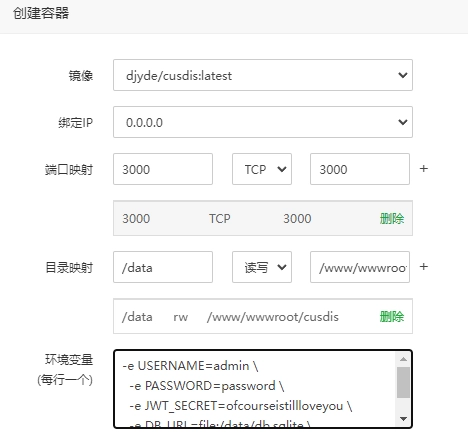
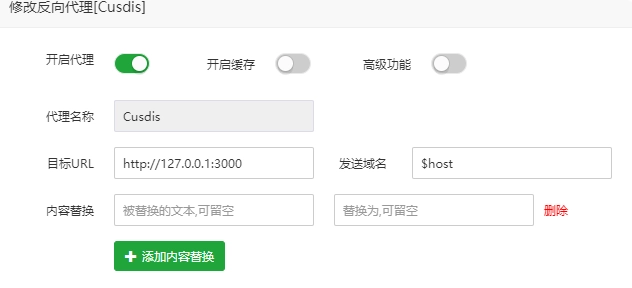
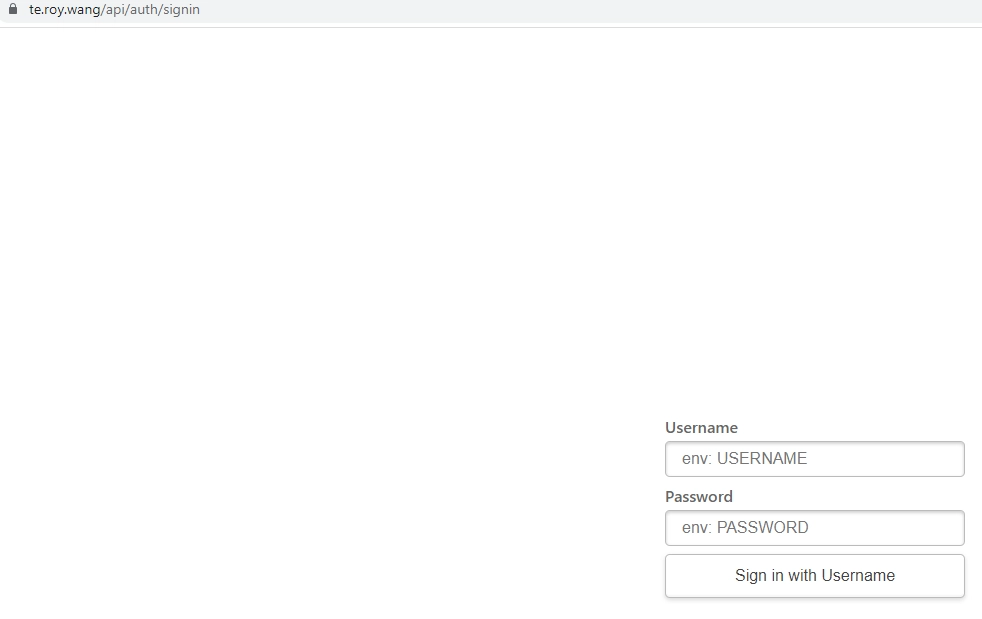
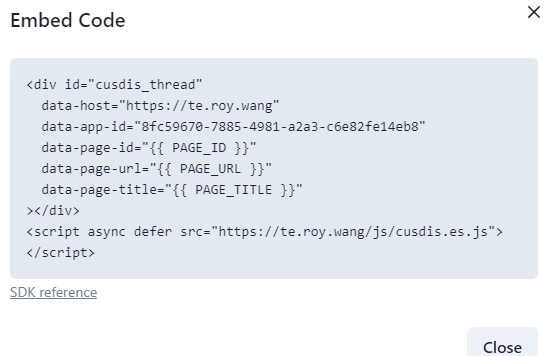
AI 创作声明:本系列文章由笔者借助 ChatGPT, Kimi K2, 豆包和 Cursor 等 AI 工具创作,有很大篇幅的内容完全由 AI 在我的指导下生成。如有错误,还请指正。
前言
本文将简要介绍 Linux 桌面系统的启动机制,从 UEFI 引导到内核加载,从 initramfs 到 systemd
服务启动,再到桌面环境加载。同时还会探讨系统的安全框架,了解 PAM、PolicyKit 等组件如何保护系统安全。
1. 系统启动流程
启动的四个关键阶段
Linux 桌面系统的启动过程可以分为以下几个主要阶段:
- 固件阶段:UEFI 固件初始化硬件
- 引导加载器阶段:加载内核和 initramfs
- 内核阶段:硬件探测和驱动加载
- initramfs 阶段:准备根文件系统
- 用户空间阶段:systemd 接管系统管理
UEFI:系统启动的起点
现代系统普遍使用 UEFI 固件 代替 BIOS。UEFI 初始化硬件后,从 EFI System Partition (ESP)
中加载启动管理器。
NixOS 在 UEFI 系统上支持多种引导加载器。默认使用 GRUB;启用 Secure Boot 时通常使用systemd-boot
配合 lanzaboote。
systemd-boot 的全局配置是 /boot/loader/loader.conf,具体的启动项配置需要分类讨论:
常用命令:
efibootmgr -v:查看 / 修改固件启动顺序bootctl status:检查 systemd-boot 安装与 ESP 状态bootctl list:列出启动条目ukify inspect /boot/EFI/Linux/nixos-xxx.efi: 查看 efi 镜像中包含的信息
示例:
# 查看固件启动顺序
$ nix run nixpkgs#efibootmgr -v
BootCurrent: 0000
Timeout: 0 seconds
BootOrder: 0000,0004
Boot0000* NixOS HD(1,GPT,34286f3b-d4df-456d-bf7a-eb67f2bf1a72,0x1000,0x12b000)/EFI\BOOT\BOOTX64.EFI
...
