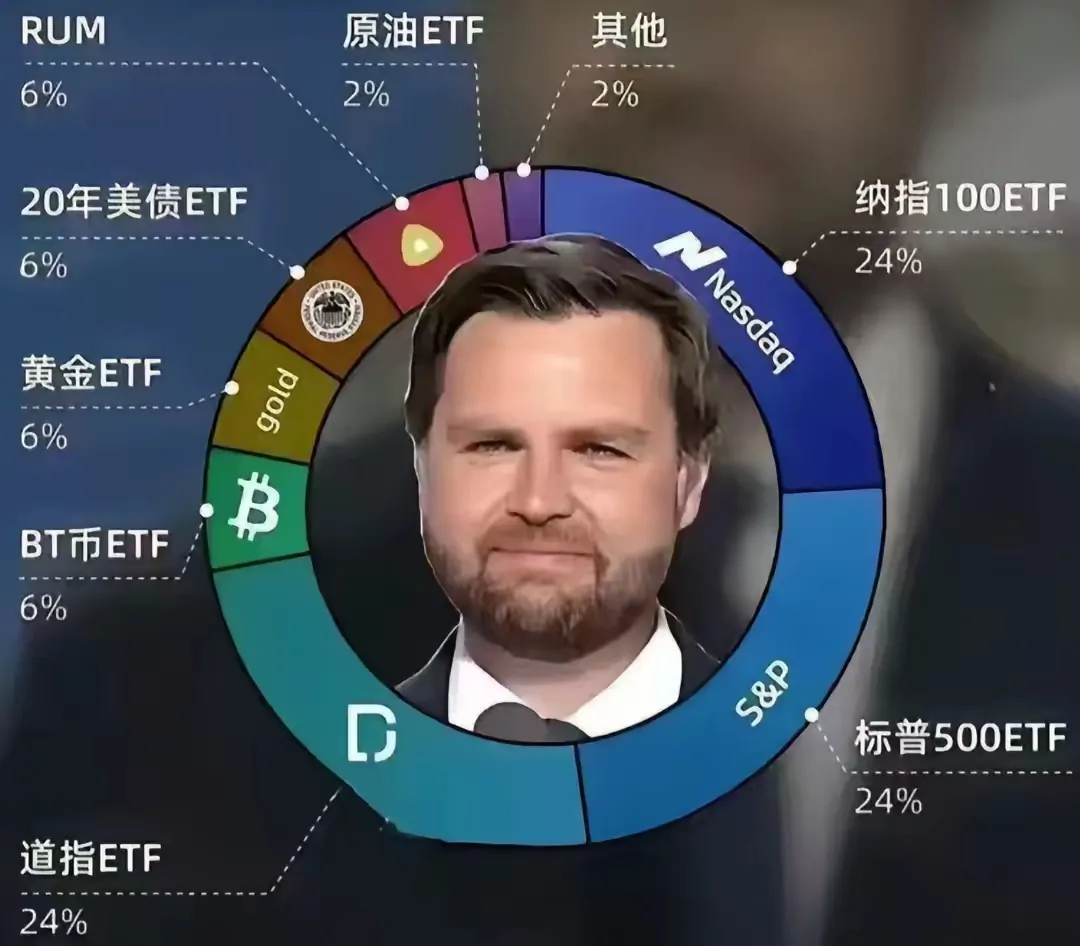
graph TD
A[印刷时代政治传播体系] --> B[精英主导]
A --> C[地理局限]
A --> D[延迟性传播]
A --> E[党派媒体]
B --> B1["报纸所有权集中<br>普通公民无发声渠道"]
C --> C1["受制于物理发行网络<br>各地区认知差异巨大"]
D --> D1["事件数日至数周后<br>才能被广泛知晓"]
E --> E1["读者按党派选择媒体<br>奠定两党信息生态"]
E1 --> F["🏆 历史遗产:竞选管理成为专业行业"]
B1 --> F
graph TD
A["🎙️ 1960年总统辩论直播"] --> B["📻 广播听众"]
A --> C["📺 电视观众"]
B --> D["✅ 认为尼克松获胜<br>论点严密 · 政策细节充分"]
C --> E["✅ 认为肯尼迪获胜<br>形象自信 · 肤色健康 · 西装得体"]
D --> F["同一场辩论<br>两种截然不同的感知现实"]
E --> F
F --> G["📊 结论:电视观众支持肯尼迪比例<br>显著高于广播听众"]
G --> H["🏆 肯尼迪以微弱差距赢得大选<br>媒介形象首次决定选举结果"]
style D fill:#bbdefb
style E fill:#c8e6c9
style H fill:#fff9c4
flowchart TD
A["🏛️ 奥巴马2008数字竞选体系"] --> B["my.barackobama.com<br>数字竞选中枢"]
B --> C["📱 社交网络整合<br>Facebook · MySpace · YouTube"]
B --> D["🤝 志愿者动员网络"]
B --> E["💰 线上募款系统"]
B --> F["🗺️ 选区精准组织"]
B --> G["📊 选民数据分析"]
C --> C1["Facebook粉丝 200万+<br>麦凯恩的10倍"]
D --> D1["300万人注册志愿者"]
E --> E1["网络募款总额 5亿美元<br>1/3 来自小额捐款"]
F --> F1["精准识别摇摆选民"]
G --> G1["为2012大数据竞选<br>奠定基础"]
style A fill:#1565c0,color:#fff
style B fill:#1976d2,color:#fff
graph LR
A["⚡ 极端 / 情绪化内容<br>愤怒·恐惧·道德义愤"] -->|"触发高互动"| B["🤖 算法检测<br>高互动率 = 优质内容"]
B -->|"大规模推送"| C["👥 更广泛用户接触"]
C -->|"引发情绪反应<br>点赞·评论·转发"| D["📈 互动数据飙升"]
D -->|"正反馈信号"| B
D -->|"强化内容偏好"| A
B -.->|"系统性后果"| E["🌀 信息茧房<br>情绪极化"]
style A fill:#ef5350,color:#fff
style B fill:#7e57c2,color:#fff
style D fill:#ef5350,color:#fff
style E fill:#b71c1c,color:#fff
graph TD
A["🤖 AI时代政治传播威胁"] --> B["深度伪造<br>Deepfake"]
A --> C["超个性化操控"]
A --> D["AI生成虚假信息<br>规模化传播"]
B --> E["眼见不再为实<br>信任基础崩塌"]
C --> F["每个选民收到<br>量身定制的操控内容"]
D --> G["真假信息难以<br>实时辨别"]
E --> H["🛡️ 制度应对"]
F --> H
G --> H
H --> I["欧盟AI法案<br>强制标注AI内容"]
H --> J["深度伪造检测<br>技术标准"]
H --> K["公民媒介素养<br>教育提升"]
K --> L["🌱 民主韧性<br>识别操控·批判性思考"]
style A fill:#b71c1c,color:#fff
style H fill:#1565c0,color:#fff
style L fill:#2e7d32,color:#fff
graph TD
A["🏛️ 民主制度的<br/>结构性数学困境"] --> B["阿罗不可能定理<br/>不存在完美的<br/>集体偏好聚合机制"]
A --> C["公共选择理论<br/>政治家首先是<br/>追求自利的理性人"]
A --> D["中位数选民定理<br/>政策趋向平庸<br/>而非最优"]
A --> E["奥尔森集体行动困境<br/>组织化少数<br/>压倒分散多数"]
B --> F["无论何种投票制度<br/>总存在不一致性"]
C --> G["公共利益只是<br/>实现私利的工具"]
D --> H["好政策失选票<br/>坏政策有市场"]
E --> I["游说政治<br/>利益集团俘获"]
F & G & H & I --> J["🎯 AI治理的出发点:<br/>以算法替代人类决策者<br/>规避上述四重陷阱"]
style A fill:#1a1a2e,color:#e0e0e0,stroke:#4a90d9
style J fill:#16213e,color:#e0e0e0,stroke:#e94560
