Java|小数据量场景的模糊搜索体验优化
2025年4月23日 00:00
在小数据量场景下,如何优化模糊搜索体验?本文分享一个简单实用的方案,虽然有点“土”,但效果还不错。
场景
假设有一张表 t_course,数据量在三到四位数,字段 name 需要支持模糊搜索。用普通的 LIKE 语句,比如:
SELECT id, name FROM t_course WHERE name LIKE '%2025数学高一下%';
结果却查不到 2025年高一数学下学期。这就很尴尬了,用户体验直接拉胯。
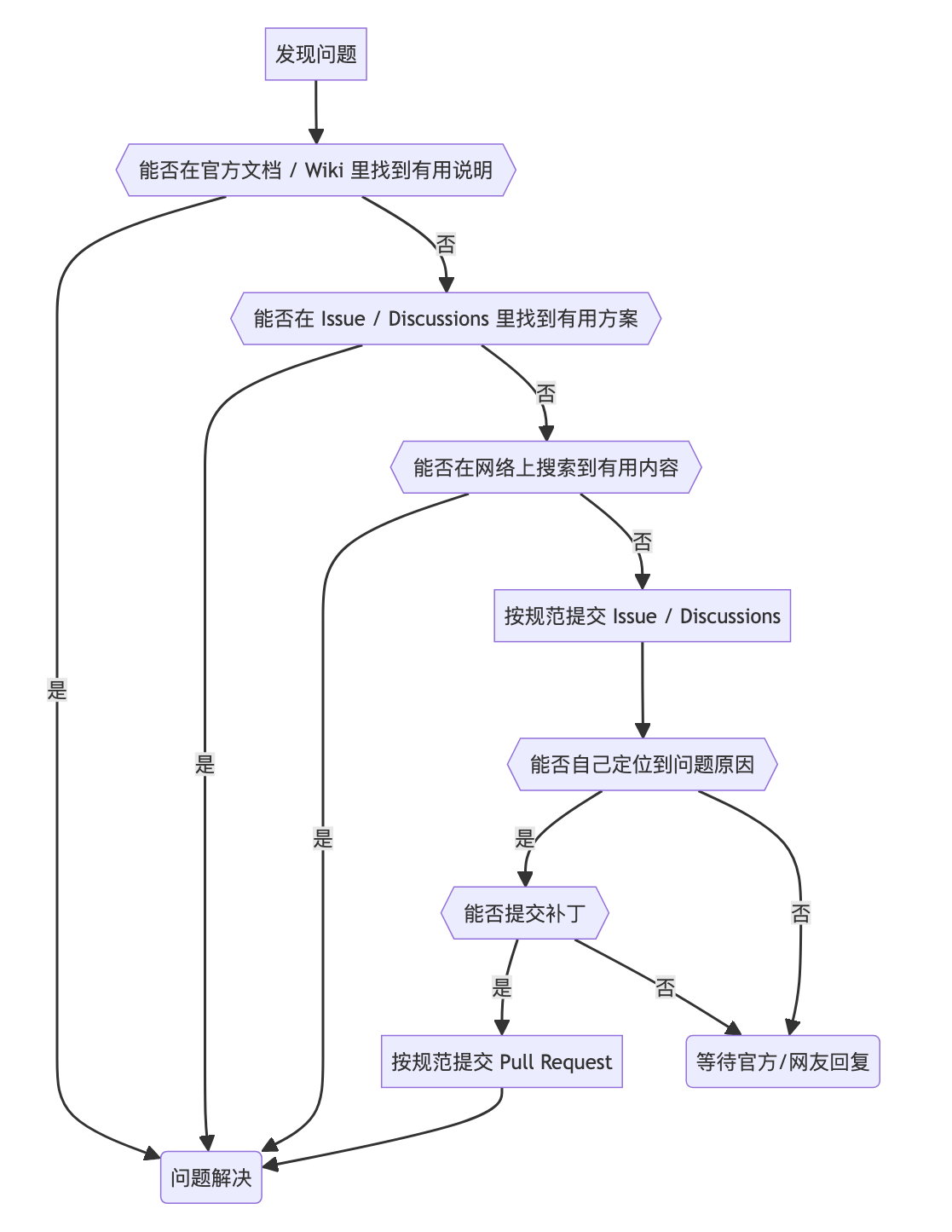
方案探索
1. MySQL 全文索引
首先想到 MySQL 的全文索引,但要支持中文分词得改 ngram_token_size 配置,还得重启数据库。为了不动生产环境配置,果断放弃。
2. Elasticsearch
接着想到 Elasticsearch,但对这么简单的场景来说,未免有点“杀鸡用牛刀”。于是继续寻找更轻量的方案。
3. 自定义分词 + MySQL INSTR
最后想到一个“土办法”:先对用户输入进行分词,再用 MySQL 的 INSTR 函数匹配。简单粗暴,但很实用。
![]()
实现
分词工具
一开始用了 jcseg 分词库,写了个工具类:
public class JcSegUtils {
private static final SegmenterConfig CONFIG = new SegmenterConfig(true);
private static final ADictionary DIC = DictionaryFactory.createSingletonDictionary(CONFIG);
public static List<String> segment(String text) throws IOException {
ISegment seg = ISegment.NLP.factory.create(CONFIG, DIC);
seg.reset(new StringReader(text));
IWord word;
List<String> result = new ArrayList<>();
while ((word = seg.next()) != null) {
String wordText = word.getValue();
if (StringUtils.isNotBlank(wordText)) {
result.add(wordText);
}
}
return result;
}
}
本地测试一切正常,但部署到测试环境后,分词结果却变了!比如:
- 本地:
[2025, 数学, 高一, 下] - 测试环境:
[2025, 数, 学, 高, 1, 下]
原因是 jcseg 在 jar 包中加载默认配置和词库时出问题了。网上的解决方案大多是外置词库,但我懒得折腾,决定自己撸个简易分词工具。
简易分词工具
最终实现如下:
public class WordSegmentationUtils {
private static final List<String> DICT;
private static final String COURSE_SEARCH_KEYWORD_LIST = "数学,物理,化学,生物,地理,历史,政治,英语,语文,高中,高一,高二,高三";
static {
DICT = new ArrayList<>();
for (int i = 2018; i <= 2099; i++) {
DICT.add(String.valueOf(i));
}
DICT.addAll(Arrays.asList(COURSE_SEARCH_KEYWORD_LIST.split(",")));
}
public static List<String> segment(String text) {
if (StringUtils.isBlank(text)) {
return new ArrayList<>();
}
List<String> segments = new ArrayList<>();
segments.add(text);
for (String word : DICT) {
segments = segment(segments, word);
}
return segments;
}
private static List<String> segment(List<String> segments, String word) {
List<String> newSegments = new ArrayList<>();
for (String segment : segments) {
if (segment.contains(word)) {
newSegments.add(word);
String[] split = segment.split(word);
for (String s : split) {
if (StringUtils.isNotBlank(s)) {
newSegments.add(s.trim());
}
}
} else {
newSegments.add(segment);
}
}
return newSegments;
}
}
这个工具基于一个简单的词典 DICT,按词典中的词对输入文本进行分割。比如:
- 输入:
2025数学高一下 - 输出:
[2025, 数学, 高一, 下]
效果验证
现在,无论用户输入以下哪种形式,都能成功匹配到 2025年高一数学下学期:
2025高一数学下2025 高一 数学数学高一2025
小结
这个方案虽然简单,但在小数据量场景下,性能和体验都能满足需求,且实现成本低。如果遇到特殊情况,可以通过动态更新词典来解决。
当然,这种“土办法”并不适合复杂场景。如果需求升级,可以再考虑 MySQL 全文索引或 Elasticsearch。
最后,自己一个人负责开发和运维就是任性!如果有团队一起评审,这方案可能早就被否了吧……额,达摩克利斯之剑高悬。