CSS六边形头像的实现与蜂巢布局
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12118
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
本文内容分为两啪,一个是六边形头像效果的实现,而是金字塔布局(又称蜂巢布局)的实现。
一、六边形头像
不啰嗦,直接看代码和最终实现的效果,同样的,用的是CSS corner-shape属性。
img {
aspect-ratio: cos(30deg);
border-radius: 50% / 25%;
corner-shape: bevel;
width: 150px;
border: 1px solid #0001;
object-fit: cover;
}
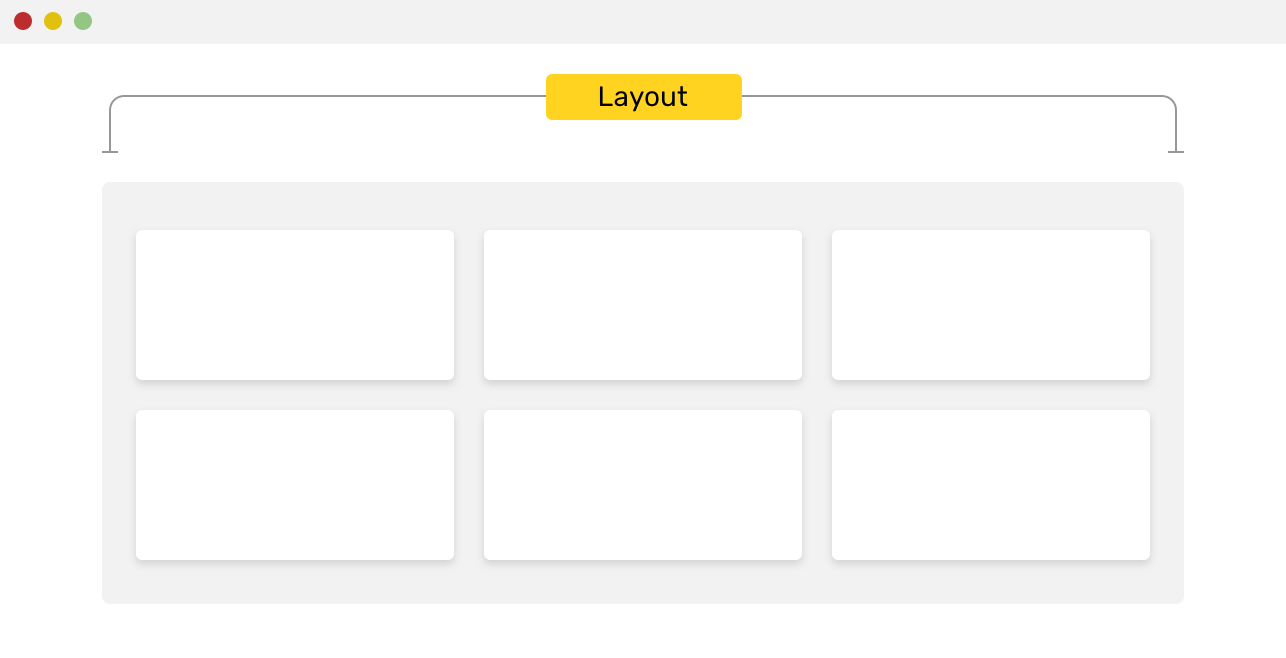
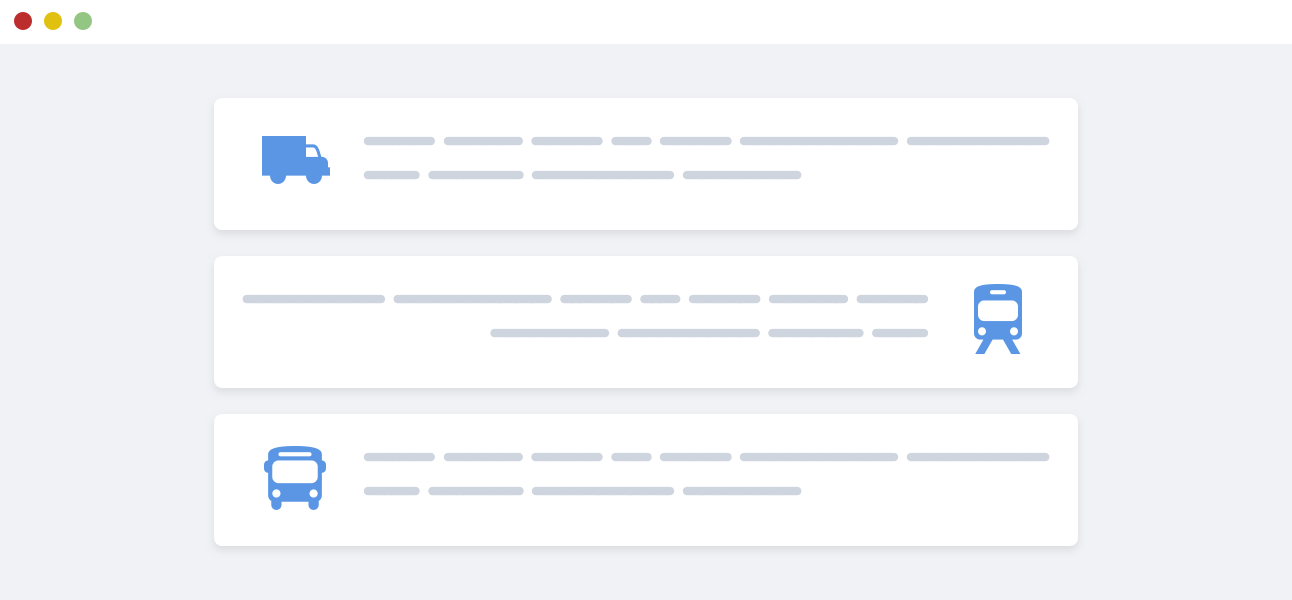
实时渲染效果如下:

如果你是手机访问,或者一些很久没升级的国产浏览器,应当看不到效果,可以看下面的截图:

六边形头像的CSS代码是固定的,大家使用的时候直接复制粘贴就好了。
二、蜂窝布局实现方法