style B fill:#0f3460,color:#e0e0e0,stroke:#4a90d9
style C fill:#0f3460,color:#e0e0e0,stroke:#4a90d9
style D fill:#0f3460,color:#e0e0e0,stroke:#4a90d9
style E fill:#0f3460,color:#e0e0e0,stroke:#4a90d9
flowchart TD
A["🎯 国家AI系统识别政策目标<br/>例:将某社区骑行率提升20%<br/>以实现碳排放目标"]
A --> B["📊 分析社区数据<br/>居民出行习惯·距离分布<br/>现有交通偏好·心理画像"]
B --> C{"选择干预方式"}
C --> D["🚲 环境设计<br/>骑行道优先维护<br/>共享单车站点密集化"]
C --> E["📱 信息框架<br/>推送'您的邻居68%本周骑行'<br/>社会规范的激活"]
C --> F["💰 微激励<br/>骑行者社区评分微幅加权<br/>间接影响服务获取优先级"]
C --> G["🔕 摩擦成本<br/>驾车停车变得略微不便<br/>公共交通信号灯略微不利于私家车"]
D & E & F & G --> H["✅ 公民'自由选择'骑行<br/>(无任何强制)"]
H --> I{"本质是什么?"}
I --> J["🔓 消极自由保留<br/>没有人被禁止开车"]
I --> K["🔒 积极自由被侵蚀<br/>选择的成本结构<br/>被悄悄重新设计了"]
J & K --> L["⚠️ 塞勒'助推'在国家层面的质变:<br/>商业平台助推 → 单一产品选择<br/>国家AI助推 → 整个生命结构"]
style A fill:#1a1a2e,color:#e0e0ff,stroke:#7b68ee
style H fill:#1a3a1a,color:#dfd,stroke:#52b788
style L fill:#3a1a00,color:#ffe,stroke:#f4a261,stroke-width:2px
style K fill:#4a0e0e,color:#fdd,stroke:#e94560
graph LR
A["🏚️ A群体历史上<br/>处于弱势"] -->|编码进| B["📉 历史数据中<br/>A群体指标偏低"]
B -->|AI学习| C["🤖 AI系统评估<br/>A群体成员潜力偏低"]
C -->|导致| D["📦 A群体获得的<br/>资源和机会减少"]
D -->|造成| E["📊 A群体下一代<br/>指标进一步偏低"]
E -->|进入| B
C -->|直接影响| F["❌ 职业推荐低薪岗位<br/>教育资源分配减少<br/>司法裁量系统性偏差"]
NOTE["⚠️ 与传统歧视的关键差异:<br/>传统歧视 → 可被社会运动·法律·舆论挑战<br/>算法歧视 → '数据说话'的修辞剥夺了<br/>最有效的反驳工具"]
F --> NOTE
style A fill:#3a1a1a,color:#fdd,stroke:#e94560
style B fill:#2a1a00,color:#ffe,stroke:#f4a261
style C fill:#0f1a2e,color:#dde,stroke:#4a90d9
style D fill:#1a2a1a,color:#dfd,stroke:#52b788
style E fill:#3a1a1a,color:#fdd,stroke:#e94560
style NOTE fill:#2a2a00,color:#ffd,stroke:#gold,stroke-width:2px
linkStyle 0,1,2,3,4 stroke:#e94560,stroke-width:2px
-- 连接PostgreSQL
sudo -u postgres psql
-- 创建用户
CREATE USER myuser WITH PASSWORD 'securepassword';
-- 创建数据库
CREATE DATABASE mydb OWNER myuser;
-- 授予权限
GRANT ALL PRIVILEGES ON DATABASE mydb TO myuser;
三、数据库基础操作
表操作
-- 创建表
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE,
department VARCHAR(50),
salary NUMERIC(10,2),
hire_date DATE DEFAULT CURRENT_DATE,
skills TEXT[]
);
-- 修改表
ALTER TABLE employees ADD COLUMN phone VARCHAR(15);
ALTER TABLE employees ALTER COLUMN department SET NOT NULL;
-- 删除表
DROP TABLE IF EXISTS temp_employees;
数据操作(CRUD)
-- 插入数据
INSERT INTO employees (name, email, department, salary)
VALUES
('张伟', 'zhang@company.com', '研发部', 15000),
