Running BeforeDevCommand (`trunk serve`) 2023-03-19T12:51:19.075591Z INFO 📦 starting build 2023-03-19T12:51:19.075822Z INFO spawning asset pipelines 2023-03-19T12:51:19.486709Z INFO building rust-tauri-app-ui 2023-03-19T12:51:19.486759Z INFO copying directory path="public" 2023-03-19T12:51:19.486782Z INFO copying & hashing css path="styles.css" 2023-03-19T12:51:19.487151Z INFO finished copying & hashing css path="styles.css" 2023-03-19T12:51:19.487281Z INFO finished copying directory path="public" Finished dev [unoptimized + debuginfo] target(s) in 0.17s 2023-03-19T12:51:19.701213Z INFO fetching cargo artifacts 2023-03-19T12:51:19.940618Z INFO processing WASM for rust-tauri-app-ui 2023-03-19T12:51:19.961661Z INFO calling wasm-bindgen for rust-tauri-app-ui 2023-03-19T12:51:20.120952Z INFO copying generated wasm-bindgen artifacts 2023-03-19T12:51:20.122868Z INFO applying new distribution 2023-03-19T12:51:20.123718Z INFO ✅ success 2023-03-19T12:51:20.124694Z INFO 📡 serving static assets at -> / 2023-03-19T12:51:20.124755Z INFO 📡 server listening at http://127.0.0.1:1420 Info Watching /Users/jartto/Documents/Project/rust-tauri-app/src-tauri for changes... Compiling rust-tauri-app v0.0.0 (/Users/jartto/Documents/Project/rust-tauri-app/src-tauri) Finished dev [unoptimized + debuginfo] target(s) in 2.29s
You must change the bundle identifier in `tauri.conf.json > tauri > bundle > identifier`. The default value `com.tauri.dev` is not allowed as it must be unique across applications. 您必须在 `tauri.conf.json > tauri > bundle > identifier` 中更改包标识符。 默认值 com.tauri.dev 是不允许的,因为它在应用程序中必须是唯一的。
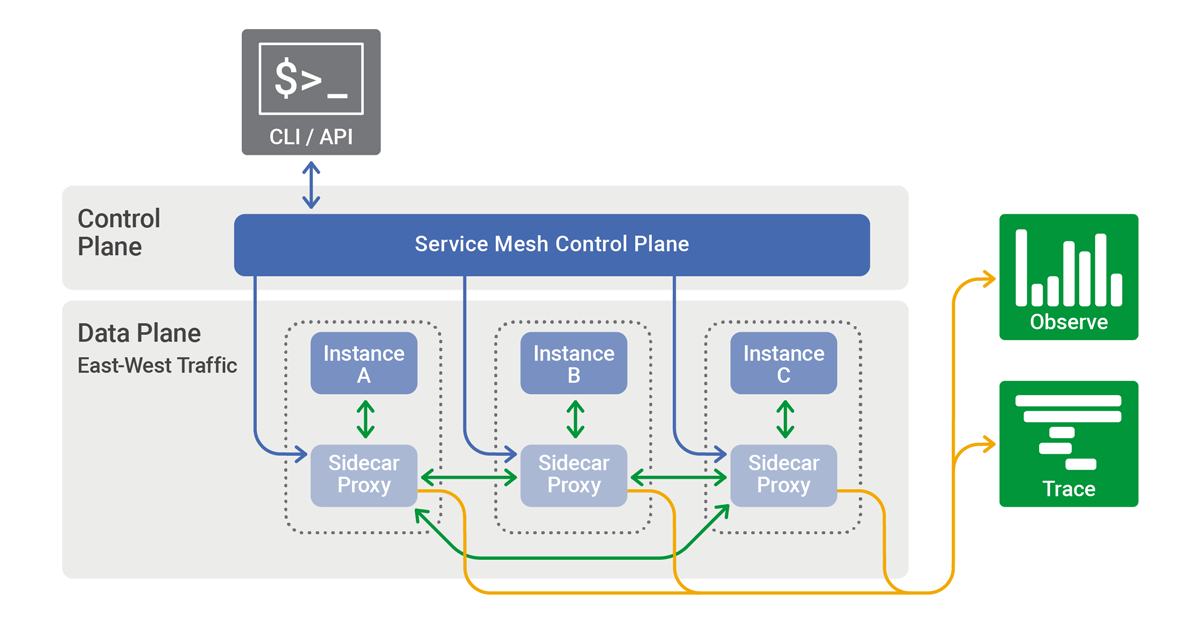
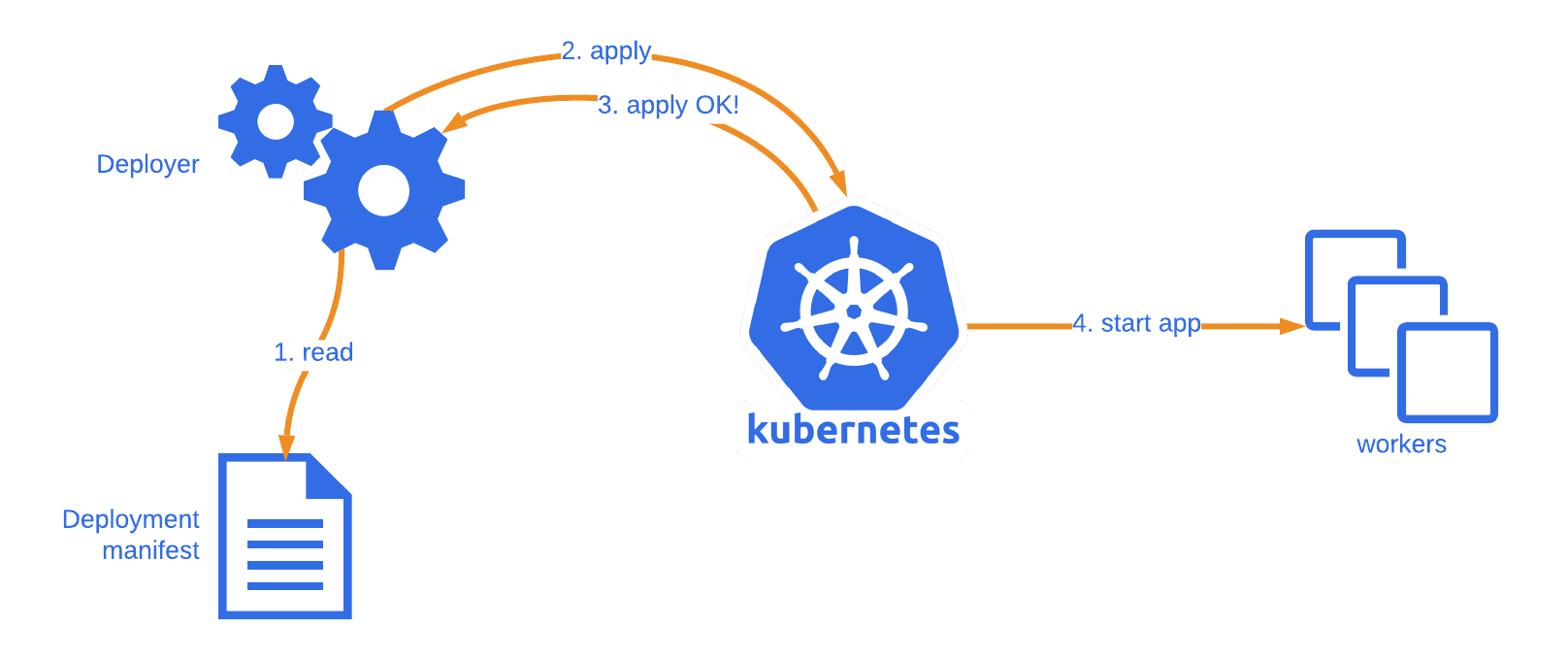
2.K8s 服务的负载均衡是如何实现的? Pod 中的容器很可能因为各种原因发生故障而死掉。Deployment 等 Controller 会通过动态创建和销毁 Pod 来保证应用整体的健壮性。换句话说,Pod 是脆弱的,但应用是健壮的。每个 Pod 都有自己的 IP 地址。当 controller 用新 Pod 替代发生故障的 Pod 时,新 Pod 会分配到新的 IP 地址。
这样就产生了一个问题:如果一组 Pod 对外提供服务(比如 HTTP),它们的 IP 很有可能发生变化,那么客户端如何找到并访问这个服务呢?