六边形也正好是蜂巢格子的形状,因此,非常适合用来实现金字塔一样的蜂窝布局。
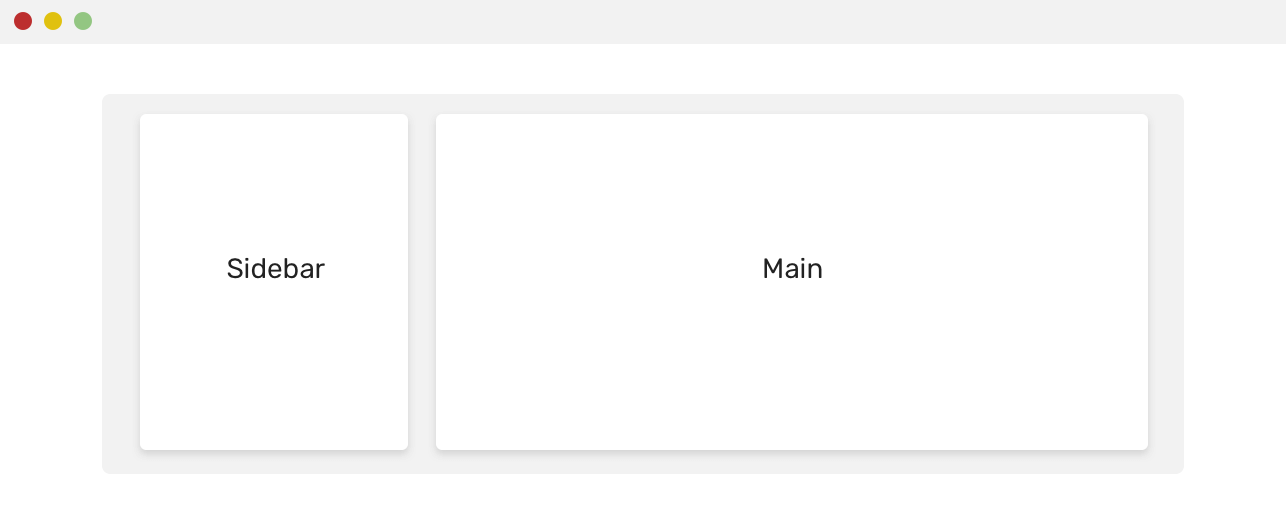
实际上,这种布局在日常开发中也是比较常见的,例如我最近开发的某个页面就有这样的布局:
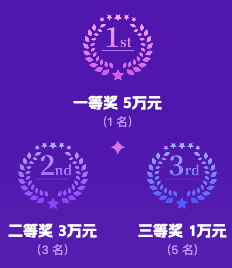
一般的开发人员遇到这种状况,可能会手工硬搓每个元素的定位,例如,例如匹配第一项元素,让其绝对定位居中,第二行元素保持Flex布局。
.item:first-child {
/* 第一行特殊居中处理 */
position: absolute;
}
其实可以试试Flex倒序排版。
Flex实现蜂窝布局
假设HTML结构如下:
<div class="container"> <span>1</span> <span>2</span> <span>3</span> </div>
则可以试试如下所示的CSS:
.container {
--size: 40px;
--gap: 5px;
--offset: calc((2 * var(--size) + var(--gap)) / (-4 * cos(30deg)));
width: 240px;
display: flex;
flex-wrap: wrap-reverse;