Boot0004* Windows Boot Manager HD(1,GPT,34286f3b-d4df-456d-bf7a-eb67f2bf1a72,0x1000,0x12b000)/\EFI\Microsoft\Boot\bootmgfw.efi0000424f
# 检查 systemd-boot 安装与 ESP 状态
$ bootctl status
System:
Firmware: UEFI 2.80 (American Megatrends 5.27)
Firmware Arch: x64
Secure Boot: enabled (user)
TPM2 Support: yes
Measured UKI: yes
Boot into FW: supported
Current Boot Loader:
Product: systemd-boot 257.7
Features: ✓ Boot counting
✓ Menu timeout control
✓ One-shot menu timeout control
✓ Default entry control
✓ One-shot entry control
✓ Support for XBOOTLDR partition
✓ Support for passing random seed to OS
✓ Load drop-in drivers
✓ Support Type #1 sort-key field
✓ Support @saved pseudo-entry
✓ Support Type #1 devicetree field
✓ Enroll SecureBoot keys
✓ Retain SHIM protocols
✓ Menu can be disabled
✓ Multi-Profile UKIs are supported
✓ Boot loader set partition information
Partition: /dev/disk/by-partuuid/34286f3b-d4df-456d-bf7a-eb67f2bf1a72
Loader: └─EFI/BOOT/BOOTX64.EFI
Current Entry: nixos-generation-848-jattq2uvv2snrigcxtdcxelgaawdb3s6lar3ualze77id46h5adq.efi
...
Available Boot Loaders on ESP:
ESP: /boot (/dev/disk/by-partuuid/34286f3b-d4df-456d-bf7a-eb67f2bf1a72)
File: ├─/EFI/systemd/systemd-bootx64.efi (systemd-boot 257.7)
└─/EFI/BOOT/BOOTX64.EFI (systemd-boot 257.7)
...
Default Boot Loader Entry:
type: Boot Loader Specification Type #2 (.efi)
title: NixOS Xantusia 25.11.20250830.d7600c7 (Linux 6.16.4) (Generation 848, 2025-09-01)
id: nixos-generation-848-jattq2uvv2snrigcxtdcxelgaawdb3s6lar3ualze77id46h5adq.efi
source: /boot//EFI/Linux/nixos-generation-848-jattq2uvv2snrigcxtdcxelgaawdb3s6lar3ualze77id46h5adq.efi (on the EFI System Partition)
sort-key: lanza
version: Generation 848, 2025-09-01
linux: /boot//EFI/Linux/nixos-generation-848-jattq2uvv2snrigcxtdcxelgaawdb3s6lar3ualze77id46h5adq.efi
options: init=/nix/store/gaj3sp3hrzjhp59bvyxhc8flg5s6iimg-nixos-system-ai-25.11.20250830.d7600c7/init nvidia-drm.fbdev=1 root=fstab loglevel=4 lsm=landlock,yama,bpf nvidia-drm.modeset=1 nvidia-drm.fbdev=1 nvidia.NVreg_PreserveVideoMemoryAllocations=1 nvidia.NVreg_OpenRmEnableUnsupportedGpus=1
# 查看上述启动项中 uki efi 文件的内容
$ nix shell nixpkgs#systemdUkify
$ ukify inspect /boot/EFI/Linux/nixos-generation-848-jattq2uvv2snrigcxtdcxelgaawdb3s6lar3ualze77id46h5adq.efi
.osrel:
size: 141 bytes
sha256: e486dea4910eb9262efc47464f533f96093293d37c3d25feb954c098865a4be6
text:
ID=lanza
PRETTY_NAME=NixOS Xantusia 25.11.20250830.d7600c7 (Linux 6.16.4) (Generation 848, 2025-09-01)
VERSION_ID=Generation 848, 2025-09-01
# 启动内核时使用的内核命令行参数
.cmdline:
size: 284 bytes
sha256: 7f94ffed08359eb1d2749176eba57e085113f46208702a8c0251376d734f19ce
text:
init=/nix/store/gaj3sp3hrzjhp59bvyxhc8flg5s6iimg-nixos-system-ai-25.11.20250830.d7600c7/init nvidia-drm.fbdev=1 root=fstab loglevel=4 lsm=landlock,yama,bpf nvidia-drm.modeset=1 nvidia-drm.fbdev=1 nvidia.NVreg_PreserveVideoMemoryAllocations=1 nvidia.NVreg_OpenRmEnableUnsupportedGpus=1
# initramfs 内容的引用,实际镜像位于 ESP 的 /EFI/nixos/initrd-*.efi
.initrd:
size: 81 bytes
sha256: 26d9b1f52806c48c6287272cb26b8a640b62d55f09149abf3415c76c38e0b56e
# 内核映像(vmlinuz)的引用,实际镜像位于 ESP 的 /EFI/nixos/kernel-*.efi
.linux:
size: 81 bytes
sha256: 41ff83e4cae160fb9ce55392943e6d06dbf9f37b710bf719f7fe2c28ec312be5
内核启动后,会探测 CPU、内存、PCI、USB、ACPI 等硬件,加载关键驱动,然后挂载 initramfs 并执行 option 中指定的 init 程序。
观察方法:
# 查看内核早期日志
sudo dmesg --level=err,warn,info | less
# 查看本次启动的完整日志
journalctl -b
initramfs 阶段
initramfs(Initial RAM File System)是一个临时的根文件系统,在真正的根文件系统挂载之前提供必要的功能。它在启动阶段被加载到 RAM 中并被挂载为根目录。
initramfs 阶段的主要职责:
-
硬件检测与驱动加载:
- 检测存储设备(SATA、NVMe、USB 等)
- 加载必要的存储驱动模块
- 识别网络设备(如果需要网络启动)
-
存储设备准备:
- 解密 LUKS 加密分区
- 激活 LVM 逻辑卷
- 处理 RAID 阵列
- 挂载临时文件系统
-
根文件系统挂载:
- 根据内核参数
root= 找到根分区
- 挂载根文件系统到
/new_root
- 执行
switch_root 切换到真正的根文件系统
-
启动用户空间:
- 执行
/sbin/init(通常是 systemd)
- 在 NixOS 中,init 程序是
/nix/store 中的一个 Shell 脚本,它首先完成一些必要的初始化工作,之后才启动 systemd.
