我原以为最难的是编写代码。结果发现,生产环境才是安全假设的坟墓。

I Thought the Hard Part Was the Code. Turns Out Production Is Where Security Assumptions Go to Die. (dev.to)
我之前給家中的伺服器做了一個 WebDAV 功能,帶有不堪入目的 UI 和難以使用的功能。而且配置起來並不簡單。一直想要改進,但是卻一直沒時間。最近有空了,便開始尋找替代品。
查了幾下 GitHub,找到了一個標星 10k+ 的專案 —— NextCloud。瞭解了一下,NextCloud 是一個擁有 全平臺客戶端,支援 WebDAV,而且 外掛化,可以 多使用者 使用的私有云儲存網盤專案。不僅如此,它還支援共享、版本控制、團隊協作等功能。外掛化讓它擁有了類似 Markdown 線上編輯,Draw-io 線上編輯,顯示 RAW 檔案的功能。
而且,我發現它支援 Docker,這無疑簡化了我們配置的步驟。
那麼,我們開始吧!
Docker 安裝很簡單,為了安裝快速,你可以參考清華大學開源映象站給出的 文件。如果你已經安裝了 Docker, 那麼可以忽略這一步。
更換映象也是讓你更快體驗的必不可少的一步,修改 /etc/docker/daemon.json 檔案
1 | { |
執行如下命令即可:
1 | sudo docker run -d \ |
如果遇到如下問題:
1 | Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? |
可以執行:
1 | systemctl daemon-reload |
配置這一部分很簡單,不用解釋了。
選擇資料庫時,使用量小可以選擇 SQLite,但是並不推薦。
NextCloud 還是非常穩定的,基本配置完之後不會遇到什麼問題。而且原生支援中文,只需要在設定中設定一下就可以了。
我主要用它儲存我的照片,攝影還有一些不需要經常檢視的檔案。由於自己伺服器效能不錯,用起來很流暢,完全沒必要買現成的,硬碟不夠再買一個即可。
在使用 docker 时,常常会碰到进程退出时资源清理的问题,比如保证当前请求处理完成,再退出程序。
当执行 docker stop xxx 时,docker会向主进程(pid=1)发送 SIGTERM 信号
如果在一定时间(默认为10s)内进程没有退出,会进一步发送 SIGKILL 直接杀死程序,该信号既不能被捕捉也不能被忽略。
一般的web框架或者rpc框架都集成了 SIGTERM 信号处理程序, 一般不用担心优雅退出的问题。
但是如果你的容器内有多个程序(称为胖容器,一般不推荐),那么就需要做一些操作保证所有程序优雅退出。
信号是一种进程间通信机制,它给应用程序提供一种异步的软件中断,使应用程序有机会接受其他程序活终端发送的命令(即信号)。
应用程序收到信号后,有三种处理方式:忽略,默认,或捕捉。
常见信号:
| 信号名称 | 信号数 | 描述 | 默认操作 |
|---|---|---|---|
| SIGHUP | 1 | 当用户退出Linux登录时,前台进程组和后台有对终端输出的进程将会收到SIGHUP信号。对于与终端脱离关系的守护进程,这个信号用于通知它重新读取配置文件。 | 终止进程 |
| SIGINT | 2 | 程序终止(interrupt)信号,在用户键入 Ctrl+C 时发出。 | 终止进程 |
| SIGQUIT | 3 | 和SIGINT类似,但由QUIT字符(通常是Ctrl /)来控制。 | 终止进程并dump core |
| SIGFPE | 8 | 在发生致命的算术运算错误时发出。不仅包括浮点运算错误,还包括溢出及除数为0等其它所有的算术错误。 | 终止进程并dump core |
| SIGKILL | 9 | 用来立即结束程序的运行。本信号不能被阻塞,处理和忽略。 | 终止进程 |
| SIGALRM | 14 | 时钟定时信号,计算的是实际的时间或时钟时间。alarm 函数使用该信号。 | 终止进程 |
| SIGTERM | 15 | 通常用来要求程序自己正常退出;kill 命令缺省产生这个信号。 | 终止进程 |
下面以 supervisor 为例,Dockerfile 如下
1 | FROM centos:centos7 |
正常情况,容器退出时supervisor启动的其他程序并不会收到 SIGTERM 信号,导致子程序直接退出了。
这里使用 trap 对程序的异常处理进行包装
1 | trap <siginal handler> <signal 1> <signal 2> ... |
新建一个初始化脚本,init.sh
1 | #!/bin/sh |
修改 ENTRYPOINT 为如下
1 | ENTRYPOINT ["sh", "/root/init.sh"] |
)
为了提升访问速度、增强稳定性并规避部分官方源的不确定性,将常用的开源镜像同步到中国大陆可访问的镜像仓库是一种高效的解决方案。
本文介绍如何通过 GitHub Actions 自动化完成该同步流程,支持选择性构建与定制版本。
许多开源镜像托管在 Docker Hub 上,但由于网络、访问频率限制等问题,拉取速度不稳定,甚至存在连接失败的情况。
之前是使用 GitHub Actions 同步到 CODING 上,不过要 CODING 要停服了,所以改为同步到 CNB 了。
cnb.cool 也是由腾讯出品,基于 Docker 生态,对环境、缓存、插件进行抽象,通过声明式的语法,帮助开发者以更酷的方式构建软件。
支持代码托管、云原生构建和云原生开发等功能。
skopeo 工具将镜像从 Docker Hub 同步到 CNB;
点击查看完整文件内容
前往 GitHub 查看:docker-proxy.yml
name: Mirror Docker Images to CNB
on:
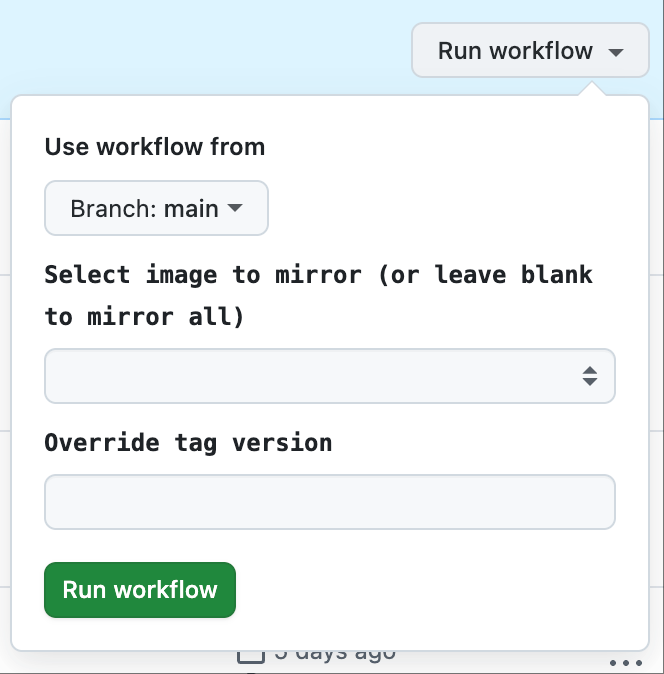
workflow_dispatch:
inputs:
name:
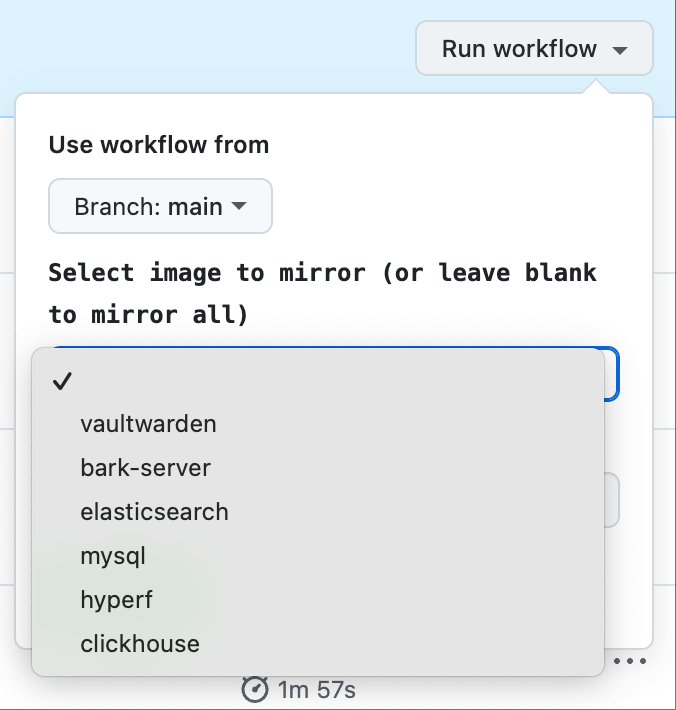
description: 'Select image to mirror (or leave blank to mirror all)'
required: false
type: choice
options:
- ""
- vaultwarden
- bark-server
- elasticsearch
- mysql
- hyperf
- clickhouse
version:
description: 'Override tag version'
required: false
type: string
push:
paths:
- '.github/images.yml'
branches: [ 'main' ]
jobs:
mirror:
name: >-
Mirror ${{ github.event.inputs.name || 'All Images' }}${{ github.event.inputs.version && format(' (version: {0})', github.event.inputs.version) || '' }}
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Mirror images
env:
INPUT_NAME: ${{ github.event.inputs.name }}
INPUT_VERSION: ${{ github.event.inputs.version }}
run: |
images=$(yq -o json '.images' ${{ github.workspace }}/.github/images.yml)
if [ -n "$INPUT_NAME" ]; then
matrix=$(echo "$images" | jq -c --arg name "$INPUT_NAME" '.[] | select(.name == $name)')
else
matrix=$(echo "$images" | jq -c '.[]')
fi
if [ -z "$matrix" ]; then
echo "No matching images found for name: $INPUT_NAME"
exit 1
fi
echo "$matrix" | while read -r item; do
image=$(echo "$item" | jq -r '.image')
name=$(echo "$item" | jq -r '.name')
default_tag=$(echo "$item" | jq -r '.tag')
tag=${INPUT_VERSION:-$default_tag}
echo "Mirroring $image:$tag to docker.cnb.cool/lufei/docker/$name:$tag"
skopeo copy --all docker://docker.io/${image}:${tag} \
docker://docker.cnb.cool/lufei/docker/${name}:${tag} \
--src-creds "${{ secrets.DOCKERHUB_USERNAME }}:${{ secrets.DOCKERHUB_TOKEN }}" \
--dest-creds "cnb:${{ secrets.CNB_DOCKER_TOKEN }}"
echo "::notice title=Image Published::https://docker.cnb.cool/lufei/docker/${name}:${tag}"
doneon:
workflow_dispatch:
inputs:
name: # 可选镜像名
version: # 可选覆盖 tag
push:
paths:
- '.github/images.yml'
branches: [ 'main' ]支持两种触发方式:
.github/images.yml 文件变更时,自动同步全量更新。.github/images.yml:
images:
- image: "vaultwarden/server"
tag: "latest"
name: "vaultwarden"
- image: "finab/bark-server"
tag: "latest"
name: "bark-server"
...skopeo copy --all docker://docker.io/${image}:${tag} \
docker://docker.cnb.cool/lufei/docker/${name}:${tag} \
--src-creds "${{ secrets.DOCKERHUB_USERNAME }}:${{ secrets.DOCKERHUB_TOKEN }}" \
--dest-creds "cnb:${{ secrets.CNB_DOCKER_TOKEN }}"--all:确保同步多平台镜像(如 amd64 和 arm64);在 GitHub → Actions → “Mirror Docker Images to CNB” → 点击 “Run workflow”:
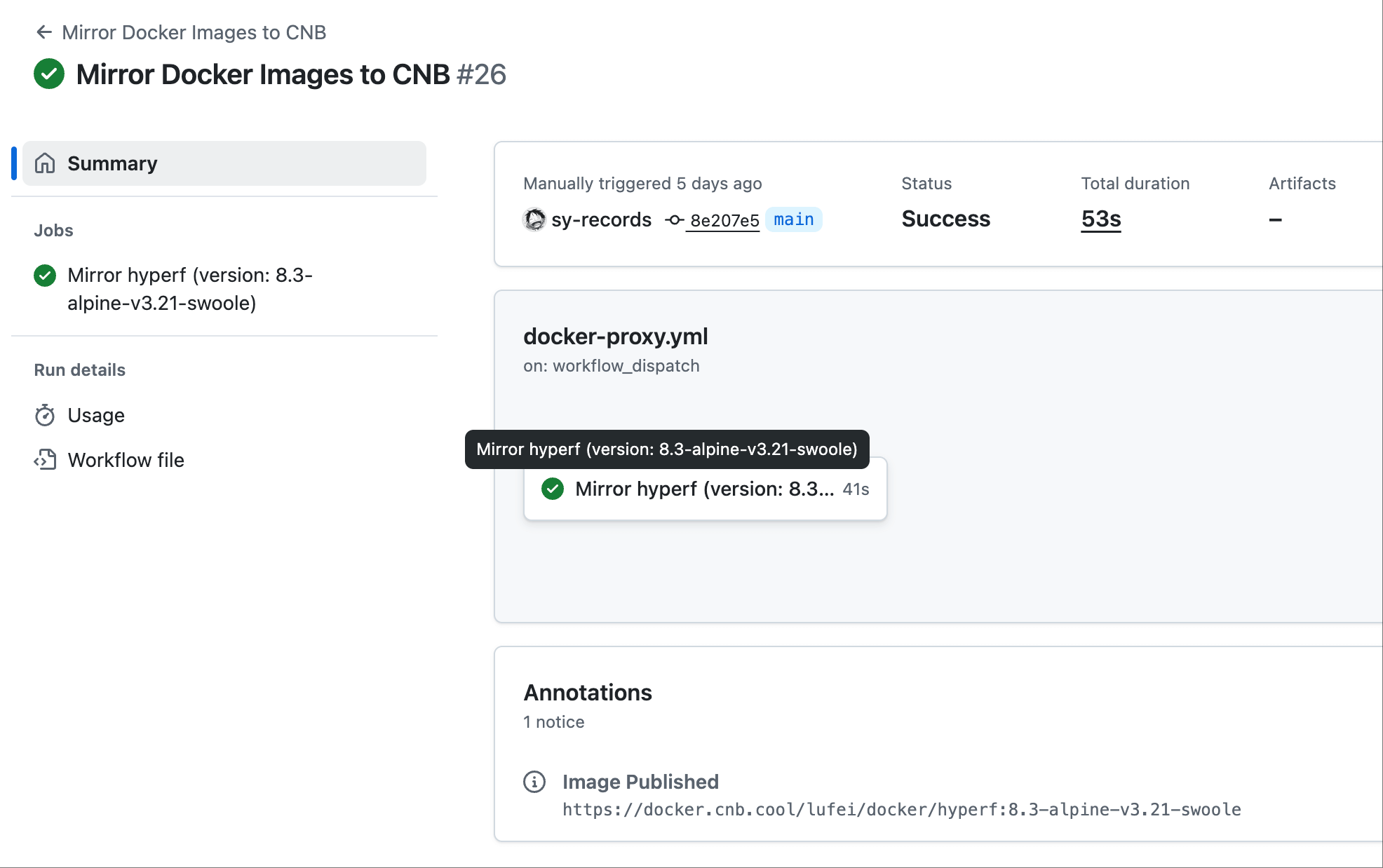
每次更新 .github/images.yml 文件并推送到 main 分支时,会自动同步所有的镜像。
同步完成后,用户可直接通过 CNB 公网地址拉取镜像:
docker pull docker.cnb.cool/lufei/docker/hyperf:8.3-alpine-v3.21-swoole加上https://可以访问网页查看详情:
| 名称 | 用途说明 |
|---|---|
DOCKERHUB_USERNAME |
用于拉取源镜像 |
DOCKERHUB_TOKEN |
Docker Hub 登录 token |
CNB_DOCKER_TOKEN |
CNB 镜像仓库推送凭据 |
CNB 默认可以创建 npm、Composer 等的制品库,但 Docker 的制品默认就在仓库中,所以创建一个仓库即可。
通过 GitHub Actions + skopeo + CNB 服务,我们构建了一个可复用、自动化、支持多镜像同步的工具链,显著提升了镜像的可用性与部署效率。
Bensz
Docker系列 Bensz Channel:构建AI时代Up主和粉丝互动的高效平台
本博客由AI模型商OhMyGPT强力驱动!如何更快地访问本站?有需要可加电报群获得更多帮助。本博客用什么VPS?创作不易,请支持苯苯!推荐购买本博客的VIP喔,10元/年即可畅享所有VIP专属内容! 个人开发不易,欢迎大家点Star关注,谢谢啦: 概览 基于 Laravel + Better Auth + PostgreSQL + Redis 构建的现代化 Web 社区平台 支持 OpenClaw、Claude Code、Codex 等 Vibe Coding 工具远程控制,AI 可自动发布更新、管理内容 支持多种登录方式(邮箱验证码、邮箱密码、微信/QQ 扫码)与完整的用户权限管理 内置 Markdown 编辑器,支持粘贴图片自动上传,提供 SMTP 邮件订阅与 RSS 订阅 游客访问自动使用预构建静态 HTML + Gzip 压缩,性能优化到极致 Docker Compose 一键部署 […]

