SpeedUp!使用黑科技为你的网站提速
实战,利用黑科技ServiceWorker提速你的网站。
本文所标记的内容,大多是直接复制粘贴即可实现的。但依然会存在这和您的服务存在冲突这一情况。请阅读上一篇基础文章欲善其事,必利其器 - 论如何善用ServiceWorker进行合理的修改。
我们简单的列一下表,这是我们加速清单:
前端竞速CDN
最传统的网页加载,其静态资源一旦独立是直接放在同域服务器下的。
不过后来,为了减少主服务器开销,我们通常将静态资分离至其他面向用户加载比较快的节点,以减少主服务器开销,提升网页加载速度。
现在,各种公益cdn服务蓬勃生长,其节点通常是全球部署,并且对各个国家/地区做了优化,使用公益cdn,他的质量和可用性是远远大于自己部署的。
在一个网页加载中,主网页只提供一个html(你所看的网页其大小约15kb),而流量开销巨头是静态资源(只论js,本页大约800kb)。我们对一个网站的加速,第一步就应当从静态加速做起。
对于加速存储的选择,通常市面上有三种主流加速cdnjs/npm/gh。而在这其中,对于个人而言,我还是推崇npm,这在接下来对于竞速节点的选择就多了起来。
对于加速节点的选择,从mainland角度来讲,首先你要遵循一个普世结论:不要用跨国节点。本身China国度就有个奇葩规定,没有ICP备案许可就不得在mainland开展网站服务。这使得大部分本应该分散在边缘末端的流量全压到了国际出口的汇聚层。你再引导他们去海外拉资源,凑过去挤热闹,其稳定性和速率完全无法保证,这在生产环境使用无异于自杀。这里提一嘴jsdelivr,备案掉了,节点迁出中国了,那你面向国内的网站早就可以切了。使用fastly,联通和电信晚上ntt几乎堵到妈都不认识,能连上就是奇迹。除非你真的不在意加速,也不在意资源能不能正常加载,在面向mainland的生产环境里还坚持jsd就是愚不可及的行为。
当然,在这里我还是推崇黑科技ServiceWorker,它可以利用Promise.any,并发数个请求至不同的cdn节点,提升前端资源加载。而借助于强大的js引擎,其在本地处理的效率奇高,性能折损几乎不计。
在这之前,我们定义一个lfetch,它的作用是对urls这个数组里的所有网址发起并发请求,并且在任意一个节点返回正常值时打断其余请求,避免流量浪费。
const lfetch = async (urls, url) => { let controller = new AbortController(); //针对此次请求新建一个AbortController,用于打断并发的其余请求 const PauseProgress = async (res) => { //这个函数的作用时阻塞响应,直到主体被完整下载,避免被提前打断 return new Response(await (res).arrayBuffer(), { status: res.status, headers: res.headers }); }; if (!Promise.any) { //Polyfill,避免Promise.any不存在,无需关注 Promise.any = function (promises) { return new Promise((resolve, reject) => { promises = Array.isArray(promises) ? promises : [] let len = promises.length let errs = [] if (len === 0) return reject(new AggregateError('All promises were rejected')) promises.forEach((promise) => { promise.then(value => { resolve(value) }, err => { len-- errs.push(err) if (len === 0) { reject(new AggregateError(errs)) } }) }) }) } } return Promise.any(urls.map(urls => {//并发请求 return new Promise((resolve, reject) => { fetch(urls, { signal: controller.signal//设置打断点 }) .then(PauseProgress)//阻塞当前响应直到下载完成 .then(res => { if (res.status == 200) { controller.abort()//打断其余响应(同时也打断了自己的,但本身自己已下载完成,打断无效) resolve(res)//返回 } else { reject(res) } }) }) }))}在这其中,有一个难点:fetch返回的时状态而非内容。
即当fetch的Promise resolve时,它是已经获得了响应,但此时内容还没下载,提前打断会导致无法返回。这是PauseProgress作用。
之后我们考虑静态资源加速。这时候用npm的好处就体现出来了,不仅镜像多,其格式也还算固定。
注意,此方法是以流量换速度的方式进行的,虽然在任何一个节点返回正确内容后会打断其余请求,但依然会造成不可避免的流量消耗(+~20%)。如果你面向的是手机流量用户,请三思而后行!