('李娜', 'li@company.com', '市场部', 12000);
-- 查询数据
SELECT * FROM employees WHERE department = '研发部' AND salary > 13000;
-- 更新数据
UPDATE employees SET salary = salary * 1.1 WHERE department = '研发部';
-- 删除数据
DELETE FROM employees WHERE id = 5;
事务管理
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
-- 提交事务
COMMIT;
-- 出错时回滚
ROLLBACK;
四、数据类型详解
PostgreSQL提供丰富的数据类型:
类别
数据类型
描述
数值
SMALLINT, INTEGER, BIGINT
整数类型
NUMERIC(precision, scale)
精确小数
REAL, DOUBLE PRECISION
浮点数
字符
VARCHAR(n), TEXT
变长字符串
CHAR(n)
定长字符串
日期/时间
DATE, TIME, TIMESTAMP
日期时间类型
布尔
BOOLEAN
true/false
二进制
BYTEA
二进制数据
几何
POINT, LINE, CIRCLE
几何图形
网络
INET, CIDR, MACADDR
网络地址
JSON
JSON, JSONB
JSON数据
数组
INT[], TEXT[]
数组类型
范围
INT4RANGE, TSRANGE
范围类型
JSONB示例:
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
attributes JSONB
);
INSERT INTO products (name, attributes)
VALUES ('Laptop', '{"color": "silver", "memory": "16GB", "ports": ["USB-C", "HDMI"]}');
-- 查询JSON字段
SELECT name, attributes->>'color' AS color
FROM products
WHERE attributes @> '{"memory": "16GB"}';
五、高级查询技术
窗口函数
SELECT
name,
department,
salary,
AVG(salary) OVER (PARTITION BY department) AS avg_dept_salary,
RANK() OVER (ORDER BY salary DESC) AS salary_rank
FROM employees;
CTE(公共表表达式)
WITH regional_sales AS (
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
),
top_regions AS (
SELECT region
FROM regional_sales
WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales)
)
SELECT region, product, SUM(quantity) AS product_units
FROM orders
WHERE region IN (SELECT region FROM top_regions)
GROUP BY region, product;
全文搜索
-- 创建全文搜索索引
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT,
body TEXT
);
CREATE INDEX idx_documents_search ON documents USING GIN (to_tsvector('english', body));
-- 执行搜索
SELECT title, ts_headline(body, q) AS highlight
FROM documents, to_tsquery('english', 'database & performance') q
WHERE to_tsvector('english', body) @@ q;
六、索引与性能优化
索引类型
索引类型
适用场景
示例
B-tree
默认索引,适用于等值查询和范围查询
CREATE INDEX idx_name ON table (column)
Hash
等值查询(仅内存表)
CREATE INDEX idx_name ON table USING HASH (column)
GIN
JSONB、数组、全文搜索
CREATE INDEX idx_gin ON table USING GIN (jsonb_column)
GiST
几何数据、全文搜索
CREATE INDEX idx_gist ON table USING GiST (geom_column)
SP-GiST
空间分区数据
CREATE INDEX idx_spgist ON table USING SP-GiST (phone)
BRIN
大型表,按物理顺序存储