本文永久链接 – https://tonybai.com/2026/03/09/a-decade-of-docker-containers
大家好,我是Tony Bai。
2013年,当 Solomon Hykes 在 PyCon 上首次演示 Docker 时,他用一种名为“容器”的魔法,将开发者从依赖地狱中解救了出来。转眼间,十三年过去了。今天,Docker Hub 托管着超过 1400 万个镜像,每月拉取量超 110 亿次。它不仅是 Kubernetes 的基石,更是从流媒体到太空探索的底层引擎。
表面上看,Docker 只是简单的 build, push, run。但在这极简的开发者体验背后,是横跨操作系统、虚拟化、网络架构和硬件驱动的深水区。近日,Docker 领域的三位重量级人物(Anil Madhavapeddy, David J. Scott, Justin Cormack)在ACM通信上联合发表了万字长文《A Decade of Docker Containers》,首次全景式披露了 Docker 十年来的核心技术挑战与架构演进。
本文将带你一起解读这篇重磅论文,了解一下Docker这十年来背后不为人知的精彩故事。

在 2000 年代初,配置一台服务器是一场噩梦,你需要手动解决各种动态库的依赖冲突。到了 2010 年代,云计算兴起,主流的隔离方案是虚拟机(VM)。
虚拟机虽然隔离性好,但极其笨重。它需要完整的客户机内核、独立的虚拟磁盘和重复的内存开销。如果你只想在一台机器上跑十个轻量级微服务,虚拟机显然不是最优解。
另一方面,早期的 Linux 提供了一些原生隔离工具(如 1978 年引入的 chroot),但它们无法解决网络端口冲突等问题。像 Nix 和 Guix 这样的系统试图通过重组文件目录来解决依赖问题,但这要求重写所有的软件打包方式,门槛极高。
Docker 的天才之处,在于它找到了一种“务实的妥协”:利用 Linux Namespaces。
Namespaces(命名空间)并非 Docker 发明。自 2001 年起,Linux 内核逐步引入了 Mount(文件系统)、IPC、Network 等七种命名空间。它们允许在共享同一个系统内核的前提下,让每个进程拥有独立的资源视图。