此代码与freecdn-js核心功能相似,但实现方法并不同,并且完全支持动态网页。
例如jquery,你可以这样加速:
原始地址:https://cdn.jsdelivr.net/npm/jquery@3.6.0各类镜像:https://fastly.jsdelivr.net/npm/jquery@3.6.0https://gcore.jsdelivr.net/npm/jquery@3.6.0https://unpkg.com/jquery@3.6.0https://unpkg.zhimg.com/jquery@3.6.0 #回源有问题https://unpkg.com/jquery@3.6.0https://npm.elemecdn.com/jquery@3.6.0https://npm.sourcegcdn.com/jquery@3.6.0 #滥用封仓库https://cdn1.tianli0.top/jquery@3.6.0 #滥用封仓库我们可以简单搓一个sw小脚本完成前端加速:
ServiceWorker完整代码:
我已经很详细的看了上面的阐述,并且我不会直接照搬
const CACHE_NAME = 'ICDNCache';let cachelist = [];self.addEventListener('install', async function (installEvent) { self.skipWaiting(); installEvent.waitUntil( caches.open(CACHE_NAME) .then(function (cache) { console.log('Opened cache'); return cache.addAll(cachelist); }) );});self.addEventListener('fetch', async event => { try { event.respondWith(handle(event.request)) } catch (msg) { event.respondWith(handleerr(event.request, msg)) }});const handleerr = async (req, msg) => { return new Response(`<h1>CDN分流器遇到了致命错误</h1> <b>${msg}</b>`, { headers: { "content-type": "text/html; charset=utf-8" } })}let cdn = {//镜像列表 "gh": { jsdelivr: { "url": "https://cdn.jsdelivr.net/gh" }, jsdelivr_fastly: { "url": "https://fastly.jsdelivr.net/gh" }, jsdelivr_gcore: { "url": "https://gcore.jsdelivr.net/gh" } }, "combine": { jsdelivr: { "url": "https://cdn.jsdelivr.net/combine" }, jsdelivr_fastly: { "url": "https://fastly.jsdelivr.net/combine" }, jsdelivr_gcore: { "url": "https://gcore.jsdelivr.net/combine" } }, "npm": { eleme: { "url": "https://npm.elemecdn.com" }, jsdelivr: { "url": "https://cdn.jsdelivr.net/npm" }, zhimg: { "url": "https://unpkg.zhimg.com" }, unpkg: { "url": "https://unpkg.com" }, bdstatic: { "url": "https://code.bdstatic.com/npm" }, tianli: { "url": "https://cdn1.tianli0.top/npm" }, sourcegcdn: { "url": "https://npm.sourcegcdn.com/npm" } }}//主控函数const handle = async function (req) { const urlStr = req.url const domain = (urlStr.split('/'))[2] let urls = [] for (let i in cdn) { for (let j in cdn[i]) { if (domain == cdn[i][j].url.split('https://')[1].split('/')[0] && urlStr.match(cdn[i][j].url)) { urls = [] for (let k in cdn[i]) { urls.push(urlStr.replace(cdn[i][j].url, cdn[i][k].url)) } if (urlStr.indexOf('@latest/') > -1) { return lfetch(urls, urlStr) } else { return caches.match(req).then(function (resp) { return resp || lfetch(urls, urlStr).then(function (res) { return caches.open(CACHE_NAME).then(function (cache) { cache.put(req, res.clone()); return res; }); }); }) } } } } return fetch(req)}const lfetch = async (urls, url) => { let controller = new AbortController(); const PauseProgress = async (res) => { return new Response(await (res).arrayBuffer(), { status: res.status, headers: res.headers }); }; if (!Promise.any) { Promise.any = function (promises) { return new Promise((resolve, reject) => { promises = Array.isArray(promises) ? promises : [] let