常见故障与排查:
- 找不到根分区:检查
cat /proc/cmdline 的 root= 参数与 blkid 输出是否一致
- 缺少驱动模块:确保 NixOS 配置包含所需模块:
boot.initrd.kernelModules = [ "nvme" "dm_mod" ];
- LUKS 解密失败:检查密码输入或密钥文件配置
- LVM 激活失败:确认 LVM 配置和卷组状态
排查步骤:
- 编辑内核 cmdline,添加
init=/bin/sh 或 break=mount 进入 initramfs shell
- 运行
lsblk、blkid 确认设备
- 查看
dmesg 中的磁盘或 LVM 错误
- 检查
/proc/cmdline 中的启动参数
2. 启动故障排查
启动故障排查流程
flowchart LR
A[系统无法启动] --> B{能否进入 UEFI/BIOS?}
B -->|否| C[硬件问题
检查电源、内存、CPU]
B -->|是| D{能否看到启动菜单?}
D -->|否| E[引导加载器问题
检查 ESP 分区和启动项]
D -->|是| F{能否选择启动项?}
F -->|否| G[启动项配置错误
检查 bootctl 配置]
F -->|是| H{内核能否加载?}
H -->|否| I[内核或 initramfs 问题
检查内核参数和驱动]
H -->|是| J{能否进入 initramfs?}
J -->|否| K[initramfs 问题
检查根分区和文件系统]
J -->|是| L{能否挂载根分区?}
L -->|否| M[文件系统或加密问题
检查 LUKS 和 LVM]
L -->|是| N{systemd 能否启动?}
N -->|否| O[用户空间问题
检查 systemd 服务]
N -->|是| P[启动成功]
常见启动问题:症状与解决方案
在系统启动过程中,可能会遇到各种问题。以下是按启动阶段分类的常见问题及排查方法:
2.2.1 固件和引导加载器问题
问题症状:
- 系统无法启动,停留在固件界面
- 显示 “No bootable device” 错误
- 启动菜单不显示或显示异常
排查步骤:
使用 USB 启动盘进入 LiveOS, 进行如下检查:
# 检查 UEFI 设置
efibootmgr -v
# 检查 ESP 分区状态
bootctl status
# 验证启动项配置
bootctl list
2.2.2 内核和 initramfs 问题
问题症状:
- 内核 panic 或无法加载
- initramfs 阶段卡住
- 找不到根分区
排查步骤:
# 进入 initramfs shell 进行调试
# 在内核参数中添加:init=/bin/sh 或 break=mount
# 检查设备识别
lsblk
blkid
# 查看内核日志
dmesg | grep -i error
# 检查文件系统完整性
fsck /dev/sdX
启动性能优化
2.3.1 启动时间分析
# 使用 systemd-analyze 分析启动时间
systemd-analyze
systemd-analyze blame
systemd-analyze critical-chain
# 生成启动时间报告
systemd-analyze plot > boot-time.svg
这些工具可以帮助你分析系统启动性能:
systemd-analyze 显示总启动时间,包括内核和用户空间的启动耗时systemd-analyze blame 按耗时排序显示各服务启动时间,找出最耗时的服务systemd-analyze critical-chain 显示关键路径分析,找出阻塞启动的服务链systemd-analyze plot 生成启动时间图表,可视化各服务的启动顺序和耗时
识别到启动阶段的性能瓶颈后,就能据此优化服务依赖关系,加快启动速度。
2.3.2 启动优化策略
优化启动速度可以从多个层面入手:
硬件层面
使用 SSD 存储是最直接有效的优化方法。固态硬盘的随机读写性能远超机械硬盘,能显著减少文件系统访问延迟。启动时间通常可减少 50-80%,特别是对于大量小文件读取的场景。适用于所有系统,特别是启动时间较长的系统。
内核层面
启用内核并行初始化可以提升启动速度。现代内核支持并行初始化硬件设备,减少串行等待时间。通过内核参数如 initcall_debug 和 acpi=noirq 等可以优化启动流程,减少硬件初始化时间。
服务层面
优化 systemd 服务依赖关系可以减少启动延迟。减少不必要的服务依赖,避免串行启动造成的延迟。使用 systemctl list-dependencies 分析依赖关系,移除不必要的依赖,减少服务启动等待时间,
提升并行启动效率。
启动流程
使用 UKI(统一内核镜像)可以减少启动步骤。将内核、initramfs、cmdline 打包成单个 EFI 文件,
减少启动步骤和文件系统访问。减少文件系统挂载次数,简化启动流程。在 NixOS 中通过boot.loader.systemd-boot.enable 和 boot.loader.efi.canTouchEfiVariables 启用。
3. 系统安全框架:认证、授权与密钥管理
现代 Linux 桌面系统的安全架构由多个相互协作的组件构成,包括 PAM(认证)、PolicyKit(授权)、以及桌面环境提供的密钥管理服务。这些组件共同构建了一个多层次的安全防护体系,既保证了系统的安全性,又提供了良好的用户体验。
NOTE: 注意 PAM 与 PolicyKit 的设计目的都是为普通用户提供权限提升手段。对 root 用户而言,这些框架的限制很少或几乎不存在。如果你希望限制整个系统全局的权限(包括 root 用户),
应该考虑 SELinux/AppArmor 等强制访问控制框架。
3.1 PAM - 可插拔认证模块
PAM(Pluggable Authentication Modules) 是 Linux 的统一认证框架,为系统中的各种程序
(如 login、sudo、sshd、gdm 等)提供标准化的认证接口。借助 PAM,系统管理员可以通过配置文件灵活控制认证策略,而无需修改应用程序本身。它支持多种认证方式(密码、指纹、智能卡、双因子验证等),是现代 Linux 安全体系的核心组件之一。
3.1.1 工作原理与配置结构
PAM 采用模块化设计,将认证流程分为四个阶段。应用程序通过调用相应的 PAM 接口触发这些阶段,