如上图所示,通过 Mount Namespace,容器 A 看到的是 /alice/etc/passwd,而容器 B 看到的是 /bob/etc/passwd,但它们都以为自己访问的是根目录下的 /etc/passwd。这种机制的开销远低于启动一个完整的 Linux VM,通常只需不到一秒即可完成环境隔离。
Docker 将这些原本低级且晦涩的内核 API 进行了高层封装,结合基于联合文件系统(如 overlayfs)的层级镜像(Layered Images)机制,彻底奠定了容器技术的物理基础。
Docker守护进程最初是一个单体程序,但在 2015 年左右,Docker团队将其拆分为如下图所示的 7 个专用组件。第一个组件 buildkit 负责组装文件系统镜像,然后 containerd 管理将这些镜像实例化为运行中的容器,并配置相关的网络和存储资源。

Docker 诞生之初有一个致命的局限:它只能在 Linux 内核上运行。
但在现实世界中,绝大多数开发者使用的是 macOS 或 Windows 笔记本。为了让这些开发者能在本地顺畅地构建和测试容器,Docker 团队面临着其历史上最大的工程挑战之一:如何在非 Linux 宿主机上,提供与 Linux 原生体验一致的 docker run 和 localhost 访问?
最初,开发者必须使用 VirtualBox 这样的重量级独立虚拟机来运行 Linux。这种体验是割裂的:你需要管理虚拟机的生命周期,网络端口映射极其繁琐。
Docker 团队决定重构架构。他们采用了一种被称为“库虚拟机监控器(Library VMM)”的先进理念,结合了他们在 Unikernel 领域的研究成果。

如上图所示,在 macOS 上,Docker 开发了 HyperKit,利用 Apple 原生的 Hypervisor 框架,将一个极简的 Linux 虚拟机(基于定制的 LinuxKit 操作系统)直接嵌入到了 Docker 桌面端应用进程中。开发者在终端敲下的 docker build 命令,会通过隐形的 AF_VSOCK (虚拟套接字) 直接发送到这个嵌入式 Linux 内核中的 dockerd 守护进程。
这种设计使得虚拟机变得“隐形”,实现了无缝的客户端-服务器交互。
有了隐形虚拟机,更大的麻烦来了——网络联通性。
传统的桥接网络(Bridged Network)在企业环境中经常被防火墙和安全软件拦截,因为这种网络流量看起来像是绕过了宿主机网络栈的“未知进程”。同时,开发者希望在容器内监听 80 端口后,能在 Mac 的浏览器里直接通过 localhost:80 访问。
为了解决这个问题,Docker 团队做出了一个疯狂的决定:他们复活了一个诞生于 1990 年代中期、最初用于 Palm Pilot PDA 拨号上网的古老工具——SLIRP。

如上图所示,Docker 团队用 OCaml 语言重写了一个用户态的 TCP/IP 协议栈(命名为 vpnkit)。
这样一来,从企业防火墙的角度看,所有的网络请求都像是 Docker Desktop 这个普通应用程序发出的,从而完美绕过了安全拦截。这项被称为 SLIRP 的古老技术,在云原生时代焕发了第二春,将企业用户的网络 Bug 报告减少了 99% 以上。
不仅是网络,存储同样面临跨系统的挑战。Linux 的“绑定挂载(Bind Mount)”无法直接跨操作系统工作。Docker 利用 virtio-fs 协议,将 Mac/Windows 的文件系统操作转换为 FUSE 请求发送给宿主机,实现了代码热重载。
而在 Windows 阵营,随着 2018 年微软推出 WSL2(Windows Subsystem for Linux 2),情况迎来了转机。WSL2 本质上是在后台运行了一个高度优化的轻量级 Linux 虚拟机。Docker 顺势而为,将 Docker 引擎直接集成到 WSL2 中,彻底消除了早期使用 Hyper-V 时的性能损耗和体验割裂。
进入 2020 年代后,基础设施硬件发生了翻天覆地的变化。Docker 的技术版图也被迫(且成功地)向异构计算延伸。
随着 Apple M 系列芯片和 AWS Graviton 架构的普及,开发者不再局限于 x86 (AMD64) 架构。Docker 必须支持“一次构建,多架构分发”。
除了在 OCI 镜像规范中引入“多架构清单(Multi-arch Manifests)”外,Docker 还利用了 Linux 的一个冷门特性 binfmt_misc,结合 QEMU 模拟器。这使得开发者在 Mac M1(ARM)上构建镜像时,遇到 x86 的二进制指令,可以透明地通过 QEMU 翻译执行。虽然在构建阶段有性能损耗,但这完美解决了交叉编译的噩梦。
随着安全要求的提高,机密计算(Confidential Computing)成为热门。可信执行环境(TEE,如 Intel SGX 或 AMD SEV)允许在内存中创建一个被硬件加密的飞地(Enclave),甚至连宿主机操作系统都无法窥探其中的数据。
由于配置 TEE 的复杂度极高(相当于在里面启动一个微型内核),Docker 将其客户端-服务器架构发挥到了极致。开发者可以在本地使用 Docker CLI,将加密信息通过安全的 Socket 转发,直接部署并管理运行在云端 TEE 环境中的容器,兼顾了本地开发的便利性和云端的极致安全。
2023 年以来,AI 工作负载的爆发给容器带来了全新的难题:GPU 强绑定。
Docker 的初衷是解耦底层的硬件和系统,但 GPU 驱动却要求容器内的用户态动态库(User-space libraries)与宿主机的内核态驱动(Kernel driver)必须严格版本匹配。
为了解决这个矛盾,Docker 从 2023 年起全面支持了 容器设备接口(Container Device Interface, CDI)。这允许在容器启动时,动态地将特定 GPU 的设备文件和动态库“绑定挂载”到容器中,并重新生成链接器缓存(ld.so cache)。
然而,论文作者也坦言,目前的解决方案远未完美。GPU 的标准化程度远不及 CPU,针对 Nvidia GPU 编写的应用容器,依然无法在 Apple 的 M 系列 GPU 上无缝运行。硬件虚拟化和指令集翻译在 GPU 领域仍是一个巨大的挑战,整个社区仍在寻找更通用的抽象层(如 Triton 等中间语言)。

时间来到 2026 年,软件开发的范式正在被 AI 重塑。
如图所示,今天的开发者工作流(Workflow)已经不仅仅是 build 和 run。它融合了持续部署、云端卸载(Docker Build Cloud)、以及运行在容器内的 AI 智能体(Agentic Coding)。
未来的AI 智能体将通过 MCP(模型上下文协议,Model Context Protocol)直接调用容器内的工具和环境进行代码的编写、测试和调试。在这个过程中,Docker 扮演了一个“隐形的安全沙箱”。它必须足够轻量,以便 AI Agent 瞬间启动成百上千个测试环境;又必须足够安全,防止 AI 生成的未知代码破坏宿主机甚至横向渗透网络。
回望这十年,Docker 的成功绝不是偶然。它不是一项单一的颠覆性发明,而是一系列持续不断的、精妙的系统工程组合拳。
从最初利用 Linux Namespaces 寻找轻量级虚拟化的平衡点,到为了征服 macOS 和 Windows 桌面端而重构底层虚拟化和网络协议,再到如今积极适配 ARM、TEE 和 GPU 等异构硬件,Docker 始终在做一件事:为开发者屏蔽掉底层基础设施的混乱,提供一个统一、优雅、且安全的“集装箱”。
在不可预测的 AI 时代,底层的复杂性只会呈指数级上升。而我们需要像 Docker 这样久经考验的基础设施,在幕后默默地为每一次“创新”提供稳固的地基。
正如论文作者所言:“如果说我们有一个终极目标,那就是让 Docker 成为一个隐形的伴侣。你看不见它,但它能让你更快、更享受地交付代码。”
资料链接:
你的第一个容器跑的是什么?
回望十年,Docker 已经从一个“玩具”变成了世界的底座。你还记得自己第一次运行 docker run 时的感受吗?在你的开发流中,Docker 解决过的最让你难忘的 Bug 是什么?
欢迎在评论区分享你的 Docker 记忆或对“AI 容器”的脑洞!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。

你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!

想系统学习Go,构建扎实的知识体系?
我的新书《Go语言第一课》是你的首选。源自2.4万人好评的极客时间专栏,内容全面升级,同步至Go 1.24。首发期有专属五折优惠,不到40元即可入手,扫码即可拥有这本300页的Go语言入门宝典,即刻开启你的Go语言高效学习之旅!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。

© 2026, bigwhite. 版权所有.