len = promises.length let errs = [] if (len === 0) return reject(new AggregateError('All promises were rejected')) promises.forEach((promise) => { promise.then(value => { resolve(value) }, err => { len-- errs.push(err) if (len === 0) { reject(new AggregateError(errs)) } }) }) }) } } return Promise.any(urls.map(urls => { return new Promise((resolve, reject) => { fetch(urls, { signal: controller.signal }) .then(PauseProgress) .then(res => { if (res.status == 200) { controller.abort(); resolve(res) } else { reject(res) } }) }) }))}全站NPM静态化
此法chen独创,是一种比较野路子的手法,但加速效果显著。
通常建议用于Hexo等静态博客,WordPress等需要做好伪静态,并且要配置好动态接口。
hexo作为静态博客有什么好处,那当然是纯静态啦。生成的静态文件随便搬到一个web服务器都能用。
自然就有了接下的骚操作,用npm托管博客,然后在请求的时候用sw劫持并引流到npm镜像,效果就如同本博客所示,加载速度(抛开首屏不谈)接近于闪开。
首先我博客的CI是用GithubAction的,在部署的过程中顺便把html上传到npm是最简单不过的事情,只要在生成代码块后面再加一块:
- uses: JS-DevTools/npm-publish@v1 with: token: ${{ secrets.NPM }}配置NPM环境变量,之后需要更新的时候叠一个新版本就行。
然后接下来我们就要解决ServiceWorker获取问题。我们先设立一个监听器:
self.addEventListener('fetch', async event => { event.respondWith(handle(event.request))});const handle = async(req)=>{ const urlStr = req.url const urlObj = new URL(urlStr); const urlPath = urlObj.pathname; const domain = urlObj.hostname; //从这里开始}首先我们要判断一下这个域名是不是博客主域名,不然瞎拦截到其他地方可不好:
if(domain === "blog.cyfan.top"){//这里写你需要拦截的域名 //从这里开始处理}我们还要记得给url进行提前处理,剥离出路径,去除参数。在这其中尤其要注意的是默认路由的处理。
通常情况下我们访问一个网址,web服务器会在后面添加.html后缀。对于一个默认路径则是index.html。
还要注意的是剥离#,不然又会获取失败。
定义一个fullpath函数,用于预处理和剥离路径:
const fullpath = (path) => { path = path.split('?')[0].split('#')[0] if (path.match(/\/$/)) { path += 'index' } if (!path.match(/\.[a-zA-Z]+$/)) { path += '.html' } return path}结果类似于:
> fullpath('/')'/index.html'> fullpath('/p/1')'/p/1.html'> fullpath('/p/1?q=1234')'/p/1.html'> fullpath('/p/1.html#QWERT')'/p/1.html'然后再定义一个镜像并发函数,用于生成待获取的网址:
const generate_blog_urls = (packagename, blogversion, path) => { const npmmirror = [ `https://unpkg.com/${packagename}@${blogversion}/public`, `https://npm.elemecdn.com/${packagename}@${blogversion}/public`, `https://cdn.jsdelivr.net/npm/${packagename}@${blogversion}/public`, `https://npm.sourcegcdn.com/npm/${packagename}@${blogversion}/public`, `https://cdn1.tianli0.top/npm/${packagename}@${blogversion}/public` ] for (var i in npmmirror) { npmmirror[i] += path } return npmmirror}接下来我们将其填入主路由中:
if(domain === "blog.cyfan.top"){//这里写你需要拦截的域名 return lfetch(generate_blog_urls('chenyfan-blog','1.1.4',fullpath(urlPath)))}然而谨记,npm返回的文件格式通常是text而非html,所以我们还要进一步处理header。处理也简单,连环then下去就行:
if(domain === "blog.cyfan.top"){ return lfetch(generate_blog_urls('chenyfan-blog','1.1.4',fullpath(urlPath))) .then(res=>res.arrayBuffer())//arrayBuffer最科学也是最快的返回 .then(buffer=>new Response(buffer,{headers:{"Content-Type":"text/html;charset=utf-8"}}))//重新定义header}那么接下来,除了首屏以外,你的网站相当于托管在全球(包括中国)各个主流cdn服务器中,提速效果无与伦比.如果你将原网站托管在cf,那么你将获得一个打不死,国内加载速度超快(首屏除外)的网站。
解放双手 - npm版本自定义更新
有人会问了,我为什么不能直接用latest来获取最新版本,还要手动指定?