CREATE INDEX idx_brin ON table USING BRIN (timestamp)
查询优化技巧
使用EXPLAIN分析
EXPLAIN ANALYZE SELECT * FROM large_table WHERE category_id = 10;
**避免SELECT ***
-- 不推荐
SELECT * FROM orders;
-- 推荐
SELECT order_id, customer_id, order_date FROM orders;
批量操作优化
-- 使用COPY导入数据
COPY large_table FROM '/path/to/data.csv' DELIMITER ',' CSV HEADER;
分区表
-- 创建分区表
CREATE TABLE sales (
id SERIAL,
sale_date DATE,
amount NUMERIC
) PARTITION BY RANGE (sale_date);
-- 创建子分区
CREATE TABLE sales_2023 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
七、事务与并发控制
事务隔离级别
-- 查看当前隔离级别
SHOW default_transaction_isolation;
-- 设置隔离级别
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
锁机制
-- 显式锁定
BEGIN;
LOCK TABLE accounts IN EXCLUSIVE MODE;
-- 执行操作
COMMIT;
-- 行级锁
SELECT * FROM orders WHERE id = 100 FOR UPDATE;
MVCC(多版本并发控制)
PostgreSQL使用MVCC处理并发,避免读写冲突:
stateDiagram-v2
[*] --> Active
Active --> Committed
Active --> Aborted
Committed --> [*]
Aborted --> [*]
八、存储过程与函数
PL/pgSQL函数
CREATE OR REPLACE FUNCTION calculate_tax(amount NUMERIC)
RETURNS NUMERIC AS $$
DECLARE
tax_rate NUMERIC := 0.1;
tax_amount NUMERIC;
BEGIN
tax_amount := amount * tax_rate;
RETURN tax_amount;
EXCEPTION
WHEN division_by_zero THEN
RAISE NOTICE 'Division by zero occurred';
RETURN 0;
END;
$$ LANGUAGE plpgsql;
-- 调用函数
SELECT calculate_tax(1000);-- 返回100.00
返回结果集
CREATE OR REPLACE FUNCTION get_employees(dept_name VARCHAR)
RETURNS TABLE (id INT, name VARCHAR, salary NUMERIC) AS $$
BEGIN
RETURN QUERY
SELECT e.id, e.name, e.salary
FROM employees e
WHERE e.department = dept_name;
END;
$$ LANGUAGE plpgsql;
-- 调用
SELECT * FROM get_employees('研发部');
九、触发器与规则
创建触发器
-- 审计日志表
CREATE TABLE audit_log (
id SERIAL PRIMARY KEY,
table_name VARCHAR(100),
action VARCHAR(10),
old_data JSONB,
new_data JSONB,
change_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 触发器函数
CREATE OR REPLACE FUNCTION log_employee_changes()
RETURNS TRIGGER AS $$
BEGIN
IF (TG_OP = 'DELETE') THEN
INSERT INTO audit_log (table_name, action, old_data)
VALUES (TG_TABLE_NAME, 'DELETE', to_jsonb(OLD));
ELSIF (TG_OP = 'UPDATE') THEN
INSERT INTO audit_log (table_name, action, old_data, new_data)
VALUES (TG_TABLE_NAME, 'UPDATE', to_jsonb(OLD), to_jsonb(NEW));
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO audit_log (table_name, action, new_data)
VALUES (TG_TABLE_NAME, 'INSERT', to_jsonb(NEW));