系统根据 /etc/pam.d/ 下的配置文件执行相应的模块(.so 文件)。
(1)配置文件语法
https://linux.die.net/man/5/pam.d
每行的基本格式如下:
<type> <control> <module> [arguments]
- type:表示阶段类型
- control:定义该模块的执行策略
- module:具体的 PAM 模块路径(或名称)
- arguments:传递给模块的参数
(2)四个认证阶段
| 阶段类型 |
调用函数 |
主要作用 |
auth |
pam_authenticate() |
验证用户身份,通常会提示用户输出密码或指纹以完成验证 |
account |
pam_acct_mgmt() |
检查账户状态(过期、锁定等) |
password |
pam_chauthtok() |
处理密码修改 |
session |
pam_open_session() / pam_close_session() |
建立和清理用户会话 |
(3)控制标志(control)
| 标志 |
含义 |
行为说明 |
required |
必须成功,失败不会立即终止,但最终结果会失败 |
无论成功失败,都会继续执行后续模块。最终只要有一个 required 失败,整个认证就失败。 |
requisite |
必须成功,失败立即终止并返回失败 |
失败立即返回,不再执行后续模块。 |
sufficient |
成功则立即通过认证(跳过所有后续模块);失败则继续由后续模块进行认证 |
若前面没有 required 失败,则成功直接通过;否则失败不影响后续。 |
optional |
可选模块,结果通常被忽略 |
无论成功失败,对最终结果无直接影响,除非是栈中唯一的模块。 |
include |
包含另一个文件的配置 |
将指定文件的配置内容包含进来,通常用于复用通用配置(如 system-auth)。 |
substack |
调用子栈 |
类似 include,但子栈的失败不影响主栈(即子栈只能跳过其自身的后续步骤),除非主栈中另有设置。 |
(4)常用模块示例
pam_unix.so # 基于 /etc/passwd 与 /etc/shadow 的标准密码认证
pam_google_authenticator.so # 双因子认证(TOTP)
pam_fprintd.so # 指纹认证
pam_ldap.so # LDAP 集中式认证
pam_gnome_keyring.so # GNOME 密钥环集成
pam_limits.so # 用户资源限制
pam_deny.so # 拒绝所有认证请求
3.1.2 执行流程示例
以 /etc/pam.d/sudo 为例:
#%PAM-1.0
auth sufficient pam_rootok.so
auth sufficient pam_timestamp.so
auth required pam_wheel.so use_uid
auth required pam_unix.so nullok try_first_pass
各模块的执行顺序如下:
- 执行
pam_rootok.so (sufficient):
- 检查当前用户是否为 root。
- 如果成功:PAM 认证流程立即成功,并跳过后续所有
auth 模块。用户直接获得
sudo 权限。
- 如果失败:继续执行下一个模块。
- 执行
pam_timestamp.so (sufficient):
- 检查是否存在有效的时间戳文件(默认为 5 分钟内)。
- 如果成功:PAM 认证流程立即成功,并跳过后续所有
auth 模块。用户免密码获得 sudo 权限。
- 如果失败:继续执行下一个模块。
- 执行
pam_wheel.so (required):
- 检查当前用户是否在
wheel 组(或 sudo 组,取决于配置)中。
- 无论成功还是失败,都必须继续执行下一个
required 模块。但其结果会被记录下来。
- 执行
pam_unix.so (required):
- 使用
nullok 和 try_first_pass 参数进行密码验证。
nullok:允许空密码账户登录。try_first_pass:尝试使用前面模块(如果有的话)提供的密码。对于 sudo,这通常指之前 sudo 成功时缓存的密码。- 如果密码正确:此模块成功。
- 如果密码错误:此模块失败。
- 最终结果判定:
- 在所有
required 模块执行完毕后,PAM 会检查它们的结果。
- 如果任何一个
required 模块(pam_wheel.so 或 pam_unix.so)失败,整个认证流程失败。
- 只有当所有
required 模块都成功时,认证才最终成功。
常用模块及其参数说明:
pam_unix.so 参数 (用于密码验证) 这是最核心的密码认证模块,常见于 auth 和 password 类型。
nullok:允许空密码账户通过认证。如果不加此参数,空密码账户将无法登录。try_first_pass:在提示用户输入密码前,先尝试使用之前栈中已缓存的密码(例如,由pam_timestamp.so 或 pam_kwallet.so 提供的)。use_authtok:强制使用之前栈中已缓存的密码,如果不存在缓存密码,则直接失败。它比try_first_pass 更严格,通常用在修改密码的 password 模块栈中,以确保用户输入的是旧密码。shadow:使用 /etc/shadow 文件进行密码验证(现代系统默认启用)。
pam_timestamp.so 参数 (用于时间戳认证)
常用于 sudo,实现免密码操作。
timestamp_timeout=600:设置时间戳的有效期,单位为秒。默认是 300 (5分钟)。
pam_wheel.so 参数 (用于组成员资格检查) 用于限制只有特定组的用户才能使用 su 或 sudo。
use_uid:检查发起请求的原始用户 ID,而不是当前用户 ID(在 sudo 场景下很重要)。group=admins:指定检查的组名,默认是 wheel。
pam_gnome_keyring.so 参数 (用于会话管理) 这个模块与 sudo 的认证流程无关,主要用于用户登录时解锁密钥环。
auto_start:在会话启动时,如果用户密码与密钥环密码相同,则自动解锁密钥环。- 典型应用场景:在
/etc/pam.d/gdm-password 或 /etc/pam.d/login 的 auth 和session 部分。