简单地说,在生产环境中用@latest指定最新版本是一个很不合理、且非常愚蠢的操作。你永远都不知道对面的缓存什么时候清除,获取到的可能是一年前的版本。
为了节约成本,避免回源,cdn服务商通常会缓存资源,尤其是那些静态资源。以jsd为例,其latest缓存为7天,不过可以手动刷新。unpkg cf边缘2星期,eleme已经将近6个月没更新了。至于那些自建的。你根本搞不懂他什么时候更新,使用latest会导致随机获取到版本,接近无法正常使用。
而指定版本的,cdn通常会永久缓存。毕竟版本定死了东西是不会变的,而请求指定版本的cdn也可以或多或少提升访问速度,因为文件时永久缓存的,HIT的热度比较高。
sw端
利用npm registry获取最新版本,其官方endpoint如下:
https://registry.npmjs.org/chenyfan-blog/latest其version字段即最新版本。
npm registry的镜像也不少,以腾讯/阿里为例:
https://registry.npmmirror.com/chenyfan/latest #阿里,可手动同步https://mirrors.cloud.tencent.com/npm/chenyfan/latest #腾讯,每日凌晨同步获取最新版本也不难:
const mirror = [ `https://registry.npmmirror.com/chenyfan-blog/latest`, `https://registry.npmjs.org/chenyfan-blog/latest`, `https://mirrors.cloud.tencent.com/npm/chenyfan-blog/latest`]const get_newest_version = async (mirror) => { return lfetch(mirror, mirror[0]) .then(res => res.json()) .then(res.version)}在这里还有一个坑点:ServiceWorker的全局变量会在所有页面关闭后销毁。下次启动时会优先响应handle,其定义变量要在handle响应后才会执行。因此,对于最新版本的存储,不能直接定义变量,需要持久化,这里另辟蹊径,采用CacheStorage存储:
self.db = { //全局定义db,只要read和write,看不懂可以略过 read: (key, config) => { if (!config) { config = { type: "text" } } return new Promise((resolve, reject) => { caches.open(CACHE_NAME).then(cache => { cache.match(new Request(`https://LOCALCACHE/${encodeURIComponent(key)}`)).then(function (res) { if (!res) resolve(null) res.text().then(text => resolve(text)) }).catch(() => { resolve(null) }) }) }) }, write: (key, value) => { return new Promise((resolve, reject) => { caches.open(CACHE_NAME).then(function (cache) { cache.put(new Request(`https://LOCALCACHE/${encodeURIComponent(key)}`), new Response(value)); resolve() }).catch(() => { reject() }) }) }}const set_newest_version = async (mirror) => { //改为最新版本写入数据库 return lfetch(mirror, mirror[0]) .then(res => res.json()) //JSON Parse .then(async res => { await db.write('blog_version', res.version) //写入 return; })}setInterval(async() => { await set_newest_version(mirror) //定时更新,一分钟一次}, 60*1000);setTimeout(async() => { await set_newest_version(mirror)//打开五秒后更新,避免堵塞},5000)再将上面的生成urls从:
generate_blog_urls('chenyfan-blog','1.1.4',fullpath(urlPath))改为