direction: rtl;
justify-content: center;
gap: var(--gap);
padding-bottom: calc(-1 * var(--offset));
}
.container > span {
aspect-ratio: cos(30deg);
border-radius: 50% / 25%;
corner-shape: bevel;
width: calc(var(--size) * 2);
margin-bottom: var(--offset);
/* 排序倒序 */
order: calc(-1 * sibling-index());
/* 提示文字居中 */
display: grid;
place-items: center;
background-color: deepskyblue;
color: #fff;
}
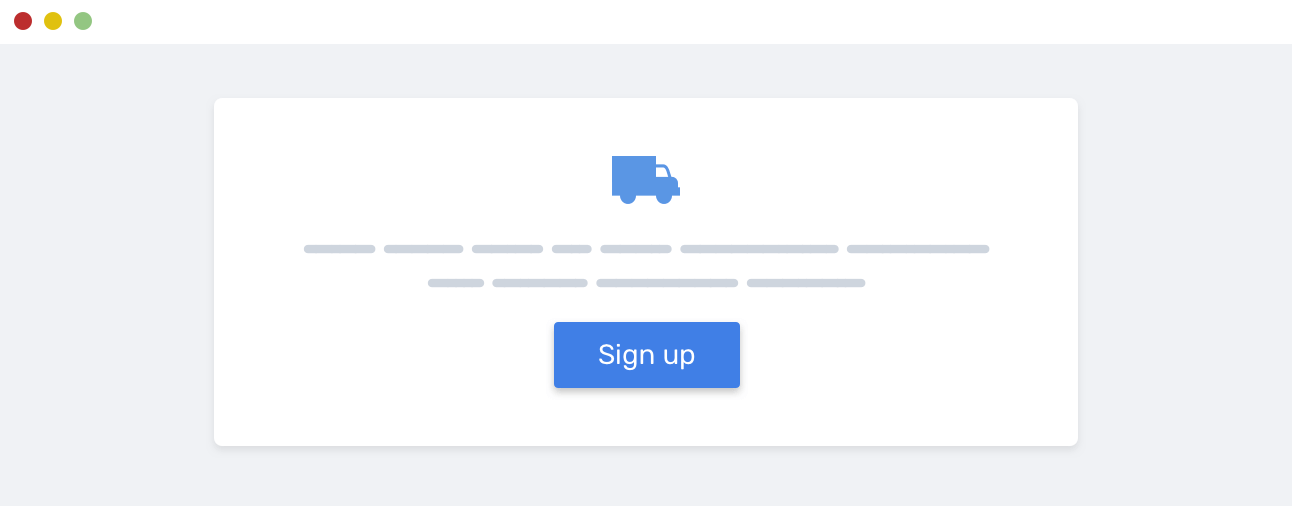
此时的渲染效果如下截图所示:
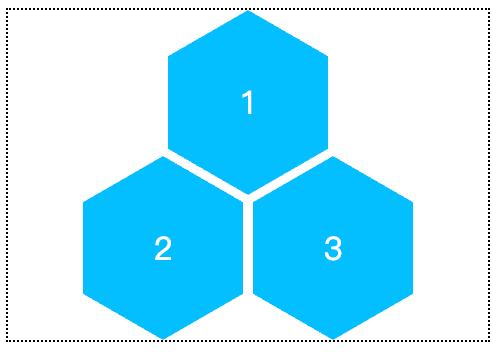
不过Flex倒序只适合三个数量,如果超过,那么这个布局方法就无效了。
下面问题来了,有没有什么办法,无论列表数量多少,自动金字塔布局呢?