# 在 /etc/pam.d/gdm-password 中
auth optional pam_gnome_keyring.so
session optional pam_gnome_keyring.so auto_start
3.1.3 应用程序与 PAM 的交互
程序通过 pam_start() 指定服务名,系统据此加载对应的配置文件。
| 程序 |
服务名 |
配置文件 |
功能 |
login |
"login" |
/etc/pam.d/login |
控制台登录 |
gdm |
"gdm" |
/etc/pam.d/gdm |
GNOME 登录界面 |
sudo |
"sudo" |
/etc/pam.d/sudo |
提权命令 |
sshd |
"sshd" |
/etc/pam.d/sshd |
SSH 登录 |
greetd |
"greetd" |
/etc/pam.d/greetd |
轻量显示管理器 |
一个典型的调用顺序如下(以 sudo 为例):
pam_start("sudo", user, &conv, &pamh); // 初始化 PAM
pam_authenticate(pamh, 0); // 身份验证
pam_acct_mgmt(pamh, 0); // 账户检查
pam_open_session(pamh, 0); // 打开会话
// 执行用户命令
pam_close_session(pamh, 0); // 关闭会话
pam_end(pamh, PAM_SUCCESS); // 释放资源
如下是一个用户登录流程的 PAM 调用示例:
#include <stdio.h>
#include <stdlib.h>
#include <security/pam_appl.h>
#include <security/pam_misc.h>
static void log_result(pam_handle_t *pamh, int ret, const char *step)
{
if (ret == PAM_SUCCESS) {
printf("[✓] %s 成功\n", step);
} else {
fprintf(stderr, "[✗] %s 失败: %s(返回码 %d)\n",
step, pam_strerror(pamh, ret), ret);
}
}
int main(int argc, char *argv[])
{
pam_handle_t *pamh = NULL;
struct pam_conv conv = { misc_conv, NULL };
const char *user;
int ret;
if (argc != 2) {
fprintf(stderr, "用法: %s 用户名\n", argv[0]);
return 1;
}
user = argv[1];
/* 1. 初始化 */
ret = pam_start("login", user, &conv, &pamh);
if (ret != PAM_SUCCESS) {
log_result(pamh, ret, "pam_start");
return 1;
}
/* 2. 认证 */
ret = pam_authenticate(pamh, 0);
log_result(pamh, ret, "pam_authenticate");
if (ret != PAM_SUCCESS) {
pam_end(pamh, ret);
return 1;
}
/* 3. 帐户检查 */
ret = pam_acct_mgmt(pamh, 0);
log_result(pamh, ret, "pam_acct_mgmt");
if (ret != PAM_SUCCESS) {
pam_end(pamh, ret);
return 1;
}
/* 4. 打开会话 */
ret = pam_open_session(pamh, 0);
log_result(pamh, ret, "pam_open_session");
if (ret != PAM_SUCCESS) {
/* 常见原因提示 */
fprintf(stderr,
"\n提示:\n"
" 1. 若您以普通用户运行,失败通常是权限不足(写 /var/run/utmp 等)。\n"
" 2. 以 root 再次运行即可验证会话模块能否通过:sudo %s %s\n",
argv[0], user);
pam_end(pamh, ret);
return 1;
}
printf("\n全部 PAM 阶段通过!\n");
/* 5. 关闭会话并清理 */
pam_close_session(pamh, 0);
pam_end(pamh, PAM_SUCCESS);
return 0;
}
将上述配置保存为 pam_test.c, 再创建一个 shell.nix 内容如下:
{ pkgs ? import <nixpkgs> {} }:
pkgs.mkShell {
buildInputs = with pkgs; [
pam
gcc
];
}
最后编译运行:
# 进入引入了 pam 链接库的环境
nix-shell
# 编译
gcc pam_test.c -o pam_test -lpam -lpam_misc
# 测试
./pam_test ryan
3.1.4 模块间的数据传递
PAM 模块可通过 pam_set_data() 与 pam_get_data() 共享状态。例如:
pam_set_data(pamh, "authenticated", "true", NULL);
const char *ok;
pam_get_data(pamh, "authenticated", (const void **)&ok);
这使多个模块在同一认证过程中共享信息。
3.1.5 调试与故障排查
PAM 的问题通常来源于配置错误或模块加载失败,可按以下思路排查:
(1)测试与验证
nix shell nixpkgs#pamtester
# 模拟特定服务的认证流程
pamtester sudo $USER authenticate
pamtester login $USER open_session
(2)检查模块与依赖
# 验证模块存在与架构匹配
ls /run/current-system/sw/lib/security/pam_unix.so
