相关的类的定义和功能可以查看 Android 显示原理(手册)
显示流程, 表面意思就是在 android 系统中, 是如何将画面显示在手机上的整体流程.
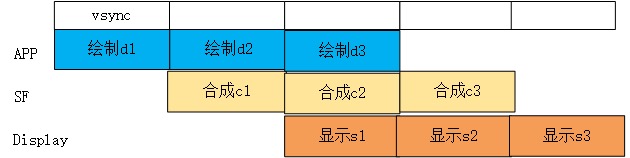
android 系统的显示流水线,主要包含三个阶段, 绘制、合成和显示
绘制阶段包括了窗口的概念, 涉及到 AMS, WMS, DMS, 大致流程可以分为下面几部分
应用层创建 Activity, 通过 AMS 启动 Activity
创建 Activity 时, 通过我们设置的 setContentView 附属到 DectorView 中,通过 WMS 创建对应的 Window,这个过程会创建一系列的对象
Activity
ViewRootImpl
Window
Surface
Layer
窗口
绘制
绘制阶段是比较长的一个阶段, 涉及到的模块也很多, 大部分在 framework 的 JAVA 层中, 我们做应用开发时经常接触到的就是 Activity、Window 以及 View, 涉及到 framework 中的服务就是 AMS、WMS、DMS 等, 你可能经常听到窗口, 一般口头上我们说到窗口或者窗口管理的时候,都是指所有的窗口,比如 Activity、dialog 等, Activity 委托 View 负责显示, 三者的关系可以简单理解为, view 组成 Activity, Activity 在窗口模块中被抽象为 Window
View 主要有三个方法, Measure、Layout 和 Draw, Draw 的时候才会开始真正分配 buffer
在 View 中有一个比较重要的 DectorView, 它是 Activity 的根 View, 窗口的添加就是通过 WindowManager.addView()把该 mDecorView 添加到 WindowManager 中, 所以一个 Activity 对应一个窗口, 当然你也可以直接通过 WindowManager 添加一个单独的 view, 这样也是一个窗口
WindowManagerService (服务端, 与绘制无关)
窗口的状态、属性, 如大小, 位置; (WindowState, 与上面的 DectorView 一一对应)
View 增加、删除、更新
窗口顺序
Input Event 消息收集和处理等(与绘制无关, 可不用关心)
SurfaceFlinger(服务端, 与绘制无关)
Layer 的大小、位置(Layer 与上面的 WindowState 一一对应)
Layer 的增加、删除、更新;
Layer 的 zorder 顺序
framework/base: Canvas
SoftwareCanvas (skia/CPU)
HardwareCanvas (hwui/GPU)
framework/base: Surface
区别于 WMS 的 Surface 概念, 与 Canvas 一一对应, 内容生产者
framework/native:
Surface: 负责分配 buffer 与填充(由上面的 Surface 传下来)
SurfaceFlinger
Layer 数据已填充好, 与上面提到的 Surface 同样是一一对应
可见 Layer 这个概念即是控制端又是内容端, SF 更重要的是合成
Window -> DecorView-> ViewRootImpl -> WindowState -> Surface -> Layer 是一一对应的
在 Android 应用程序进程这一侧, 每一个窗口都关联有一个 Surface. 每当窗口需要绘制 UI 时, 就会调用其关联的 Surface 的成员函数 lock 获得一个 Canvas, 其本质上是向 SurfaceFlinger 服务 dequeue 一个 Graphic Buffer.