本文永久链接 – https://tonybai.com/2026/03/08/her-power-in-code-pioneers-to-ai-era
大家好,我是Tony Bai。
当我们闭上眼睛,想象一个“程序员”的形象时,脑海中浮现的画面是什么?
很长一段时间里,流行文化和媒体在不遗余力地塑造一种刻板印象:穿着格子衬衫、戴着黑框眼镜、不善言辞的男性,在昏暗的灯光下敲击着键盘。硅谷的“兄弟会文化(Bro-culture)”更是将这种刻板印象固化,仿佛编程从诞生之日起,就是一项由男性绝对主导的活动。
然而,如果我们翻开计算机科学的真实历史,会发现一个令人惊讶,甚至有些反直觉的事实:在计算机刚刚诞生的黎明期,编程,曾经是一项被普遍认为“适合女性”的工作。
在二战期间,由于男性大量奔赴前线,世界上第一台通用电子计算机 ENIAC 的初代程序员团队,清一色全是由六位杰出的女性组成。她们在没有编程语言、没有编译器的时代,用插拔线缆和拨动开关的纯物理方式,完成了极其复杂的弹道轨迹计算。
然而,随着软件产业的爆炸式增长,薪资与地位水涨船高,女性在科技行业的比例却开始出现诡异的下滑,她们的名字也逐渐被隐藏在庞大服务器的阴影之中。
今天是 3 月 8 日国际妇女节。在这个特殊的日子里,让我们暂时停下手中正在 Review 的代码,去擦拭掉历史上的偏见灰尘。我们要重新认识那些在计算机科学发展史上立下不朽丰碑的女性先驱,看看当今站在技术浪潮之巅的领航者,并探讨在汹涌而来的 AI 时代,“巾帼力量”为何比以往任何时候都更加不可或缺。
代码是没有性别的,但在计算机还是一堆庞大齿轮或真空管的年代,是这些女性赋予了冷冰冰的机器以“逻辑的灵魂”。

要追溯程序员的祖师爷,我们必须回到 19 世纪中叶的英国。著名诗人拜伦的女儿,Ada Lovelace,被公认为世界上的第一位程序员。
当时的数学家查尔斯·巴贝奇正在设计一台名为“分析机”的庞大机械装置。在多数人看来,这只是一个能做加减乘除的超大号计算器。但 Ada 展现出了超越时代一个世纪的惊人洞察力。
在翻译和注释关于分析机的文章时,她不仅写下了世界上第一段计算机算法(用于计算伯努利数),更重要的是,她写下了一段堪称“预言”的批注。Ada 指出,如果分析机能够处理数字,那么只要将事物(如字母、音乐)转化为数字,机器就能处理任何事物。
“分析机编织的是代数模式,就像提花织机编织树叶和花朵一样。”
这是一种被称为“诗意科学”的浪漫与理性的结合。Ada 早在计算机诞生前 100 年,就看透了现代计算机的本质:它不仅仅是计算工具,而是通用的信息处理引擎。今天美国国防部开发的 Ada 语言,正是为了纪念这位伟大的女性“先知”。

如果说 Ada 给出了灵魂,那么 Grace Hopper 则是真正让机器“听懂”人类语言的架构师。
在 20 世纪 50 年代,程序员们必须用极其难懂的二进制机器码来编写指令。这种方式不仅痛苦,而且极易出错。Hopper 坚信,程序员应该能够用接近英语的语言来编写代码,然后再由机器自己将其翻译成机器码。
当她提出这个想法时,遭到了几乎所有同行的嘲笑和拒绝。他们认为“计算机只能懂数字,不可能懂英语”。但 Hopper 是一位拥有美国海军准将军衔的“硬核”女性,她顶住了所有压力,成功开发出了世界上第一个编译器 A-0,并直接主导了后来统治商业系统数十年的 COBOL 语言的诞生。
除了这项伟大的技术发明,Hopper 还给全世界程序员留下了一个最常用的口头禅。1947 年,她在哈佛大学的一台继电器计算机里发现了一只导致故障的真实飞蛾(Moth)。她将这只飞蛾粘在日志本上,并在旁边写下:“First actual case of bug being found.(发现的第一个真正的 Bug)”。从此,程序员排查错误的过程,就永远被称为了 “Debug”(除虫)。

有一张在科技史流传甚广的照片:一位年轻的戴着大框眼镜的女性,微笑着站在一堆比她自己还要高的打印源代码旁。她就是 Margaret Hamilton,阿波罗 11 号登月计划的首席软件工程师。
在 1969 年那个登月舱只有几十 KB 内存的年代,写代码绝不容许有任何试错的空间。更重要的是,在那个年代,“软件”甚至不被认为是一门严谨的工程学科。是 Hamilton 第一次创造了 “软件工程 (Software Engineering)” 这个词,并为其赋予了与硬件工程同等的严谨性。
她的远见卓识在历史性的一刻拯救了全人类的心跳。就在阿波罗 11 号即将降落月球表面的最后 3 分钟,由于雷达系统的硬件故障,登月舱的计算机突然被大量无关的数据淹没,系统濒临崩溃,警报声大作。
在地面指挥中心准备下令中止登月时,Hamilton 带领团队设计的“异步优先调度(Asynchronous Executive)”机制发挥了奇效。这段极其健壮的容错代码,让计算机瞬间抛弃了低优先级的雷达任务,将全部仅存的算力集中在最关键的着陆控制上。
阿姆斯特朗成功踏上了月球,而这背后,是 Hamilton 用代码织就的绝对安全网。
历史的丰碑固然闪耀,但“巾帼力量”绝不仅仅存在于泛黄的黑白照片中。当我们把视线拉回当代,你会发现在云计算、开源社区和最前沿的人工智能领域,女性依然是不可或缺的领航者。

在开源世界的深水区,也就是最具“硬核极客文化”的容器和底层基础设施领域,Jessie Frazelle 的名字如雷贯耳。作为 Docker 的核心维护者之一,她写下了 Docker 中许多最底层的安全和隔离特性代码。她以一人之力在充满偏见和偶尔充斥着“有毒(Toxic)”言论的开源社区中杀出一条血路,证明了女性同样可以在最底层的系统编程中达到登峰造极的水平。

而在当今如火如荼的 AI 浪潮中,我们更不能忘记李飞飞 (Fei-Fei Li)。在深度学习还处于被学术界边缘化的低谷期时,李飞飞敏锐地意识到:模型再好,没有海量的高质量数据也无法发生质变。于是,她顶住巨大压力,发起了 ImageNet 计划,构建了一个包含 1400 万张标注图片的庞大数据库。
正是 ImageNet 的存在,直接催生了 2012 年 AlexNet 的横空出世,引发了这一轮浩浩荡荡的深度学习和 AI 大爆发。她被称为“AI 界的拓荒者”,用女性特有的坚韧和长远目光,为整个行业打下了最坚实的地基。
2024 年至今,随着生成式 AI(GenAI)、大型语言模型(LLM)以及自主 Agent(如 Claude Code, Cursor)的极速普及,软件工程的范式正在经历一场彻底的颠覆。
“敲击代码”这一纯体力的动作正在被 AI 代替。很多从业者感到恐慌:如果机器能在几秒钟内写出完美的并发处理代码,程序员的价值到底在哪里?
讽刺的是,这场由机器主导的技术革命,反而为女性程序员在科技行业中的地位跃升,提供了百年难遇的新契机。为什么这么说?
在传统的编程时代,程序员需要像机器一样思考,用极其死板和严苛的语法去迎合编译器。这在某种程度上,筛选出了一批极度专注于逻辑细节、但不一定擅长横向沟通的人群。
但在 AI 辅助编程时代,人类的角色从“写代码的工人”变成了“指挥 AI 的产品经理”。你需要做的是深刻理解业务需求、拆解复杂系统,并用自然语言(Prompt)精准地将意图传达给 AI。
这要求极高的沟通能力、同理心、大局观以及对模糊意图的澄清能力。而这些,恰恰是许多女性在长期社会化过程中被培养出的显著优势。未来的顶级工程师,不再是那些能背诵冷门 API 的人,而是那些能够清晰表达意图、优雅编排多个 AI Agent 协同工作的“交响乐指挥”。
AI 就像一面镜子,它会无情地反射并放大人类社会中存在的所有偏见。如果我们训练 AI 模型的工程师团队是清一色的单一性别、单一族裔(例如传统的“硅谷白人男性俱乐部”),那么这个 AI 生成的简历筛选算法、医疗诊断模型或是自动驾驶策略,必然会带有难以察觉的系统性偏见。
在 AI 对齐(Alignment)和 AI 安全(AI Safety)领域,我们需要多元化的视角来纠正机器的偏见。女性研究者和工程师在感知社会公平、识别弱势群体需求方面往往具有更敏锐的触觉。如今,在 OpenAI、Anthropic 等顶级 AI 实验室中,主导 AI 伦理和安全护栏工作的核心领导层中,出现了越来越多卓越的女性身影。比如Anthropic联合创始人阿曼达·阿斯克尔(Amanda Askell),就是一位训练有素的哲学家,她帮助管理Claude的个性。没有女性参与的 AI,注定是一个有缺陷的 AI。
由于 AI 极大地降低了后端的复杂度和前端页面的构建门槛,“一人公司”或“超级小团队”正在成为现实。
这要求未来的开发者必须是懂产品、懂设计、懂用户心理的“全栈通才”。仅仅会写高并发代码已经不够了,你还需要知道如何设计出让用户感到温暖、舒适的交互界面。女性往往具备更强的跨界融合能力和细腻的用户感知能力,在“技术与人文的十字路口”,她们将比纯粹的“代码机器”爆发出更强大的创造力。
回顾历史,从 Ada Lovelace 描绘在纸带上的第一个循环,到 Grace Hopper 拔出的第一只真实飞蛾;从 Margaret Hamilton 保护阿波罗登月的汇编指令,到如今女性工程师在 LLM 底层写的对齐代码。
女性,从未在计算机科学的历史中缺席。 她们不仅是历史的参与者,更是很多决定性瞬间的缔造者。
然而,我们依然要清醒地看到,今天在 GitHub 的开源提交中、在科技公司的高管会议室里,女性的比例依然没有达到应有的平衡。打破这种隐形的“天花板”和玻璃墙,需要我们每一个人——无论男女——去对抗潜意识中的刻板印象。
代码没有性别,Bug 也不分男女。优秀的架构设计只认同逻辑的严密,而不关心键盘后那双手的粗细。
在这个 AI 浪潮奔涌的时代前夕,让我们向所有奋斗在键盘前、熬夜在服务器旁、在开源社区里无私贡献的女程序员们致以最崇高的敬意。
愿 Ada 的远见、Hopper 的坚持和 Hamilton 的严谨,能够化作一行行永不退色的代码,注入到每一位女性开发者的指尖。
3.8 国际妇女节快乐!愿你们继续用代码,勇敢、自由地编译属于你们的未来!
致敬身边的“她”
在你的开发生涯中,是否曾遇到过让你深感佩服的女性技术伙伴?或者,作为一名女性开发者,你在 AI 时代的浪潮中有什么独特的感悟?
欢迎在评论区留下你对“她”的赞美或故事!我们将精选留言,一起传递这份力量。
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!
想系统学习Go,构建扎实的知识体系?
我的新书《Go语言第一课》是你的首选。源自2.4万人好评的极客时间专栏,内容全面升级,同步至Go 1.24。首发期有专属五折优惠,不到40元即可入手,扫码即可拥有这本300页的Go语言入门宝典,即刻开启你的Go语言高效学习之旅!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