ldd /run/current-system/sw/lib/security/pam_unix.so
(3)查看系统日志
journalctl -b | grep -i pam
(4)跟踪调用行为
strace -f -e trace=openat,read,write -o sudo_trace.log sudo true
grep pam sudo_trace.log
(5)常见问题
| 问题 |
可能原因 |
| 模块加载失败 |
模块路径错误或权限不足 |
| 认证成功但无法建立会话 |
会话模块执行失败(如无法写入 /var/run/utmp) |
| GNOME Keyring 不自动解锁 |
pam_gnome_keyring.so 未启用或未配置 auto_start |
| PAM 配置无效 |
程序服务名与配置文件不匹配,默认使用 other |
3.2 PolicyKit - 细粒度的系统权限管理
PolicyKit(现称 polkit)是一个用于控制系统级权限的框架,它提供了一种比传统 Unix 权限更细粒度的授权机制。在现代 Linux 桌面系统中,PolicyKit 允许非特权用户执行某些需要特权的系统操作
(如关机、重启、挂载设备、修改系统时间等),而无需获取完整的 root 权限。
3.2.1 PolicyKit 的核心概念
配置文件路径:
/etc/polkit-1/:NixOS 声明式配置中定义的自定义规则(优先级最高)/run/current-system/sw/share/polkit-1/(NixOS)或 /usr/share/polkit-1/(传统发行版):软件包提供的默认规则
上述文件夹中又包含两类配置:
- 动作(Actions)
- 定义在配置文件夹的
actions 目录中的 XML 文件(如 /etc/polkit-1/actions/),描述可授权的操作。每个动作都有唯一的标识符,如 org.freedesktop.login1.power-off 表示关机操作。
- 规则(Rules)
- JavaScript 文件,定义授权决策逻辑,位于上述配置文件夹的
rules.d/ 目录中(如/etc/polkit-1/rules.d/)。规则决定了在特定条件下是否授权某个操作。在 NixOS 中,推荐使用声明式配置而非直接修改 /etc 目录。
身份认证代理(Authentication Agents):桌面环境提供的图形界面组件,用于在用户需要身份验证时弹出认证对话框。例如,当普通用户尝试关机时,认证代理会提示输入管理员密码。
举例来说,我使用的是 Niri 窗口管理器,它的 Nix Flake 启用了 pokit-kde-agent-1 作为其
Authentication Agent, 配置参见sodiboo/niri-flake.
3.2.2 PolicyKit 的工作原理
当应用程序请求执行需要特权的操作时,系统服务会询问 PolicyKit 是否授权。PolicyKit 的评估过程如下:
- 身份识别:确定请求者的身份(用户、组、会话等)
- 规则匹配:检查是否有适用的规则文件
- 权限评估:根据规则返回以下结果之一:
yes:直接允许,无需认证no:直接拒绝auth_self:需要用户自己认证(输入当前用户密码)auth_admin:需要管理员认证(输入 root 密码)auth_self_keep/auth_admin_keep:认证后在一段时间内保持授权
3.2.3 PolicyKit 的配置示例
在传统的 Linux 发行版中,管理员可以通过创建自定义规则来修改默认行为。例如,允许 wheel 组的用户无需密码即可关机:
// /etc/polkit-1/rules.d/10-shutdown.rules
polkit.addRule(function (action, subject) {
if (action.id == "org.freedesktop.login1.power-off" && subject.isInGroup("wheel")) {
return polkit.Result.YES
}
})
NixOS 中的配置方法:在 NixOS 中,推荐使用声明式配置而非直接修改 /etc 目录。可以通过security.polkit 配置项来管理 PolicyKit 规则:
# configuration.nix
{
security.polkit.enable = true;
# 添加自定义规则
security.polkit.extraConfig = ''
polkit.addRule(function(action, subject) {
if (action.id == "org.freedesktop.login1.power-off" &&
subject.isInGroup("wheel")) {
return polkit.Result.YES;
}
});
'';
}
3.2.4 PolicyKit 与 D-Bus 的集成
PolicyKit 与 D-Bus 深度集成,为 D-Bus 服务提供动态授权机制。许多系统服务(如
systemd、NetworkManager、udisks 等)都使用 PolicyKit 来控制对其 D-Bus 接口的访问。当客户端通过 D-Bus 调用需要特权的方法时,服务会调用 PolicyKit 进行授权检查。
PolicyKit 调试主要涉及服务状态检查、权限测试和规则验证。常用的调试方法包括:
- 服务状态检查:验证 PolicyKit 守护进程的运行状态
- 权限测试:使用
pkcheck 工具测试特定操作的授权情况
- 日志分析:查看 PolicyKit 的授权决策日志
- 规则验证:检查当前生效的 PolicyKit 规则配置
具体的调试命令请参考 3.5.3 故障排查 章节。
3.3 桌面密钥管理
现代 Linux 桌面环境提供了统一的密钥管理服务,用于安全存储用户的密码、证书、密钥等敏感信息。
GNOME Keyring 和 KDE Wallet 分别是 GNOME 和 KDE 桌面环境的密钥管理解决方案,它们通过加密存储和自动解锁机制,为用户提供了便捷而安全的密码管理体验。
GNOME Keyring 和 KDE Wallet 都实现了标准的Secrets API, 可以根据需要任选一个使用。不过据我观察大部分窗口管理器的用户都是用的 GNOME Keyring.
