说说 Redis pipeline
Redis 客户端和服务端之间是采用 TCP 协议进行通信的,是基于 Request/Response 这种一问一答的模式,即请求一次响应一次。
普通模式
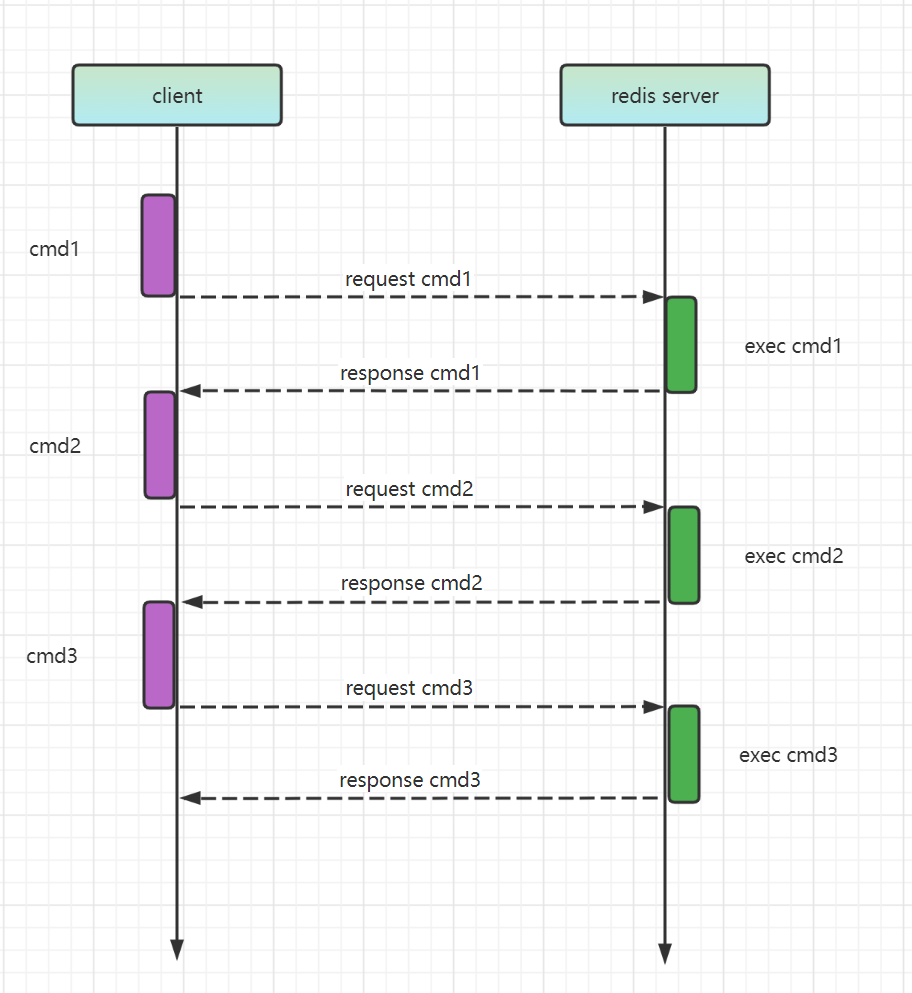
我们先来看下普通模式下,一条 Redis 命令的简要执行过程:
- 客户端发送一条命令给 redis-server,阻塞等待 redis-server 应答
- redis-server 接收到命令,执行命令
- redis-server 将结果返回给客户端
![]()
下面我们来简要了解下一个完整请求的交互过程。
![]()
- 客户端调用 write () 将消息写入操作系统为 socket 分配的 send buffer 中
- 操作系统将 send buffer 中的内容发送到网卡,网卡通过网关路由把内容发送到服务器网卡
- 服务器网卡将接受到的消息写入操作系统为 socket 分配的 recv buffer
- 服务器进程调用 read () 从 recv buffer 中读取消息进行处理
- 处理完成之后,服务器调用 write () 将响应内容发送的 send buffer 中
- 服务器将 send buffer 中的内容通过网卡,发送到客户端
- 客户端操作系统将网卡中的内容放入 recv buffer 中
- 客户端进程调用 read () 从 recv buffer 中读取消息
普通模式的问题
我们来想一下,这种情况下可能导致什么问题。
如果同时执行大量的命令,那对于每一个命令,都要按上面的流程走一次,当前的命令需要等待上一条命令执行应答完毕之后,才会执行。这个过程中会有多次的 RTT ,也还会伴随着很多的 IO 开销,发送网络请求等。每条命令的发送和接收的过程都会占用两边的网络传输。
简单的来说,每个命令的执行时间 = 客户端发送耗时 + 服务器处理耗时 + 服务器返回耗时 + 一个网络来回耗时。
在这里,一个网络来回耗时(RTT) 是不好控制的,也是不稳定的。它的影响因素很多,比如客户端到服务器的网络线路是否拥堵,经过了多少跳。还有就是 IO 系统调用也是耗时的,一个 read 系统调用,需要从用户态,切换到内核态。上文我们讲述一个命令的请求过程时多次降到 read 和 write 系统调用。
可以说一个命令的执行时间,很大程度上受到它们的限制。
pipeline 模式
有没有什么方法来解决这种问题呢。
第一种方法,就是利用多线程机制,并行执行命令。
第二种方法,调用批量命令,例如 mget 等,一次操作多个键。
很多时候我们要执行的命令并不是一样的命令,而是一组命令,这个时候就无法使用类似 mget 这样的批量命令了。那还有其他的方法吗?