本文永久链接 – https://tonybai.com/2026/01/29/wso2-goodbye-java-hello-go-tech-stack-shift
大家好,我是Tony Bai。
“当我们 2005 年创办 WSO2 时,开发服务端企业级基础设施的正确语言毫无疑问是:Java。然而,当我们走过第 20 个年头并展望未来时,情况已经变了。”
近日,全球知名的开源中间件厂商 WSO2 发布了一篇震动技术圈的博文——《Goodbye Java, Hello Go!》。
这是企业级软件在云原生时代技术风向标的一次重要偏转。作为 Java 时代的既得利益者,WSO2 曾在 API 管理、集成中间件领域构建了庞大的 Java 帝国。为何在今天,他们会做出如此激进的转向?Java 真的不适合未来了吗?Go 到底赢在哪里?
让我们深入剖析这背后的技术逻辑、架构变迁与社区的激烈争议。

WSO2 的转向并非一时冲动,而是基于对过去 15 年基础设施软件形态深刻变化的洞察。其博文中极其精准地总结了这一变迁:
在 2010 年代之前,中间件是以独立“服务器”(Server)的形式交付的。
那是一个“重量级”的时代。你部署一个服务器,然后把你的业务逻辑(WAR 包、JAR 包)扔进去运行。这正是 Java 和 JVM 的黄金时代——JVM 作为一个强大的运行时环境,提供了热加载、动态管理、JIT 优化等一系列高级功能,完美匹配了这种“长时间运行、多应用共享”的服务器模式。
然而,容器化时代终结了这一切。
现在的“服务器”不再是一个独立的实体,而变成了一个库 (Library)。
在 WSO2 看来,“独立软件服务器的时代已经结束了”。这对于 Java 来说,是一个底层逻辑的打击。
在过去,一个服务器启动慢点没关系,因为它一旦启动,可能会运行数月甚至数年。JVM 的 JIT(即时编译)机制通过预热来换取长期运行的高性能,这是一种非常合理的权衡。
但在 Kubernetes 和 Serverless 主导的今天,服务器变得极度短暂 (Ephemeral)。
在这种场景下,启动时间就是服务质量 (SLA)。
WSO2 指出:“容器应该在毫秒级内准备好起舞,而不是秒级。” Java 庞大的生态依赖(Spring 初始化、类加载、注解扫描)和 JVM 的启动开销,在云原生环境下显得格格不入。内存膨胀(Memory Bloat)也直接推高了云厂商的账单。
面对挑战,Java 社区并非无动于衷。GraalVM Native Image 试图通过 AOT(提前编译)解决启动速度问题;Project Loom 试图通过虚拟线程解决并发资源消耗问题。
但在 WSO2 的架构师们看来,这些努力更像是一种“追赶式的修补”。
“这些解决方案感觉就像是在为一个不同时代设计的语言和运行时进行翻新。”
GraalVM 虽然强大,但带来了构建时间的剧增、反射的限制以及调试的复杂性。相比之下,Go 语言在设计之初就原生 (Native) 地考虑了这些问题:编译即二进制,启动即巅峰,并发即协程。这是一种“原生契合”与“后天适配”的本质区别。
WSO2 并没有盲目地全盘推翻,他们对企业级软件的三层架构(前端、中间层、后端)进行了冷静的评估:
这是一个每个技术决策者都会面临的灵魂拷问:既然要追求性能和原生编译,为什么不选 Rust?它不是更快、更安全吗?
WSO2 的回答展现了极高的工程务实精神。他们确实评估了 Rust,但最终选择了 Go。理由如下:
WSO2 构建的是中间件基础设施(如 API Gateway, Identity Server)。在这个层级,“我们总是比裸金属 (Bare Metal) 高那么一点点”。Go 提供的自动垃圾回收 (GC) 和高效的并发原语,恰好处于这个“甜点”位置。
Rust 的所有权模型 (Ownership) 和借用检查器 (Borrow Checker) 虽然保证了内存安全,但也带来了极高的学习曲线和开发摩擦。对于大多数企业级业务逻辑来说,Rust 提供的控制力是多余的,而为此付出的开发效率代价是昂贵的。
这是一个无法忽视的因素。Go 是云原生的“普通话”。
Kubernetes、Docker、Prometheus、etcd、Terraform…… 几乎所有现代基础设施的基石都是用 Go 构建的。选择 Go,意味着:
WSO2 并非纸上谈兵,他们在过去十年中已经在多个关键项目中验证了 Go 的能力:
这是 WSO2 最具野心的项目之一,一个面向 Kubernetes 的开发者平台(IDP)。
这是一个惊人的决定。Ballerina 语言最初是基于 Java 实现的(运行在 JVM 上)。现在,WSO2 正在用 Go 完全重写 Ballerina 编译器。
身份认证(IAM)通常处于请求链路的关键路径上,对延迟极其敏感。Thunder 利用 Go 的高并发处理能力,实现了在高负载下的低延迟认证,且在容器化环境中具备极快的冷启动能力。
这篇博文在 Reddit 的 r/golang 板块引发了数百条评论的激烈讨论。这不仅仅是语言之争,更是两种工程文化的碰撞。
“这是管理层的愚蠢决定”:
一位愤怒的网友评论道:“计算资源是廉价的,开发人员的时间才是昂贵的。” 他认为,虽然 Go 节省了内存,但在业务逻辑极其复杂的企业级应用中,Java 强大的 IDE 支持、成熟的设计模式和庞大的生态库能显著降低开发成本。强行切换到 Go,可能会导致开发效率的崩塌。
“Java 并没有停滞不前”:
很多 Java 支持者指出,WSO2 对 Java 的印象似乎还停留在 Java 8 时代。现代 Java (21+) 引入了 Virtual Threads (Project Loom),在并发模型上已经可以与 Go 的 Goroutine 媲美;而 GraalVM 的成熟也让 Java 能够编译成原生镜像,启动速度不再是短板。
“生态位的不可替代性”:
在处理遗留系统(如 SOAP, XML, 复杂的事务处理)方面,Java 积累了 20 年的库是 Go 无法比拟的。用 Go 去重写这些复杂的业务逻辑,无异于“重新发明轮子”,且容易引入新的 Bug。
“运维友好才是真的友好”:
一位 DevOps 工程师反驳道:“在微服务架构下,运维成本是巨大的。” Go 生成的静态二进制文件(Static Binary)是运维的梦想——没有依赖地狱,没有 JVM 版本冲突,所有东西都打包在一个几 MB 的文件里。这种部署的便捷性,是 Java 永远无法达到的。
“简洁是一种防御机制”:
Java 项目容易陷入“过度设计”的泥潭——层层叠叠的抽象、复杂的继承关系、魔法般的注解。Go 的强制简洁性(没有继承、显式错误处理)虽然写起来啰嗦,但读起来轻松。在人员流动频繁的大型团队中,Go 代码的可维护性往往优于 Java。
“云原生的网络效应”:
正如 WSO2 所言,如果你在写 K8s Controller,如果你在写 Sidecar,如果你在写网关,Go 就是默认语言。这不仅仅是语言特性的问题,这是生态引力的问题。逆流而上使用 Java 编写这些组件,会让你失去整个社区的支持。
WSO2 的声明并非要“杀死” Java。他们明确表示,现有的 Java 产品线将继续得到长期支持。但在新一代的云原生基础设施平台上,他们坚定地选择了 Go。
这一选择揭示了软件行业的一个趋势:通用编程语言的时代似乎正在结束,“领域专用语言”的时代正在到来。
对于 Gopher 而言,WSO2 的转型是一个强有力的信号:你们选对了赛道。Go 不仅是 Google 的语言,它正在成为定义未来十年企业级基础设施的通用语。
资料链接:
你的技术栈“保卫战”
WSO2 的转身,是时代的缩影,也是个体的写照。在你的团队中,是否也发生过类似的“去 Java 化”或“拥抱 Go”的讨论?你认为在云原生时代,Java 还能守住它的江山吗?
欢迎在评论区分享你的观点或经历,无论是坚守者还是转型者,我们都想听听你的声音!
如果这篇文章引发了你的思考,别忘了点个【赞】和【在看】,并转发给你的架构师朋友,看看他们怎么选!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

本文永久链接 – https://tonybai.com/2026/01/22/why-are-we-still-talking-about-containers-in-ai-age
大家好,我是Tony Bai。
“如果你在 2014 年告诉我,十年后我们还在讨论容器,我会觉得你疯了。但现在是 2025 年,我们依然在这里,谈论着同一个话题。”
在去年中旬举行的 ContainerDays Hamburg 2025 上,早已宣布“退休”的云原生传奇人物 Kelsey Hightower 发表了一场发人深省的主题演讲。在这个 AI 狂热席卷全球的时刻,他没有随波逐流地去谈论大模型,而是回过头来,向所有技术人抛出了一个灵魂拷问:

为什么我们总是在追逐下一个热点,却从来没有真正完成过手头的工作?
Kelsey 首先回顾了他职业生涯中经历的三次技术浪潮:Linux 取代 Unix(AIX、Solaris等)、DevOps 的兴起、以及 Docker/Kubernetes 的容器革命。
他敏锐地指出,技术圈似乎陷入了一个无休止的“海啸循环”:
“我们就像一群踢足球的孩子,看到球滚到哪里,所有人就一窝蜂地冲过去,连守门员都离开了球门。结果是,球门大开,后方空虚。”
这就是为什么 10 年过去了,我们还在谈论容器。因为我们当年并没有真正“完成”它。我们留下了无数的复杂性、不兼容和“企业级发行版”,却忘了初衷。
在演讲中,Kelsey 分享了他最近的一个惊人发现:Apple 正在 macOS 中原生集成容器运行时。