3.3.1 密钥管理系统架构
GNOME Keyring 架构:
- 密钥环(Keyring):加密的存储容器,每个密钥环有独立的密码
- 密钥环守护进程(gnome-keyring-daemon):管理密钥环的生命周期和访问控制
- API:Gnome 原生支持 org.freedesktop.secrets DBus API, 目前流行的 secrets 客户端库 libsecret 也是 gnome 开发的。
- PAM 集成:通过
pam_gnome_keyring.so 实现登录时自动解锁
KDE Wallet 架构:
- KWalletManager:图形界面管理工具
- kwalletd:钱包守护进程
- API:KDE Wallet 从 5.97.0 (2022 年 8 月)开始支持org.freedesktop.secrets DBus API,
因此可以直接通过 libsecret 往 KDE Wallet 中存取 passwords 等 secret.
- PAM 集成:通过
pam_kwallet.so 实现自动解锁
核心组件路径:
# GNOME Keyring 组件(NixOS 中位于 nix store)
/run/current-system/sw/bin/gnome-keyring-daemon
/run/current-system/sw/lib/libsecret-1.so
/run/current-system/sw/lib/security/pam_gnome_keyring.so
# KDE Wallet 组件(NixOS 中位于 nix store)
/run/current-system/sw/bin/kwalletd5
/run/current-system/sw/bin/kwalletmanager5
/run/current-system/sw/lib/security/pam_kwallet.so
# 配置文件位置
~/.local/share/keyrings/ # GNOME 密钥环存储目录
~/.local/share/kwalletd/ # KDE 钱包文件存储目录
~/.config/kwalletrc # KDE 钱包配置文件
3.3.2 密钥环类型与用途
| 密钥环类型 |
用途 |
解锁时机 |
| login |
登录密钥环,存储用户密码 |
用户登录时自动解锁 |
| default |
默认密钥环,存储应用密码 |
首次访问时解锁 |
| session |
会话密钥环,临时存储 |
会话开始时创建 |
| crypto |
加密密钥环,存储证书和私钥 |
按需解锁 |
3.3.3 钱包创建与管理
图形界面管理:
# GNOME 密钥环管理器
seahorse
# KDE 钱包管理器
kwalletmanager5
通过图形界面可以:
- 创建新的密钥环/钱包
- 设置密码和加密算法
- 管理存储的密码和证书
- 配置自动解锁策略
- 备份和恢复密钥环
基本命令行操作:
# 使用 secret-tool 管理 GNOME Keyring
secret-tool store --label="My Password" application myapp
secret-tool lookup application myapp
# 使用 kwallet-query 管理 KDE Wallet
kwallet-query --write password "MyApp" "username" "password"
kwallet-query --read password "MyApp" "username"
3.3.4 应用程序集成
常见应用程序集成:
VSCode:
- 自动集成系统密钥管理服务
- 存储 Git 凭据、扩展设置等敏感信息
- 通过
git credential.helper 配置自动使用
GitHub CLI:
# 配置 GitHub CLI 使用系统密钥管理
gh auth login --web
# 凭据会自动存储到系统密钥环中
浏览器集成:
- Firefox、Chrome 等现代浏览器支持系统密钥管理
- 网站密码自动保存到密钥环/钱包中
- 跨设备同步(如果启用)
API 集成示例:
3.3.5 配置与优化
NixOS 配置示例:
# configuration.nix
# 启用 GNOME Keyring
services.gnome.gnome-keyring.enable = true;
# GNOME Keyring GUI 客户端
programs.seahorse.enable = true;
# 启用 PAM 集成
security.pam.services.login.enableGnomeKeyring = true;
3.4 安全故障排查
3.4.1 认证问题排查
常见认证失败场景:
-
用户无法登录
- 检查 PAM 配置是否正确
- 查看认证日志中的错误信息
- 验证用户账户状态和密码
-
sudo 权限问题
- 确认用户在正确的用户组中
- 检查 sudoers 配置
- 验证 PAM 认证流程
-
SSH 登录失败
- 检查 SSH 服务状态
- 查看 SSH 认证日志
- 验证网络连接和防火墙设置
3.4.2 权限管理问题排查
PolicyKit 权限问题:
- 无法关机/重启:检查 PolicyKit 规则配置和用户组权限
- 无法挂载设备:检查 udisks2 服务和 PolicyKit 集成
- 无法修改系统时间:检查时间同步服务权限和用户组设置
3.4.3 密钥管理问题排查
GNOME Keyring 问题:
- 检查密钥环守护进程是否正常运行
- 验证 PAM 集成是否正确配置
- 查看密钥环状态和自动解锁设置
KDE Wallet 问题:
- 检查钱包守护进程状态
- 验证钱包配置和访问权限
- 测试钱包的读写功能
具体的调试命令和排查步骤请参考 3.5.3 故障排查 章节。
3.5 安全组件集成与最佳实践
3.5.1 组件协作流程
现代 Linux 桌面的安全组件协作流程:
- 用户登录:PAM 验证用户身份