//android_view_Surface.cpp static jlong nativeLockCanvas (JNIEnv* env, jclass clazz, jlong nativeObject, jobject canvasObj, jobject dirtyRectObj) sp<Surface> surface (reinterpret_cast <Surface *>(nativeObject)) ; ...... ANativeWindow_Buffer outBuffer; //调用了Surface的dequeueBuffer, 从SurfaceFlinger中申请内存GraphicBuffer,这个buffer是用来传递绘制的元数据的 status_t err = surface->lock (&outBuffer, dirtyRectPtr); if (err < 0 ) { const char * const exception = (err == NO_MEMORY) ? OutOfResourcesException : "java/lang/IllegalArgumentException" ; jniThrowException (env, exception, NULL ); return 0 ; } SkImageInfo info = SkImageInfo::Make (outBuffer.width, outBuffer.height, convertPixelFormat (outBuffer.format), outBuffer.format == PIXEL_FORMAT_RGBX_8888 ? kOpaque_SkAlphaType : kPremul_SkAlphaType); //新建了一个SkBitmap, 并进行了一系列设置 SkBitmap bitmap; ssize_t bpr = outBuffer.stride * bytesPerPixel (outBuffer.format); bitmap.setInfo (info, bpr); if (outBuffer.width > 0 && outBuffer.height > 0 ) { //bitmap对graphicBuffer进行关联 bitmap.setPixels (outBuffer.bits); } else { // be safe with an empty bitmap. bitmap.setPixels (NULL ); } //构造一个native的Canvas对象(SKCanvas), 再返回这个Canvas对象, java层的Canvas对象其实只是对SKCanvas对象的一个简单包装, 所有绘制方法都是转交给SKCanvas来做. Canvas* nativeCanvas = GraphicsJNI::getNativeCanvas (env, canvasObj); //bitmap对下关联了获取的内存buffer, 对上关联了Canvas,把这个bitmap放入Canvas中 nativeCanvas->setBitmap (bitmap); ...... sp<Surface> lockedSurface (surface) ; lockedSurface->incStrong (&sRefBaseOwner); return (jlong) lockedSurface.get (); }
SkCanvas 是按照 SkBitmap 的方法去关联 GraphicBuffer
一、渲染层级 从渲染流程上分, Skia 可分为如下三个层级:
指令层:SkPicture、SkDeferredCanvas->SkCanvas
解析层:SkBitmapDevice->SkDraw->SkScan、SkDraw1Glyph::Proc
渲染层:SkBlitter->SkBlitRow::Proc、SkShader::shadeSpan 等
最后一个步骤会通知消费者的 onFrameAvailable 接口, 进一步调用 SurfaceFlinger 的 signalLayerUpdate 发起更新操作
具体参考:https://www.jianshu.com/p/40f660e17a73
CPU 更擅长复杂逻辑控制, 而 GPU 得益于大量 ALU 和并行结构设计, 更擅长数学运算.
开启硬件绘制条件是在 ViewRootImpl 的 draw 中
private void draw (boolean fullRedrawNeeded) { ... if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) { //关键点1 是否开启硬件加速 if (mAttachInfo.mThreadedRenderer != null && mAttachInfo.mThreadedRenderer.isEnabled()) { ... dirty.setEmpty(); mBlockResizeBuffer = false ; //关键点2 硬件加速绘制 mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this ); } else { ... //关键点3 软件绘制 if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) { return ; } } } }
硬件加速渲染和软件渲染一样, 在开始渲染之前, 都是要先向 SurfaceFlinger 服务 dequeue 一个 Graphic Buffer. 不过对硬件加速渲染来说, 这个 Graphic Buffer 会被封装成一个 ANativeWindow, 并且传递给 OpenGL 进行硬件加速渲染环境初始化.
硬件加速绘制包括两个阶段:构建阶段 + 绘制阶段, 所谓构建就是递归遍历所有视图, 将需要的操作缓存下来, 之后再交给单独的 Render 线程利用 OpenGL 渲染. 在 Android 硬件加速框架中, View 视图被抽象成 RenderNode 节点, View 中的绘制都会被抽象成一个个 DrawOp(DisplayListOp), 比如 View 中 drawLine, 构建中就会被抽象成一个 DrawLintOp, drawBitmap 操作会被抽象成 DrawBitmapOp, 每个子 View 的绘制被抽象成 DrawRenderNodeOp, 每个 DrawOp 有对应的 OpenGL 绘制命令, 同时内部也握着绘图所需要的数据. 如下所示:
如此以来, 每个 View 不仅仅握有自己 DrawOp List, 同时还拿着子 View 的绘制入口, 如此递归, 便能够统计到所有的绘制 Op, 很多分析都称为 Display List, 源码中也是这么来命名类的, 不过这里其实更像是一个树, 而不仅仅是 List, 示意如下:
构建完成后, 就可以将这个绘图 Op 树交给 Render 线程进行绘制, 这里是同软件绘制很不同的地方, 软件绘制时, View 一般都在主线程中完成绘制, 而硬件加速, 除非特殊要求, 一般都是在单独线程中完成绘制, 如此以来就分担了主线程很多压力, 提高了 UI 线程的响应速度.
引进 Display List 的概念有什么好处呢?主要是两个好处。