这不是 Docker Desktop,也不是虚拟机套娃,而是操作系统级别的原生支持。这就是 GitHub 上的一个名为 apple/container 的 Apple 开源项目:

Kelsey 提到 contributors 中有 Docker 元老 Michael Crosby ,Michael Crosby 正在 Apple 做着这件“不性感”但极其重要的事情。
Kelsey 认为,这才是容器技术的终局:
这正是那些没有去追逐 AI 热点,而是选择留在“球门”前的人,正在默默完成的伟大工程。
作为 Google 前员工,Kelsey 对 AI 并不陌生。但他对当前的 LLM 热潮保持着清醒的警惕。
他现场演示了一个有趣的实验:询问一个本地运行的 LLM “FreeBSD Service Jails 需要什么版本?”
* AI 的回答:FreeBSD 13(一本正经的胡说八道)。
* 真相:FreeBSD 15(尚未发布)。
Kelsey 指出,现在的 AI 就像一个热心但糊涂的路人,它不懂装懂,只想取悦你。
他的建议是:
演讲的最后,Kelsey 回答了关于开源、职业发展和未来的提问。他的几条忠告,值得每一位技术人铭记:
Kelsey Hightower 的这场演讲,是对当前浮躁技术圈的一剂清醒剂。
他提醒我们,技术的真正价值,不在于它有多新、多热,而在于它是否真正解决了问题,是否被完整地交付了。在所有人都在谈论 AI 的今天,或许我们更应该关注那些被遗忘的“球门”,去完成那些尚未完成的伟大工程。
资料链接:https://www.youtube.com/watch?v=x1t2GPChhX8
你的“烂尾”故事
Kelsey 的“海啸循环”论断让人深思。在你的职业生涯中,是否也经历过这种“还没做完旧技术,就被迫去追新热点”的无奈?你认为在这个 AI 时代,我们该如何保持“工匠精神”?
欢迎在评论区分享你的经历或思考!让我们一起在喧嚣中寻找内心的宁静。
如果这篇文章让你停下来思考了片刻,别忘了点个【赞】和【在看】,并转发给那些还在焦虑中奔跑的同行!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.
Bensz
Docker系列 MetaMCP为Vibe Coding工具添加远程MCP支持
本博客由AI模型商OhMyGPT强力驱动!如何更快地访问本站?有需要可加电报群获得更多帮助。本博客用什么VPS?创作不易,请支持苯苯!推荐购买本博客的VIP喔,10元/年即可畅享所有VIP专属内容! 概览 MetaMCP 是一个强大的模型上下文协议(Model Context Protocol)聚合管理平台 适合多设备场景:统一部署 MCP 服务器,避免在每个设备上重复配置 经过 18 个同类方案对比,MetaMCP 在功能全面性和部署简易性方面脱颖而出 支持将多种 MCP 服务器统一管理,提供命名空间和端点功能 包含完整的 Docker 部署方案,预配置 11 种常用 MCP 服务器 集成 PostgreSQL 数据库和 SearXNG 搜索引擎 支持多客户端接入,提供 API Key 认证机制 前言 最近在折腾各种 AI 编程工具的时候,发现了一个很酷的项目——MetaMCP。它可以把 […]
Qwen2.5-32B 和 Qwen2.5-VL-32B 是通义千问(Qwen)系列中的两个大模型,分别对应纯语言模型(LLM)和多模态视觉-语言模型(VLM)。Docker环境安装与配置 NVIDIA Container Toolk,下载大模型参考 Docker部署bge-m3/bge-reranker模型。
| 模型名称 | 类型 | 参数量 | 特点 |
|---|---|---|---|
| Qwen2.5-32B | 纯文本语言模型 | ~32B | 支持中英文,推理、代码、对话能力强 |
| Qwen2.5-VL-32B | 视觉-语言多模态模型 | ~32B(含视觉编码器) | 支持图像理解、图文问答、多模态推理 |
注意:Qwen2.5-VL 基于 Qwen2.5 语言主干 + 视觉编码器(如 SigLIP 或 CLIP 变体),需同时加载视觉和语言组件。
部署前,需确认硬件环境满足基本要求。由于Qwen2.5-VL-32B是多模态模型,其显存需求通常高于纯文本模型。
| 资源 | Qwen2.5-32B (纯文本) | Qwen2.5-VL-32B (多模态) | 说明 |
|---|---|---|---|
| GPU显存 | 建议 ≥ 24GB (单卡) | 建议 ≥ 32GB (单卡或多卡) | 使用量化版本(如GPTQ-Int4)可大幅降低显存需求。 |
| 系统内存 | 建议 32GB+ | 建议 64GB+ | 避免模型加载时内存溢出(OOM)。 |
| 磁盘空间 | 模型文件约需 60GB+ | 模型文件约需 70GB+ | 需预留额外空间存放Docker镜像和依赖。 |
model version repo required GPU RAM platforms ------- --------------------- ------- ------------------ ----------- qwen2.5 qwen2.5:0.5b default 12G linux qwen2.5:1.5b default 12G linux qwen2.5:3b default 12G linux qwen2.5:7b default 24G linux qwen2.5:14b default 80G linux qwen2.5:14b-ggml-q4 default macos qwen2.5:14b-ggml-q8 default macos qwen2.5:32b default 80G linux qwen2.5:32b-ggml-fp16 default macos qwen2.5:72b default 80Gx2 linux qwen2.5:72b-ggml-q4 default macos
硬件要求
Qwen2.5-32B(纯文本):
推荐:2×A100 80GB(FP16)或 4×A10 24GB(INT4 量化)
最低:单卡 A100 80GB(INT4)
Qwen2.5-VL-32B(多模态):
推荐:2×A100 80GB(FP16)或 4×A10 24GB(INT4)
需额外加载视觉编码器(如 ViT),显存需求略高
下面以 vLLM框架 为例,介绍在Docker中部署这两个模型的通用步骤。vLLM是一个高效的推理和服务框架。
1.安装依赖:确保系统已安装Docker、NVIDIA驱动和NVIDIA Container Toolkit(使Docker支持GPU)。
2.下载模型:推荐使用国内镜像源(如ModelScope)下载模型到本地目录。
# 示例:通过ModelScope下载Qwen2.5-32B-Instruct pip install modelscope modelscope download --model Qwen/Qwen2.5-32B-Instruct --local_dir /your/local/model/path
3.拉取Docker镜像:拉取官方vLLM镜像。
docker pull vllm/vllm-openai:latest
使用以下命令启动容器。请务必将命令中的 /your/local/model/path 和 Qwen2.5-32B-Instruct 替换为你实际部署的模型路径和名称(例如,部署VL模型时需替换为Qwen2.5-VL-32B-Instruct)。
docker run -d \ --gpus all \ -p 8000:8000 \ -v /your/local/model/path:/model \ # 将宿主机模型目录挂载到容器 --name vllm-qwen \ vllm/vllm-openai:latest \ --model /model \ # 容器内的模型路径 --served-model-name Qwen2.5-32B \ # 服务名称,可按需修改 --tensor-parallel-size 1 \ # 使用的GPU数量,单卡设为1 --gpu-memory-utilization 0.9 \ # GPU内存利用率,可调整以防OOM --max-model-len 8192 \ # 最大序列长度,可根据需要调整 --trust-remote-code # Qwen模型需要此参数
部署 Qwen2.5-VL-32B-Instruct
docker run -d \ --gpus all \ # 允许容器使用所有GPU -p 8000:8000 \ # 映射端口(主机端口:容器端口) -v /your/local/model/path:/model \ # 挂载模型目录到容器内 --name vllm-qwen-vl \ # 容器名称 vllm/vllm-openai:latest \ # 使用的镜像 --model /model \ # 容器内模型路径 外部调用时入参model 需要与此处相同 注意此处有 / --served-model-name Qwen2.5-VL-32B \ # 服务名称,可按需修改 --port 8000 \ # 容器内服务端口 --host 0.0.0.0 \ # 允许外部访问 --tensor-parallel-size 1 \ # 若单卡则设1,多卡按实际数量调整 --gpu-memory-utilization 0.9 \ # 允许使用90%的GPU内存(避免OOM) --trust-remote-code # 信任远程模型代码(Qwen模型需要)
关键参数说明:
--tensor-parallel-size:根据你使用的GPU数量设置。例如,单卡设为1,双卡可设为2。
--gpu-memory-utilization:控制显存使用率。如果启动时出现内存不足(OOM)错误,可以尝试降低此值(如调整为0.8)。
--max-model-len:根据模型支持的上下文长度和你的需求调整。
--dtype float16:模型运行的数据类型:float16 是半精度浮点类型,相比 float32 可减少 GPU 内存占用(约节省一半),同时保持较好的推理精度。Qwen2.5 模型支持 float16,推荐使用(若 GPU 支持 bfloat16,也可改为 bfloat16)。
服务启动后,可以通过以下方式验证模型是否正常工作:
1.检查服务状态:
curl http://localhost:8000/health
如果返回 {"status":"OK"} 或类似信息,说明服务已就绪。
2.发送推理请求进行测试:
Qwen2.5-32B (文本):直接向其 /v1/completions 或 /v1/chat/completions 端点发送文本Prompt。
1. 测试聊天接口(推荐)
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2.5-32B",
"messages": [
{"role": "user", "content": "你好,请介绍一下你自己。"}
],
"max_tokens": 100,
"temperature": 0.7
}'2. 测试流式输出(streaming)
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2.5-32B",
"messages": [{"role": "user", "content": "写一首关于春天的诗。"}],
"stream": true,
"max_tokens": 150
}'Qwen2.5-VL-32B (多模态):需要构建一个包含图像和文本的多模态请求。可以参考官方GitHub仓库中的示例代码。
1. Dockerfile(多模态)
# Dockerfile(多模态) FROM nvcr.io/nvidia/pytorch:24.06-py3 RUN pip install --upgrade pip && \ pip install "transformers>=4.40" "accelerate" "torch" "torchvision" \ "pillow" "fastapi" "uvicorn" "einops" "timm" "qwen-vl-utils" \ -i https://pypi.tuna.tsinghua.edu.cn/simple COPY app_vl.py /app/app.py WORKDIR /app EXPOSE 8000 CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from PIL import Image
import base64
import io
from transformers import AutoModelForVision2Seq, AutoTokenizer
app = FastAPI()
# 加载模型(启动时加载)
model = AutoModelForVision2Seq.from_pretrained(
"Qwen/Qwen2.5-VL-32B",
device_map="auto",
trust_remote_code=True,
torch_dtype="auto"
)
processor = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-VL-32B", trust_remote_code=True)
class VLRequest(BaseModel):
image_b64: str # Base64 编码的图片
question: str
@app.post("/vl")
async def vision_language(request: VLRequest):
try:
# 解码图片
image_data = base64.b64decode(request.image_b64)
image = Image.open(io.BytesIO(image_data)).convert("RGB")
# 构造消息
messages = [{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": request.question}
]
}]
# 预处理
inputs = processor(messages, return_tensors="pt", padding=True)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
# 生成
output = model.generate(**inputs, max_new_tokens=256)
response = processor.decode(output[0], skip_special_tokens=True)
return {"response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))docker build -t qwen25-vl-32b -f Dockerfile.vl . docker run -d --gpus all -p 8001:8000 qwen25-vl-32b
# 先将图片转为 base64
base64_image=$(base64 -i cat.jpg | tr -d '\n')
curl http://localhost:8001/vl \
-H "Content-Type: application/json" \
-d "{
\"image_b64\": \"$base64_image\",
\"question\": \"图片中有什么动物?\"
}"参考:
在使用 docker 时,常常会碰到进程退出时资源清理的问题,比如保证当前请求处理完成,再退出程序。
当执行 docker stop xxx 时,docker会向主进程(pid=1)发送 SIGTERM 信号
如果在一定时间(默认为10s)内进程没有退出,会进一步发送 SIGKILL 直接杀死程序,该信号既不能被捕捉也不能被忽略。
一般的web框架或者rpc框架都集成了 SIGTERM 信号处理程序, 一般不用担心优雅退出的问题。
但是如果你的容器内有多个程序(称为胖容器,一般不推荐),那么就需要做一些操作保证所有程序优雅退出。
信号是一种进程间通信机制,它给应用程序提供一种异步的软件中断,使应用程序有机会接受其他程序活终端发送的命令(即信号)。