- 密钥环解锁:PAM 模块自动解锁用户密钥环/钱包
- 应用启动:应用程序通过 libsecret/KWallet API 访问存储的密码
- 特权操作:PolicyKit 控制需要特权的系统操作
- 会话结束:密钥环/钱包自动锁定
3.5.2 安全最佳实践
密钥管理:
- 使用强密码保护密钥环/钱包
- 定期备份密钥环文件
- 避免在脚本中硬编码密码
- 使用应用程序专用的密钥环
认证配置:
# 启用双因子认证
auth required pam_google_authenticator.so
auth required pam_unix.so
# 配置密码策略
password required pam_cracklib.so retry=3 minlen=8 difok=3
password required pam_unix.so use_authtok
权限管理:
// PolicyKit 规则示例:限制特定操作
polkit.addRule(function (action, subject) {
if (action.id == "org.freedesktop.login1.power-off" && subject.user == "guest") {
return polkit.Result.NO
}
})
3.5.3 故障排查
PAM 认证调试:
nix shell nixpkgs#pamtester
# 测试 PAM 配置
pamtester login $USER authenticate
pamtester sudo $USER authenticate
# 查看 PAM 配置
cat /etc/pam.d/login
cat /etc/pam.d/greetd
cat /etc/pam.d/sudo
# 检查 PAM 模块
ldd /run/current-system/sw/lib/security/pam_unix.so
ldd /run/current-system/sw/lib/security/pam_gnome_keyring.so
# 查看认证日志
journalctl -t login -f
journalctl -t greetd -f
journalctl -t sshd -f
journalctl -t sudo
# 验证程序与配置的对应关系
strace -e trace=pam_start login 2>&1 | grep pam_start
strace -e trace=openat login 2>&1 | grep pam.d
PolicyKit 权限调试:
# 检查 PolicyKit 服务状态
systemctl status polkit
# 测试特定权限
pkcheck --action-id org.freedesktop.login1.power-off --process $$ --allow-user-interaction
# 查看 PolicyKit 日志
journalctl -u polkit -f
# 查看 PolicyKit 动作定义
ls -la /run/current-system/sw/share/polkit-1/actions/
# 查看当前生效的 PolicyKit 规则
ls -la /etc/polkit-1/rules.d/
密钥管理调试:
# GNOME Keyring 检查
ps aux | grep gnome-keyring
seahorse # GNOME Keyring GUI
# KDE Wallet 检查
ps aux | grep kwalletd
kwalletmanager5 # KDE Wallet GUI
kwallet-query kdewallet --list-entries
# 系统日志检查
sudo journalctl -u systemd-logind
调试技巧:
- 使用
strace 跟踪应用程序的密钥访问
- 通过
journalctl 查看认证和授权日志
- 使用
pamtester 测试 PAM 配置
- 通过
pkcheck 测试 PolicyKit 权限
通过理解这些安全组件的协作机制,用户可以更好地配置和管理 Linux 桌面的安全策略,在保证安全性的同时提供良好的用户体验。
总结
从 UEFI 到 systemd,从 PAM 到 PolicyKit,本文详细介绍了 Linux 桌面系统启动与安全框架的核心组件。
下一篇文章将深入探讨 systemd 全家桶与服务管理,包括 D-Bus 系统总线、日志系统和设备管理等核心功能,这些组件为桌面环境提供了强大的基础设施支持。
快速参考
常用启动排查命令
# 启动时间分析
systemd-analyze
systemd-analyze blame
systemd-analyze critical-chain
# 引导加载器检查
bootctl status
bootctl list
efibootmgr -v
# 内核和硬件信息
dmesg | grep -i error
lspci -k
lsusb
lsblk
# 进入救援模式
# 在内核参数中添加:init=/bin/sh 或 break=mount
常用安全排查命令
安全相关的调试命令请参考 3.5.3 故障排查 章节,该章节提供了完整的
PAM、PolicyKit 和密钥管理调试命令。
重要配置文件位置
# 启动相关
/boot/loader/loader.conf # systemd-boot 全局配置
/boot/EFI/Linux/ # UKI 镜像位置
/etc/pam.d/ # PAM 配置文件
/etc/polkit-1/ # PolicyKit 配置
# 密钥管理
~/.local/share/keyrings/ # GNOME Keyring 存储
~/.local/share/kwalletd/ # KDE Wallet 存储
~/.config/kwalletrc # KDE Wallet 配置







































 配置成功
配置成功