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
-- 创建触发器
CREATE TRIGGER employees_audit
AFTER INSERT OR UPDATE OR DELETE ON employees
FOR EACH ROW EXECUTE FUNCTION log_employee_changes();
-- 基本查询
SELECT * FROM employees;
-- 条件查询
SELECT name, salary
FROM employees
WHERE department = '技术部' AND salary > 14000;
-- 排序与分页
SELECT * FROM employees
ORDER BY hire_date DESC
LIMIT 5 OFFSET 0;
-- 模糊查询
SELECT * FROM employees
WHERE name LIKE '张%' OR email LIKE '%@company.com';
更新数据
-- 更新单条记录
UPDATE employees
SET salary = salary * 1.1
WHERE id = 1;
-- 批量更新
UPDATE employees
SET department = '研发部'
WHERE department = '技术部';
删除数据
-- 删除单条记录
DELETE FROM employees
WHERE id = 5;
-- 清空表数据
TRUNCATE TABLE temp_employees;
🔗 四、高级查询技巧
多表连接
-- 创建部门表
CREATE TABLE departments (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
location VARCHAR(100)
);
-- 内连接
SELECT e.name, e.salary, d.name AS dept_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.id;
-- 左连接
SELECT e.name, d.name AS dept_name
FROM employees e
LEFT JOIN departments d ON e.department_id = d.id;
聚合函数
-- 基本聚合
SELECT
COUNT(*) AS total_employees,
AVG(salary) AS avg_salary,
MAX(salary) AS max_salary,
MIN(hire_date) AS oldest_hire
FROM employees;
-- 分组统计
SELECT
department,
COUNT(*) AS employee_count,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department
HAVING COUNT(*) > 3;
子查询
-- 单行子查询
SELECT name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
-- IN子查询
SELECT name
FROM employees
WHERE department_id IN (
SELECT id
FROM departments
WHERE location = '北京'
);
-- EXISTS子查询
SELECT d.name
FROM departments d
WHERE EXISTS (
SELECT 1
FROM employees e
WHERE e.department_id = d.id
);
⚡ 五、索引与性能优化
索引类型
-- 创建普通索引
CREATE INDEX idx_email ON employees(email);
-- 创建唯一索引
CREATE UNIQUE INDEX uidx_email ON employees(email);
-- 创建复合索引
CREATE INDEX idx_dept_salary ON employees(department, salary);
-- 查看索引
SHOW INDEX FROM employees;
-- 删除索引
DROP INDEX idx_email ON employees;
查询优化技巧
-- 使用EXPLAIN分析查询
EXPLAIN SELECT * FROM employees WHERE department = '技术部';
-- 避免SELECT *
SELECT id, name, department FROM employees;
-- 合理使用LIMIT
SELECT * FROM large_table LIMIT 100;
-- 避免在WHERE子句中使用函数
-- 不推荐
SELECT * FROM employees WHERE YEAR(hire_date) = 2023;
-- 推荐
SELECT * FROM employees
WHERE hire_date BETWEEN '2023-01-01' AND '2023-12-31';
👥 六、用户与权限管理
用户管理
-- 创建用户