应用程序收到信号后,有三种处理方式:忽略,默认,或捕捉。
常见信号:
| 信号名称 | 信号数 | 描述 | 默认操作 |
|---|---|---|---|
| SIGHUP | 1 | 当用户退出Linux登录时,前台进程组和后台有对终端输出的进程将会收到SIGHUP信号。对于与终端脱离关系的守护进程,这个信号用于通知它重新读取配置文件。 | 终止进程 |
| SIGINT | 2 | 程序终止(interrupt)信号,在用户键入 Ctrl+C 时发出。 | 终止进程 |
| SIGQUIT | 3 | 和SIGINT类似,但由QUIT字符(通常是Ctrl /)来控制。 | 终止进程并dump core |
| SIGFPE | 8 | 在发生致命的算术运算错误时发出。不仅包括浮点运算错误,还包括溢出及除数为0等其它所有的算术错误。 | 终止进程并dump core |
| SIGKILL | 9 | 用来立即结束程序的运行。本信号不能被阻塞,处理和忽略。 | 终止进程 |
| SIGALRM | 14 | 时钟定时信号,计算的是实际的时间或时钟时间。alarm 函数使用该信号。 | 终止进程 |
| SIGTERM | 15 | 通常用来要求程序自己正常退出;kill 命令缺省产生这个信号。 | 终止进程 |
下面以 supervisor 为例,Dockerfile 如下
1 | FROM centos:centos7 |
正常情况,容器退出时supervisor启动的其他程序并不会收到 SIGTERM 信号,导致子程序直接退出了。
这里使用 trap 对程序的异常处理进行包装
1 | trap <siginal handler> <signal 1> <signal 2> ... |
新建一个初始化脚本,init.sh
1 | #!/bin/sh |
修改 ENTRYPOINT 为如下
1 | ENTRYPOINT ["sh", "/root/init.sh"] |
最近在搞 torch 的工程化,基于 brpc 和 libtorch,将两者编译在一起的过程也是坑深,容下次再表。
为了简化部署,brpc 服务在 Docker 容器中运行。本地测试时功能一切正常,上到预发布环境时请求全部超时。
由于业务代码,brpc,docker环境,机房都是新的,在排查问题的过程中简直一头雾水。(当然根本原因还是水平不足)
发现请求超时后,开始用CURL测试接口,用真实数据验证发现请求都耗时1s,这和用c++的预期完全不符。
首先是怀疑业务代码有问题,逐行统计业务代码耗时,发现业务代码仅耗时10+ms。
用空数据访问接口,发现耗时也只有20+ms,这时开始怀疑brpc是不是编译得有问题,或者说和libtorch编译到一起不兼容。
这时我请教了一位同事,他对brpc比较熟悉,然后他说是curl实现的问题,和brpc没关系, 参考 brpc issue
1 | curl传输的时候,会设置 Expect: 100-continue, 这个协议brpc本身没有实现, 所以curl会等待一个超时。 |
所以这个1s超时是个烟雾弹,线上client是Python,不会有这个问题。
接着又是一通疯狂测试,各种角度体位测试。发现本机测试是ok的,透过lvs请求(跨机房)就会卡住直到超时,而且小body请求一切正常,大body请求卡住。
这时又开始怀疑brpc编译的不对,导致这个超时(brpc编译过程比较曲折,导致我不太有信心)。
于是我在这个服务器Docker中运行了另一个brpc服务,发现是一样的问题。
为了确认是否是brpc的问题,又写了个Python 的 echo server 进行测试,发现在docker中是一样的问题,但是不在docker中运行有一切正常。
这是时就可以确定,与代码无关,是docker或者lvs的问题,一度陷入僵局。
完全没思路,于是找来了运维的同学,这时运维提了一下,这个机房的mtu会小一点,于是一切串起来了。
马上测试,发现机房的mtu只有1450,而docker0网桥的默认mtu是1500,这就很能解释小body没问题,大body卡死。
1 | ~# netstat -i |
修改docker0的mtu,重启docker.service,一切问题都解决了。
1 | cat << EOF > /etc/docker/daemon.json |
这句话说得并不太懂,应该是“找到问题等于解决了90%”。
在互联网时代,找到了具体问题,在一通Google,基本等于解决了问题。你始终要确信,这个问题不应该只有你遇到。
在这个例子上,curl的误导大概花了一半的时间去定位。所以,定位问题首先得明确问题,如医生看病一样,确认问题发生的现象(卡住),位置(docker容器中)、程度(永久)、触发原因(大请求body)。
找专业人士寻求帮助是非常高效的,会大大缩短定位问题的时间,因为他们会运用经验和知识快速排除错误选项。
你所拥有的知识,并不是究竟的知识,也就是它所能应用的范围并不适应当前的场景,还有可能误导你。
你所缺失的知识,让你看不清前方正确的道路。
按我的知识,docker0是网桥,等价于交换机,除了性能问题,不应该导致丢包,就一直没往这个方向考虑(当然这块的知识也不扎实)。
MTU也不应该导致丢包,交换机应该会进行IP分片。
但忽略了一个点,虚拟的网桥并不是硬件网桥,可能并没有实现IP分片的逻辑(仅丢弃),又或者没有实现 PMTU(Path MTU Discovery)。
上面这点存疑,但更直接的原因是服务的IP包的 Don't fragment flag 为1,也就是禁止分片(为什么设置还不清楚)。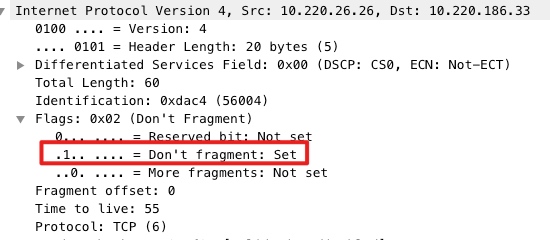
确认前置条件
在开始之前,请确保系统已经安装了NVIDIA GPU驱动程序(NVIDIA 驱动≥535.86.10,支持 CUDA 12.2+),并且可以正常运行 nvidia-smi 命令。同时,Docker Engine(版本建议 Docker 24.0+)也需要被安装好。
安装 NVIDIA Container Toolkit
具体的安装命令会根据操作系统有所不同。以下是一些常见系统的安装方法,可以参考 NVIDIA Docker 安装指南:
对于Ubuntu或Debian系统:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list apt-get update apt-get install -y nvidia-container-toolkit
对于CentOS或RHEL系统:
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repoyum clean expire-cacheyum install -y nvidia-container-toolkit
配置 Docker 运行时
安装完成后,需要配置Docker守护进程,使其默认使用NVIDIA Container Runtime。
nvidia-container-runtime --version
nvidia-ctk runtime configure --runtime=docker
systemctl restart docker
# 查看Docker Runtime配置
cat /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"runtimeArgs": [],
"path": "/usr/bin/nvidia-container-runtime"
}
},
"insecure-registries": [
"xxx:5000"
]
}配置完成后,必须验证GPU是否真的可以在Docker容器中使用了。
运行测试容器:
使用一个标准的CUDA镜像启动一个容器,并执行 nvidia-smi 命令。如果容器内能正常显示出GPU信息,就说明配置成功了。
docker run --rm --gpus all nvidia/cuda:12.0-base nvidia-smi
这个命令会启动一个临时容器,并执行 nvidia-smi。如果配置正确,将看到与在宿主机上直接运行 nvidia-smi 类似的GPU状态信息。
bge-m3/bge-reranker模型,TEI框架介绍参考 常用AI模型介绍及多模型组合使用场景。
通过 ModelScope 下载(推荐)
# 安装ModelScope工具 pip install modelscope # 创建模型存储目录 mkdir -p /data/models # 下载模型(国内源,速度快) modelscope download --model BAAI/bge-m3 --local_dir /data/models/bge-m3 modelscope download --model BAAI/bge-reranker-v2-m3 --local-dir /data/models/bge-reranker-v2-m3
通过 Hugging Face 国内镜像下载(备用)
# 安装huggingface-cli pip install huggingface-hub # 设置国内镜像(hf-mirror) export HF_ENDPOINT=https://hf-mirror.com # 下载模型 huggingface-cli download --resume-download BAAI/bge-m3 --local-dir /data/models/bge-m3 huggingface-cli download --resume-download BAAI/bge-reranker-v2-m3 --local-dir /data/models/bge-reranker-v2-m3
两个模型的核心部署命令对比:
| 特性 | BGE-M3 嵌入模型 | BGE-Reranker-V2-M3 重排序模型 |
|---|---|---|
| 核心功能 | 将文本转换为向量 | 对(query, document)对进行相关性打分 |
| 模型ID | BAAI/bge-m3 | BAAI/bge-reranker-v2-m3 |
| 常用端口 | 8080 | 8081 |
| 验证方式 | 调用 /embed 端点 | 调用 /rerank 端点 |
NVIDIA GPU卡对应的text-embeddings-inference镜像:
Architecture Image CPU ghcr.io/huggingface/text-embeddings-inference:cpu-1.6 Volta NOT SUPPORTED Turing (T4, RTX 2000 series, …) ghcr.io/huggingface/text-embeddings-inference:turing-1.6 (experimental) Ampere 80 (A100, A30) ghcr.io/huggingface/text-embeddings-inference:1.6 Ampere 86 (A10, A40, A4000, …) ghcr.io/huggingface/text-embeddings-inference:86-1.6 Ada Lovelace (RTX 4000 series, …) ghcr.io/huggingface/text-embeddings-inference:89-1.6 Hopper (H20, H100) ghcr.io/huggingface/text-embeddings-inference:hopper-1.6 (experimental)
1.部署 BGE-M3 嵌入模型
此命令会拉取本地镜像、加载本地模型并启动服务,使用NVIDIA L20卡部署。
docker run -d \ --name bge-m3 \ --runtime nvidia \ --gpus '"device=0"' \ --ipc=host \ -v /data/models/bge-m3:/mnt/models\ -p 8080:8080 \ --entrypoint=text-embeddings-router \ ghcr.io/huggingface/text-embeddings-inference:1.6 \ --model-id /mnt/models \ --port 8080 \ --max-batch-tokens 16384 \ --max-concurrent-requests 512 \ --max-client-batch-size 32
参数详细解释:
| 参数组 | 参数 | 解释说明 |
|---|---|---|
| Docker基础配置 | docker run -d | 启动一个新容器并在后台 (-d,即 detached 模式) 运行。 |
--name bge-m3 | 为容器指定一个名称 (bge-m3),便于后续通过名称进行管理(如查看日志、停止容器)。 | |
-p 8080:8080 | 端口映射,格式为 宿主机端口:容器内端口。此处将宿主机8080端口映射到容器内应用的8080端口,以便通过 http://主机IP:8080 访问服务。 | |
-v /data/models/bge-m3:/mnt/models | 数据卷挂载,将宿主机目录 /data/models/bge-m3 挂载到容器内的 /mnt/models 路径。容器内的应用可直接读取此处的模型文件。 | |
| GPU与运行时配置 | --runtime nvidia | 指定使用 NVIDIA 容器运行时,这是容器能够访问宿主GPU驱动的基础(需提前安装nvidia-container-toolkit)。 |
--gpus '"device=0"' | 精确指定容器可使用的GPU设备。"device=0" 表示仅使用系统中的第一块GPU(索引为0)。引号的嵌套是语法要求。 | |
--ipc=host | 让容器使用宿主机的进程间通信(IPC)命名空间。对于需要大量共享内存的GPU应用(如大模型推理),此配置能显著提升性能并避免内存问题。 | |
| 镜像与入口点 | --entrypoint=text-embeddings-router | 覆盖Docker镜像默认的启动命令,直接指定容器启动时运行 text-embeddings-router 这个程序。 |
ghcr.io/huggingface/text-embeddings-inference:1.6 | 指定要拉取和运行的Docker镜像地址及标签。这里是Hugging Face官方提供的文本嵌入推理服务,版本为 1.6。 | |
| 模型推理服务参数 | --model-id /mnt/models | 指定模型加载的路径。这里的 /mnt/models 对应上面 -v 参数挂载的目录,容器会从此路径读取模型文件。 |
--port 8080 | 指定容器内的推理服务监听在 8080 端口。此端口必须与 -p 参数中映射的容器侧端口一致。 | |
--max-batch-tokens 16384 | 限制单个批处理中所有文本的token总数上限。是控制显存消耗和批处理效率的核心参数。 | |
--max-concurrent-requests 512 | 设置服务的最大并发请求数。用于控制服务负载,超过此数量的新请求需要排队等待。 | |
--max-client-batch-size 32 | 限制单个客户端请求中最多能包含的文本数量(即批大小)。与max-batch-tokens共同作用。 |
2.部署 BGE-Reranker-V2-M3 重排序模型
docker run -d \ --name bge-reranker \ --runtime nvidia \ --gpus '"device=1"' \ --ipc=host \ -v /data/models/bge-reranker-v2-m3:/mnt/models\ -p 8081:8080 \ --entrypoint=text-embeddings-router \ ghcr.io/huggingface/text-embeddings-inference:1.6 \ --model-id /mnt/models \ --port 8080 \ --max-batch-tokens 16384 \ --max-concurrent-requests 512 \ --max-client-batch-size 32
执行 nvidia-smi 命令查看模型运行进程:

部署后,请按顺序验证服务状态。
1.检查容器状态
docker ps | grep -E "bge-m3|bge-reranker"
确认两个容器的状态(STATUS)均为 Up。
2.查看容器日志
# 查看BGE-M3日志 docker logs bge-m3 --tail 50 # 查看BGE-Reranker日志 docker logs bge-reranker --tail 50
关注日志末尾,确认出现类似 "Server started on 0.0.0.0:8080" 、"Ready"的成功信息,并且没有显存的报错。
3.发送测试请求
curl -X POST "http://localhost:8080/embed" \
-H "Content-Type: application/json" \
-d '{"inputs": "Hello, world!"}'
# 预期结果:
[[-0.015909059,0.026837891,...,-0.03666923,0.0015528625]]text-embeddings-inference 服务的 /rerank 端点通常期望一个包含query和texts列表的JSON。成功会返回一个相关性分数列表。
curl -X POST "http://localhost:8081/rerank" \
-H 'Content-Type: application/json' \
-d '{"query":"What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."], "raw_scores": false}'
# 预期结果:
[{"index":1,"score":0.9976404},{"index":0,"score":0.12527926}]1.CUDA计算能力兼容性错误
docker run 启动模型容器报错:ERROR text_embeddings_backend: backends/src/lib.rs:388: Could not start Candle backend: Could not start backend: Runtime compute cap 89 is not compatible with compile time compute cap 90
这是问题原因是CUDA计算能力(90)与目前部署的GPU的实际计算能力(89)不匹配。确认使用的GPU具体型号和计算能力:
nvidia-smi --query-gpu=name,compute_cap --format=csv
常见计算能力对应表:详见 CUDA GPU 计算能力
| 计算能力 | GPU架构 | 典型GPU型号 |
|---|---|---|
| 9.0 | Hopper | NVIDIA H20,H100,H200 |
| 8.9 | Ada Lovelace | RTX 40系列 |
| 8.6 | Ampere | A100, A30, RTX 30系列 |
| 7.5 | Turing | RTX 20系列, T4 |
| 6.1 | Pascal | P100, GTX 10系列 |
解决方案:替换适配NVIDIA L20卡的镜像,Nvidia L20使用 ghcr.io/huggingface/text-embeddings-inference:1.6 镜像,H20使用 text-embeddings-inference:hopper-1.6 镜像
参考:
Bensz
Docker系列 WordPress系列 m2w 2.6:博客管理的重要转折点
本博客由AI模型商OhMyGPT强力驱动!如何更快地访问本站?有需要可加电报群获得更多帮助。本博客用什么VPS?创作不易,请支持苯苯!推荐购买本博客的VIP喔,10元/年即可畅享所有VIP专属内容! 概览 本文围绕 前言 展开详细讨论 包含 13 个主要章节内容 分享实践经验和实用技巧 前言 前文回顾:Docker系列 WordPress系列 WordPress上传或更新Markdown的最佳实践-m2w 2 使用2.5版本的小伙伴,升级时记得改为2.6版本的 myblog.py。内容大体上是相似的,但有一丁点区别。还是直接换掉保险 (~ ̄▽ ̄)~ 有什么问题加tg群问哈 小伙伴们都还记得之前我们介绍过的 m2w 吗?就是那个可以将本地 Markdown 文件自动上传或更新到 WordPress 的神奇工具!时隔不久,m2w 迎来了 2.6 版本,这个版本可不是小修小补,而是带来了许多重要 […]



