TDP 限制,我猜其图形性能应该还是会低于 U 系列的低压版)。不过那些 up 主的数据感觉都偏离很大,而且也不标测试工具版本和测试环境。PC Watch 给的数据是,Unigine Valley Benchmark 1.0 测试中,2020 MacBook Air 相比上一代平均帧率提升将近 1 倍——这也基本符合我们对于这次 Iris Plus 提升的认知。在 Max Tech 的 Geekbench 5 Metal 测试中,2020 MacBook Air 相比上一代得分大约有 1.2 倍的提升。
其实针对 GPU,也很想加入 Surface Laptop 3 对照(就能看看同样是满血版 G7,低压版和超低压版上的 Iris Plus 核显有什么差别了),不过这些媒体完全不说测试对象,比如测试 API 是否用的 OpenGL,高画质、抗锯齿与否等,所以我也没法测(而且我的测试也一向那么那么不严谨O_o)。不过从早前笔吧的十代酷睿核显测试来看,GPU 性能提升的确很多,但实际使用却没有这么给力,原因应该是当 CPU 也一同跑起来的时候,CPU 和 GPU 会开始争抢主内存资源,造成数据带宽瓶颈——这在一些需要较多调度 CPU 的游戏中就能体现出来。
MacBook Something…
这里再多插一句,看到有人对比 Unigine Heaven 测试,2020 MacBook Air 最终平均帧率 8.8 帧,2019 MacBook Pro 13″ 平均帧率 10.9 帧。这个数据仅供参考,或与 eDRAM,以及后者 28W TDP 有关。
如果我们只看 CPU 性能的话,即便和 2019 款 MacBook Pro 13″(中配 Core i5-8279U)比,2020 MacBook Air 都有着比较大的差距,两者 CineBench R20 多核性能差距在 58-65% 左右。而且由于散热设计上的差异,持续性能理论上还会拉开更大的差距。
说白了,新款 MacBook Air 在性能上仍然是弱鸡,只不过的确比上一版提升很多。与竞品比较的话,其性能和 Surface Pro 7 甚至都有较大差距,这两者还都是被动散热(MacBook Air 的“被动”散热打个引号);而价格其实还差不多。
超低压 CPU 的发热很低吗?
在之前我们探讨过低压 CPU 的实质以后,我愈发觉得,其实超低压和低压 CPU 的区别,可能本质上也还是比较小的——只在于给了一个人为限制的 TDP,便有了更小的基频。如果不考虑功耗墙和温度墙,那么这两者大概就仅剩 I/O 的那点差别了(未深入考察,纯个人 YY,别当真)。
从 Max Tech 的发热测试来看,在 2020 MacBook Air(Core i5 版)跑 CineBench R20 的时候,四核全开,短时睿频可蹿升至 2.4-2.7GHz,此时的功率大约为 13W(在 Max Tech 刚刚更新的测试中,据说功率可以一度达到 26W,全核在极短时间内达到更高频率[10]。这还是超低压 CPU 的节奏吗???或者苹果的确对其间限制做了改动);但似乎在极短时间内(具体多久不知道)就撞了温度墙,CPU 核心温度很快蹿升到了 100℃,全核心便降到 1.5GHz 左右。
这个时候如果能有主动散热来努力一把,那么睿频还是可以坚持更长时间的。只不过前面也提到了,MacBook Air 如今的散热设计比较奇特,那个独立的小风扇依靠坚强的毅力来为散热片吹风。
另外,MacBook 轻薄本(主要包括 MacBook Air 和 MacBook Pro 13″)在散热设计上还一直有个传统,即宁可降低频率,也要让风扇保持安静。所以 MacBook 用户应该会发现,风扇是几乎不发出声音的,这大概也算保证体验的一种方案吧。有兴趣的同学可以去看看 Linus Tech Tips 做的一个视频 “Macs are SLOWER than PCs. Here’s why.”[9],里面提到了 MacBook Pro 在 macOS 系统下这种调节机制的特性(不过 Linus Tech 一直是著名果黑)。
似乎苹果更相信,让风扇尽可能保持低转速,而在一定限度内牺牲性能,是一种可达成体验加成的方式(其实我也这么认为…)。实际上 2020 MacBook Air 的情况也很类似,即 CineBench R20 测试期间,所有核心全开,CPU 核心温度到 100℃ 了,风扇转速也才 4000RPM(全速是 8000RPM)——不过由于这风扇离 CPU 这么远,估计就算转更快、效果也就那样了。
而苹果在 Mac 设备散热上的黑历史,也实在是一言难尽;也包括大尺寸的 MacBook Pro 移动工作站。实际上,苹果在寻找散热设计与极致轻薄间的平衡点时,指针始终在向后者偏移。或许在苹果看来,如果你那么在意性能,为什么不买个台式机呢?好像也有点道理。
Intel Core Ice Lake
OEM 厂商的市场定位把戏
看看,MacBook Air 性能和 MacBook Pro 13″ 还是存在实质上的差距的(更不用提屏幕亮度和色域覆盖差别)。所以以更低的价格购买一台 MacBook Air,你并不能获得 MacBook Pro 13″ 那样的硬件水准。而且实际上,追求轻薄性的各位不妨去苹果官网看一看 MacBook Pro 13″ 与 MacBook Air 在重量和厚度上的差别,这两者不仅最厚处是一样厚的,而且 Pro 只比 Air 稍重了一点点(当然 Air 还有楔形设计)…
在市场策略上,以 Intel 酷睿超低压处理器(Y 系列,MacBook Air)与低压处理器(U 系列,MacBook Pro 13″)拉开性能差距,再加上前者散热上的负优化(误),这两条线的产品不会存在性能上打架的情况。另外,如果今年 MacBook Pro 13″(或 14″)开始采用 AMD Ryzen 4000 处理器,则这种差距还能被进一步拉大。于是,MacBook Air 成为名副其实 Mac 系列产品中性能最差的存在,优势就是价格便宜。











































































 Processors Brief
Processors Brief