//若第一次没有,则使用初始版本1.1.4,或者你也可以改成latest(不推荐)generate_blog_urls('chenyfan-blog',await db.read('blog_version') || '1.1.4',fullpath(urlPath))此后用户加载时,会尽可能的获取最新版本,无需手动更新。
ci端
有了前端自动更新,我们在上传包的时候还要手动更新package.json中的version字段。其实这里也可以直接交给ci处理。
然而需要注意,npm version patch 虽然能更新z位数版本,但其更新不会上传到仓库。换句话说,这只能上传一次。因此这个地方我干脆建议用随机数,反正通过api获得的latest都是最新的上传。
案例代码这里不展示,实际上这一步做起来也不难。
调剂响应
缓存 - 互联网上一伟大发明
虽然我也不清楚有一小部分人对那么丁点CacheStorage缓存占用那么敏感,但至少,缓存对网站加载速度的提升有极大的帮助。
通常,有大量的资源是访问一个网站重复需要的,对于这些东西,浏览器会自带MemoryCache或DiskCache,但这一类缓存不是持久的,在下一次打开网站的时候缓存不一定生效。而CacheStorage是浏览器自带的缓存桶(Key/Value),这种桶是持久存储,长期有效,而sw是能控制这桶。
而不同的网域资源所应当采取的缓存策略也是不一样的。对于确定版本的静态资源,直接终生缓存;对于有时限的静态资源,应当不缓存或只缓存一小段时间。
CacheStorage不是sw专属的,你可以在前端和sw中同时控制它,这是几分样例代码:
const CACHE_NAME = 'cache-v1'; //定义缓存桶名称caches.open(CACHE_NAME).then(async function (cache) { const KEYNAME = new Request('https://example.com/1.xxx') //定义KEY,[Object Request] await cache.put(KEYNAME, new Response('Hello World')); //自定义填入 await cache.match(KEYNAME).then(async function (response) { console.log(await response.text()); //匹配并输出 }) await cache.put(KEYNAME, await fetch('https://example.com/2.xxx').then(res=>res.arrayBuffer())); //使用fetch填入缓存 await cache.matchAll().then(function (responses) { //列出所有(也可以根据内容列出指定的项 for (let response of responses) { console.log(response.url); } }) await cache.delete(KEYNAME) //删除指定项});SetTimeout - 毫秒级调控响应
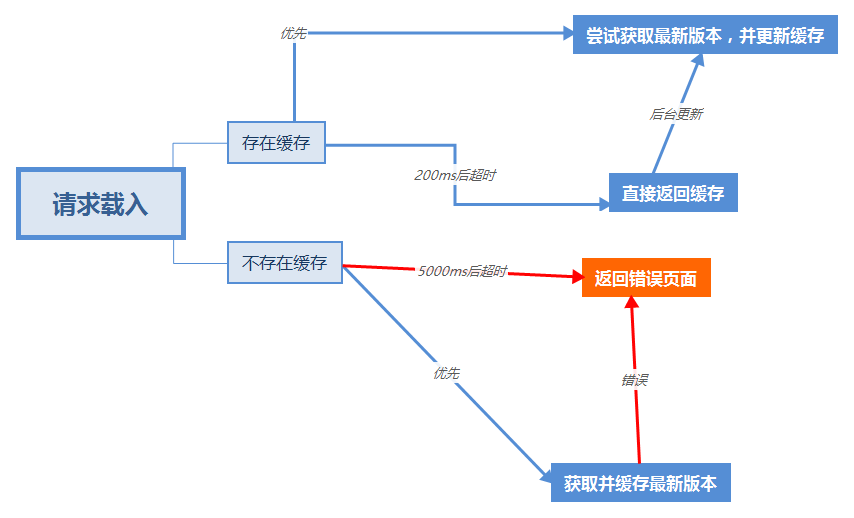
对于同一个网页,你需要合理的对他执行决策树,这是目前我的博客[网页]采取的决策树:
![]()
js里有两个对时间控制的古老函数:SetTimeout和SetInterval.在这里我采用SetTimeout,同时并行执行任务.
这里采用代码片段比较容易解释:
if (请求的网址是博客) { //这里一定要用Promise,这样在之后settimeout就不需要回调,直接Resolve return new Promise(function (resolve, reject) { setTimeout(async () => { if (存在缓存) { setTimeout(() => { resolve(获取当前页面缓存(请求)) }, 200);//200ms表示下面的拉取失败后直接返回缓存,但下面的拉取不会被踢出,更新会在后台执行,会填入缓存,但也不会返回 setTimeout(() => { resolve( 拉取最新版本的网页(请求) .then(填入缓存并返回内容)//返回缓存 ) }, 0);//表示立刻执行,优先级最高 } else { setTimeout(() => { resolve( 拉取最新版本的网页(请求) .then(填入缓存并返回内容)//返回缓存 ) }, 0);//表示立刻执行,优先级最高 setTimeout(() => { resolve(返回错误提示()) }, 5000)//5000ms后如果没有返回最新内容就直接返回错误提示,如果成功了此次返回是无效的 } }, 0)//这里需要一个大settimeout包裹以便于踢出主线程,否则无法并行处理 })}优化首屏
window.stop - 与死神擦肩而过
事实上,ServiceWorker最显著的缺点是要在第一次加载网页安装后,刷新一次才能激活。即访客第一次访问是不受sw控制的。换句话说,访客首屏不受加速,其加载速度与你的服务器有直接联系 [虽然安装完成后就起飞了,但安装前就是屑]。