K8s 给出的解决方案是 Service。 Kubernetes Service 从逻辑上代表了一组 Pod,具体是哪些 Pod 则是由 Label 来挑选。
Service 有自己 IP,而且这个 IP 是不变的。客户端只需要访问 Service 的 IP,K8s 则负责建立和维护 Service 与 Pod 的映射关系。无论后端 Pod 如何变化,对客户端不会有任何影响,因为 Service 没有变。
3.无状态服务一般使用什么方式进行部署? Deployment 为 Pod 和 ReplicaSet 提供了一个 声明式定义方法,通常被用来部署无状态服务。
在官方文档中找到了如下描述: First Idle is the first early sign of time where the main thread has come at rest and the browser has completed a First Meaningful Paint.
Time to Interactive is after First Meaningful Paint. The browser’s main thread has been at rest for at least 5 seconds and there are no long tasks that will prevent immediate response to user input.
Long Tasks API 可以将任何耗时超过 50 毫秒的任务标示为可能存在问题,并向应用开发者显示这些任务。 选择 50 毫秒的时间是为了让应用满足在 100 毫秒内响应用户输入的 RAIL 指导原则。
实际开发过程中,我们可以通过一个 hack 来检查页面中「长任务」的代码:
1 2 3 4 5 6 7 8 9 10 11
// detect long tasks hack (functiondetectLongFrame() { let lastFrameTime = Date.now(); requestAnimationFrame(function() { let currentFrameTime = Date.now(); if (currentFrameTime - lastFrameTime > 50) { // Report long frame here... } detectLongFrame(currentFrameTime); }); }());
四、如何计算 TTI?
在计算之前,我们先来看一下 Timing API:
Google 官方文档中有一段描述: Note: Lower Bounding FirstInteractive at DOMContentLoadedEndDOMContentLoadedEnd is the point where all the DOMContentLoaded listeners finish executing. It is very rare for critical event listeners of a webpage to be installed before this point. Some of the firstInteractive definitions we experimented with fired too early for a small number of sites, because the definitions only looked at long tasks and network activity (and not at, say, how many event listeners are installed), and sometimes when there are no long tasks in the first 5-10 seconds of loading we fire FirstInteractive at FMP, when the sites are often not ready yet to handle user inputs. We found that if we take max(DOMContentLoadedEnd, firstInteractive) as the final firstInteractive value, the values returned to reasonable region. Waiting for DOMContentLoadedEnd to declare FirstInteractive is sensible, so all the definitions introduced below lower bound firstInteractive at DOMContentLoadedEnd.
The domContentLoadedEventEnd attribute MUST return a DOMHighResTimeStamp with a time value equal to the time immediately after the current document's DOMContentLoaded event completes.
import ttiPolyfill from'./path/to/tti-polyfill.js'; ttiPolyfill.getFirstConsistentlyInteractive(opts).then((tti) => { // Use `tti` value in some way. });
cloc [options] <file(s)/dir(s)/git hash(es)> Count physical lines of source code and comments in the given files (may be archives such as compressed tarballs or zip files) and/or recursively below the given directories or git commit hashes. Example: cloc src/ include/ main.c
cloc [options] --diff <set1> <set2> Compute differences of physical lines of source code and comments between any pairwise combination of directory names, archive files or git commit hashes. Example: cloc --diff Python-3.5.tar.xz python-3.6/