CREATE USER 'dev_user'@'localhost' IDENTIFIED BY 'secure_password';
-- 修改密码
ALTER USER 'dev_user'@'localhost' IDENTIFIED BY 'new_password';
-- 删除用户
DROP USER 'old_user'@'%';
权限管理
-- 授予权限
GRANT SELECT, INSERT, UPDATE ON company_db.* TO 'dev_user'@'localhost';
-- 授予所有权限
GRANT ALL PRIVILEGES ON *.* TO 'admin'@'%' WITH GRANT OPTION;
-- 查看权限
SHOW GRANTS FOR 'dev_user'@'localhost';
-- 撤销权限
REVOKE DELETE ON company_db.* FROM 'dev_user'@'localhost';
-- 刷新权限
FLUSH PRIVILEGES;
-- 手动加锁
SELECT * FROM orders WHERE id = 100 FOR UPDATE;
-- 查看当前锁
SHOW OPEN TABLES WHERE In_use > 0;
🧩 九、存储过程与函数
创建存储过程
DELIMITER //
CREATE PROCEDURE IncreaseSalaries(IN dept_name VARCHAR(50), IN increase_percent FLOAT)
BEGIN
UPDATE employees
SET salary = salary * (1 + increase_percent/100)
WHERE department = dept_name;
END //
DELIMITER ;
-- 调用存储过程
CALL IncreaseSalaries('技术部', 10);
创建函数
DELIMITER //
CREATE FUNCTION GetEmployeeCount(dept_name VARCHAR(50))
RETURNS INT
DETERMINISTIC
BEGIN
DECLARE emp_count INT;
SELECT COUNT(*) INTO emp_count
FROM employees
WHERE department = dept_name;
RETURN emp_count;
END //
DELIMITER ;
-- 使用函数
SELECT GetEmployeeCount('市场部');
⏰ 十、触发器与事件调度
创建触发器
-- 审计日志表
CREATE TABLE audit_log (
id INT AUTO_INCREMENT PRIMARY KEY,
action VARCHAR(20),
table_name VARCHAR(50),
record_id INT,
change_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建触发器
DELIMITER //
CREATE TRIGGER after_employee_update
AFTER UPDATE ON employees
FOR EACH ROW
BEGIN
INSERT INTO audit_log (action, table_name, record_id)
VALUES ('UPDATE', 'employees', NEW.id);
END //
DELIMITER ;
事件调度
-- 启用事件调度器
SET GLOBAL event_scheduler = ON;
-- 创建定期清理事件
CREATE EVENT daily_audit_cleanup
ON SCHEDULE EVERY 1 DAY
STARTS CURRENT_TIMESTAMP
DO
DELETE FROM audit_log WHERE change_time < NOW() - INTERVAL 30 DAY;
🐍 十一、Python 中使用 MySQL
import mysql.connector
from mysql.connector import Error
try:
# 创建连接
connection = mysql.connector.connect(
host='localhost',
user='python_user',
password='secure_pass',
database='company_db'
)
if connection.is_connected():
cursor = connection.cursor()
# 执行查询
cursor.execute("SELECT * FROM employees")
employees = cursor.fetchall()
# 插入数据
insert_query = """
INSERT INTO employees (name, email, department, salary)
VALUES (%s, %s, %s, %s)
"""
employee_data = ('钱七', 'qian@company.com', '人事部', 11000)
cursor.execute(insert_query, employee_data)