回想一下,我们初学编程的时候,老手都会告诉我们,不要在循环里面做查询。我有一个 books 列表数据,要根据 book_id 查询它们的 price,如果我们循环 books 列表,在每次循环里面取查询单个 book_id 的 price,那性能肯定是不理想的。一般我们的优化方式是将多个 book_id 取出来,一次性去查多个 book_id 的 price,这样性能就有明显的提示。即将多次小命令中的耗时操作合并到一次,从而减少总的执行时间。
类似的,Redis pipeline 出现了,一般称之为管道。它允许客户端一次可以发送多条命令,而不用像普通模式那样每次执行一个小命令都要等待前一个小命令执行完,服务器在接收到一堆命令后,会依次执行,然后把结果打包,再一次性返回给客户端。
这样可以避免频繁的命令发送,减少 RTT,减少 IO 调用次数 。前面已经介绍了,IO 调用会涉及到用户态和内核态之间的切换,在高性能的一些系统中,我们都是尽可能的减少 IO 调用。
简要流程如下图:
![]()
pipeline 的优点
- 减少 RTT
- 减少 IO 调用次数
基本使用
1
2
3
4
5
6
7Pipeline pipeline =jedis.pipelined();
for(int i = 0; i < 100; i++){
pipeline.rpush("rediskey", i + "");
}
pipeline.sync()总结一下 pipeline 的核心,就是
客户端将一组 Redis 命令进行组装,通过一次 RTT 发送给服务器,同时服务器再将这组命令的执行结果按照顺序一次返回给客户端。
pipeline 注意问题
虽然 pipeline 在某些情况下会带来不小的性能提升,但是,我们在使用的时候也需要注意。
- pipeline 中的命令数量不宜过多。
客户端会先将多个命令写入内存 buffer 中(打包),命令过多,如果是超过了客户端设置的 buffer 上限,被客户端的处理策略处理了(不同的客户端实现可能会有差异,比如 jedis pipeline ,限制每次最大的发送字节数为 8192,缓冲区满了就发送,然后再写缓冲,最后才处理 Redis 服务器的应答)。如果客户端没有设置 buffer 上限或不支持上限设置,则会占用更多的客户端机器内存,造成客户端瘫痪。官方推荐是每次 10k 个命令。
建议做好规范,遇到一次包含大量命令的 pipeline,可以拆分成多个稍小的 pipeline 来完成。
- pipeline 一次只能运行在一个 Redis 节点上,一些集群或者 twemproxy 等中间件使用需要注意。
在集群环境下,一次 pipeline 批量执行多个命令,每个命令需要根据 key 计算槽位,然后根据槽位去特定的节点上去执行命令,这样一次 pipeline 就会使用多个节点的 redis 连接,这种当前也是不支持的。
- pipeline 不保证原子性,如要求原子性,不建议使用 pipeline
它仅是将多个命令打包发送出去而已,如果中间有命令执行异常,也会继续执行剩余命令。
pipeline 与批量操作 mget 等区别
其实 meget 和 pipeline 优化的方向是一致的,即多个命令打包一次发送,减少网络时间。但是也是有区别的。
mget等的场景是一个命令对应多个键值对,而 pipeline 一般是多条命令(不同的命令)mget操作是一个原子操作,而 pipeline 不是原子操作mget是服务端实现,而 pipeline 是客户端和服务端共同实现
pipeline 与事务的区别
这两者关注和解决的问题不是一个东西,原理也不一样。
- pipeline 是一次请求,服务端顺序执行,一次返回。而事务是多次请求(先 multi,再多个操作命令,最后 exec),服务端顺序执行,一次返回
- pipeline 关注的是 RTT 时间和 IO 调用,事务关注的是一致性问题
总结
本文主要讲了多命令执行时耗时问题,以及 pipeline 的解决方法,和其简单的原理,以及注意点。今天的学习就到这里,改天我们接着肝。