Grid实现蜂巢布局
有,Grid布局是可以实现这样的效果的。
我们先从最简单三个列表项开始实现,假设HTML代码如下:
<div class="container"> <s></s> <s></s> <s></s> </div>
如下CSS代码就可以有蜂窝布局效果了:
.container {
--size: 40px;
--gap: 5px;
width: 240px;
display: grid;
grid-template-columns: repeat(auto-fit, var(--size));
justify-content: center;
gap: var(--gap);
padding-bottom: calc((2 * var(--size) + var(--gap)) / (4 * cos(30deg)));
outline: 1px dotted;
}
.container > s {
grid-column-end: span 2;
aspect-ratio: cos(30deg);
border-radius: 50% / 25%;
corner-shape: bevel;
/* 垂直方向间隙和gap保持一致 */
margin-bottom: calc((2 * var(--size) + var(--gap)) / (-4 * cos(30deg)));
background-color: deepskyblue;
}
.container > :nth-child(1) {
grid-column-start: 3;
}
.container > :nth-child(2) {
grid-column-start: 2;
}
原理很简单,只需要精确指定每一行第一个元素的grid-column-start值就好了,在Grid布局中,每一行后面的元素只会自动跟随排列的。
如果是三个列表元素,那么第一行的首元素序列是1,因此选择器是:nth-child(1),第二行的首元素序列是2,因此选择器是:nth-child(2),最后一个元素自动跟随,无需专门设置。
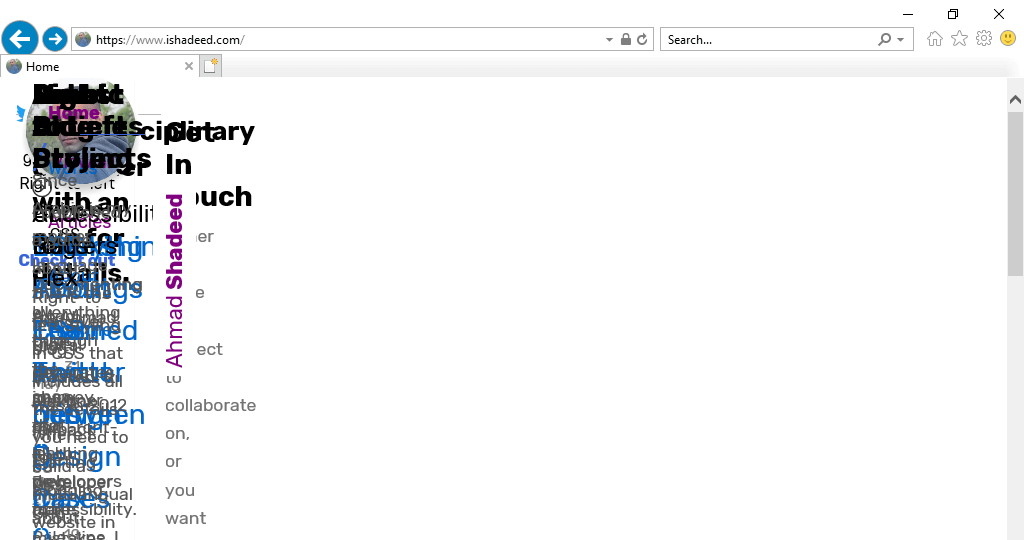
实时渲染效果如下:
不限数量全自动蜂巢布局
由于Chrome浏览器支持了if函数,因此,纯CSS实现不限数量全自动蜂巢布局成为了可能,具体实现代码如下:
@property --_n {syntax: "<integer>";initial-value: 1;inherits: true}
@property --_i {syntax: "<number>";initial-value: 1;inherits: true}
@property --_j {syntax: "<number>";initial-value: 1;inherits: true}
@property --_c {syntax: "<number>";initial-value: 1;inherits: true}
@property --_d {syntax: "<number>";initial-value: 1;inherits: true}
.container {
--s: 40px; /* 尺寸大小 */
--g: 5px; /* 间隙大小 */
display: grid;
grid-template-columns: repeat(auto-fit, var(--s) var(--s));
justify-content: center;
gap: var(--g);
padding-bottom: calc((2 * var(--s) + var(--g)) / (4 * cos(30deg)));
container-type: inline-size;
}
.container > * {
grid-column-end: span 2;
aspect-ratio: cos(30deg);
border-radius: 50% / 25%;
corner-shape: bevel;
margin-bottom: calc((2 * var(--s) + var(--g)) / (-4 * cos(30deg)));
--_n: round(down, (100cqw + var(--g)) / (2 * (var(--s) + var(--g))));
--_i: calc((sibling-index() - 2 + (var(--_n) * (3 - var(--_n))) / 2) / (2 * var(--_n) - 1));
--_c: mod(var(--_i), 1);
--_j: calc(sqrt(2 * sibling-index() - 1.75) - .5);
--_d: mod(var(--_j), 1);
grid-column-start:
if(
style((--_i >= 1) and (--_c: 0)): 2;
style(--_d: 0): max(0, var(--_n) - var(--_j));
);
}
先是根据容器尺寸和元素尺寸计算每行可以显示的数量,然后根据取模的值是不是整数,判断是不是每一行的第一项,通过if()函数设置精准的grid-column-start值。
原理虽然简单,但是实现细节还是很复杂的,比如大家无需深究,直接复制粘贴代码使用就可以了。
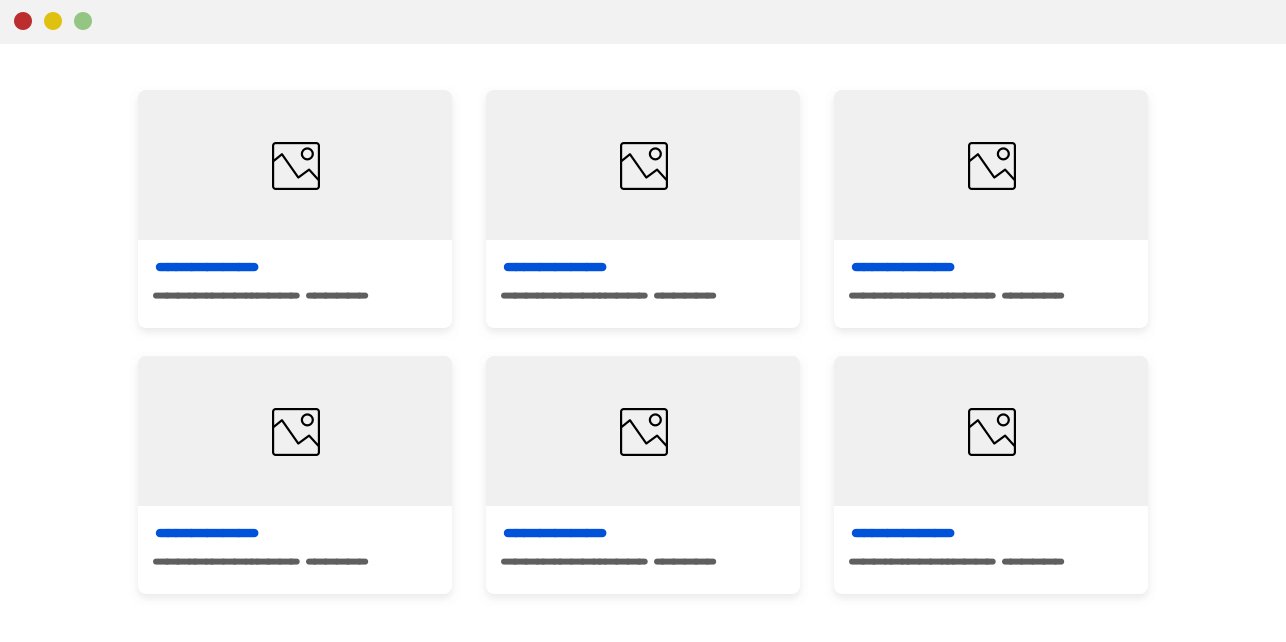
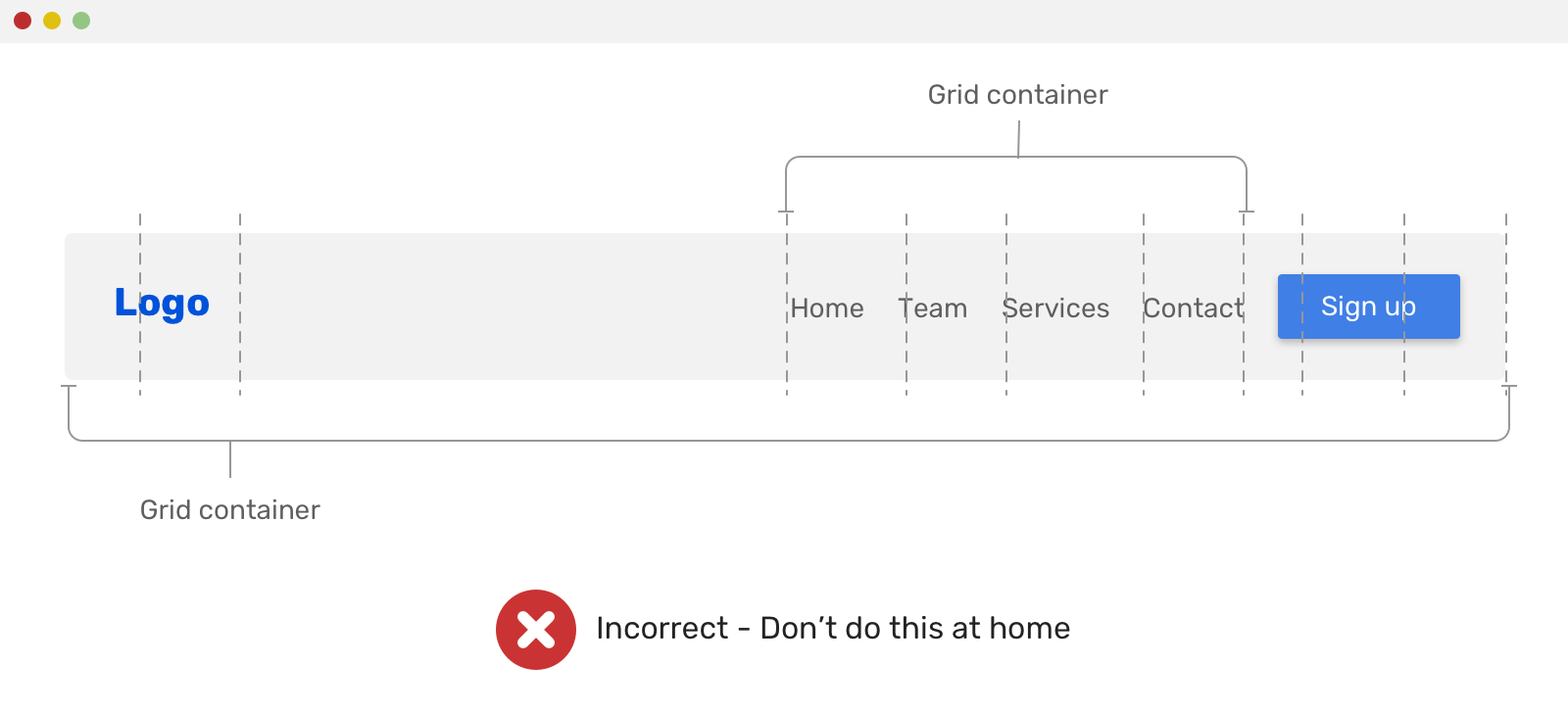
只需要将子元素换成图片元素,就可以轻松实现下图所示的蜂巢头像布局效果。

具体不展开,因为受制于兼容性限制,目前只能实验环境使用。
三、结语说明
前端三剑客中,CSS的发展是最快的,你看我写的新特性介绍文章,大多数都是CSS,并不是我刻意挑选,而真TM就是大多数前端新特性都是CSS。
考虑到CSS的学习热潮早就沉寂多年。
我觉得CSS这门语言离断层不远了,只要几年不关注,我跟大家讲,那些前沿的CSS代码,绝对是看不懂的。
各种新函数、属性还有语法糖层出不穷,就好比本文这个金字塔蜂巢布局中的CSS实现细节,我估计9成以上的前端是看不懂什么意思的。
其中出现的这些特性,我之前都有介绍:
corner-shape见此文:大开眼界的CSS corner-shape属性aspect-ratio见此文:Chrome 88已经支持aspect-ratio属性了,学起来round()、mod()等数学函数:Chrome也支持round等CSS数学函数了cos()三角函数见:CSS sin()/cos()等数学三角函数简介与应用sibling-index()索引序号函数介绍出处:CSS索引和数量匹配函数sibling-index sibling-count简介if()函数介绍:CSS倒反天罡居然支持if()函数了container-type和100cqw属于容器查询里面的知识:2022年最期待的CSS container容器查询
所以还是那句话,学习是不能停止的,时代变化很快,要是安于现状,说不定就会掉队。
参考文章:响应式金字塔网格
😉😊😇
🥰😍😘
本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12118
(本篇完)