而本人未成年,浙江的规定又是未成年不得备案,在加上之后备案主题切换异常的麻烦。我的决定是至少高考前都不会备案。那这后果就很直接,我并不能使用国内的cdn节点。再加上我又没这个经济实力用香港CN2或拉iplc专线,对首屏服务器这一块优化其实能做的很少。
更加令人抓狂的是,在首屏加载时,静态资源会被直接获取,并且不缓存,而sw激活后又会强制第二次获取,拉跨速度。
不过我们可以尽可能弱化这一劣势。我们可以用js打断所有的请求,以确保首屏只加载一个html和一个sw.js,其余资源都不会加载,降低首屏加载延迟。
我们尽可能将打断代码提到<head> 以确保不被其他资源堵塞,对于hexo来说打开主题的head.ejs,在<head>标签靠前的位置中加入:
(async () => {//使用匿名函数确保body已载入 /* ChenBlogHelper_Set 存储在LocalStorage中,用于指示sw安装状态 0 或不存在 未安装 1 已打断 2 已安装 3 已激活,并且已缓存必要的文件(此处未写出,无需理会) */ const $ = document.querySelector.bind(document);//语法糖 if ('serviceWorker' in navigator) { //如果支持sw if (Number(window.localStorage.getItem('ChenBlogHelper_Set')) < 1) { window.localStorage.setItem('ChenBlogHelper_Set', 1) window.stop() document.write('Wait') } navigator.serviceWorker.register(`/sw.js?time=${ranN(1, 88888888888888888888)}`)//随机数,强制更新 .then(async () => { if (Number(window.localStorage.getItem('ChenBlogHelper_Set')) < 2) { setTimeout(() => { window.localStorage.setItem('ChenBlogHelper_Set', 2) //window.location.search = `?time=${ranN(1, 88888888888888888888)}` //已弃用,在等待500ms安装成功后直接刷新没有问题 window.location.reload()//刷新,以载入sw }, 500)//安装后等待500ms使其激活 } }) .catch(err => console.error(`ChenBlogHelperError:${err}`)) }})()当然了,这回导致白屏500ms,如果你觉得不好看,也可以和我一样载入一个等待界面,将document.write()改为:
document.body.innerHTML = await (await fetch('https://npm.elemecdn.com/chenyfan-blog@1.0.13/public/notice.html')).text()即可
![]()
主服务器优化 - 绝望中的最后一根稻草
实际上我一直以为,主服务器的优化在整个网站中是最必要的,也是最不重要的。必要的原因是它关系到最初的加载速度,也是访客中最主要的一环;不重要的是相对于静态资源的记载、页面的渲染和脚本的编译,首屏的加载对整体效果太小了。
尤其是在sw托管后,之后的所有访问,除了sw的更新(以及所有镜像源全炸后),基本与主服务器脱离了关系,正常访问与其没有关系。加速源站实则没有必要。
当然,你说有用吗,那肯定还有点用处,至少首次加载不至于卡人心态。我的要求很简单,能在600ms内完成首次html下载的基本就没问题了。
最优的无非是香港CN2,不过我们没这个能力。退而求其次,普通的香港服务器我们也能接受。不过依旧是白嫖至上的念头,我才用了Vercel。Vercel也是可以自选节点(主要是亚马逊和谷歌)的,我稍加测试【主要注重可连接性,其次是延迟。丢包和速度作为建站(尤其只有一个10kb的网页)最次】,决定使用一下策略:
电信 104.199.217.228 【台北 谷歌Cloud】 70ms (绕新加坡 但是是质量最好的)联通 18.178.194.147 【日本 亚马逊】 45ms (4837和aws在tyo互联)移动 18.162.37.140 【香港 谷歌Cloud】 60ms (移动去香港总是最好的选择)在这里,不推荐其他地区的理由是:
电信:基本上除了台北,去GoogleCloud的都是走日本ntt × ; 亚马逊这一块有大部分绕美,去日本延迟异常的大。
联通:去香港的绕美了,去日本这一条存在这直接的互联点,负载比较小,延迟也不错。
移动:没什么好说的,移动互联除了去亚太的都是垃圾。
后记
一张思维导图总结全文,你学废了吗?
![]()