connection.commit()
# 更新数据
update_query = "UPDATE employees SET salary = salary * 1.05 WHERE department = %s"
cursor.execute(update_query, ('技术部',))
connection.commit()
except Error as e:
print("数据库错误:", e)
finally:
if connection.is_connected():
cursor.close()
connection.close()
🚨 十二、常见问题解决
忘记 root 密码
# 停止MySQL服务
sudo systemctl stop mysql
# 启动安全模式
sudo mysqld_safe --skip-grant-tables &
# 登录并修改密码
mysql -u root
FLUSH PRIVILEGES;
ALTER USER 'root'@'localhost' IDENTIFIED BY 'new_password';
FLUSH PRIVILEGES;
exit;
# 重启MySQL
sudo systemctl restart mysql
性能问题诊断
-- 查看慢查询
SHOW VARIABLES LIKE 'slow_query_log';
SHOW VARIABLES LIKE 'long_query_time';
-- 查看进程列表
SHOW PROCESSLIST;
-- 优化表
OPTIMIZE TABLE large_table;
-- 分析表
ANALYZE TABLE employees;
import sqlite3
from datetime import datetime
# 连接数据库(不存在则创建)
conn = sqlite3.connect('mydatabase.db')
cursor = conn.cursor()
# 创建表
cursor.execute('''CREATE TABLE IF NOT EXISTS orders (
id INTEGER PRIMARY KEY,
user_id INTEGER,
product TEXT,
amount REAL,
order_date TIMESTAMP,
FOREIGN KEY(user_id) REFERENCES users(id))''')
# 插入订单数据
user_id = 1
orders = [
(user_id, 'Laptop', 1200.50, datetime.now()),
(user_id, 'Mouse', 25.99, datetime.now())
]
cursor.executemany("INSERT INTO orders (user_id, product, amount, order_date) VALUES (?, ?, ?, ?)", orders)
# 复杂查询:用户及其订单
cursor.execute('''SELECT users.name, orders.product, orders.amount
FROM users
JOIN orders ON users.id = orders.user_id''')
for row in cursor.fetchall():
print(f"{row} purchased {row} for ${row:.2f}")
# 提交并关闭连接
conn.commit()
conn.close()
五、高级特性与优化
事务处理
BEGIN TRANSACTION;
-- 转账操作
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
-- 提交事务
COMMIT;
-- 出错时回滚
-- ROLLBACK;
性能优化技巧
索引优化:
CREATE INDEX idx_users_email ON users(email);
CREATE INDEX idx_orders_date ON orders(order_date);
WAL模式:
PRAGMA journal_mode=WAL;-- 启用写前日志
缓存调整:
PRAGMA cache_size = -2000;-- 设置2000页缓存(约3.2MB)
查询优化:
EXPLAIN QUERY PLAN SELECT * FROM users WHERE email = 'test@example.com';
全文搜索
-- 创建虚拟表
CREATE VIRTUAL TABLE docs USING fts5(title, content);
-- 插入数据
INSERT INTO docs VALUES
('SQLite Guide', 'Comprehensive guide to SQLite database'),
('Python Tutorial', 'Learn Python programming language');
-- 全文搜索
SELECT * FROM docs WHERE docs MATCH 'guide database';
-- 附加另一个数据库
ATTACH DATABASE 'another.db' AS other;
-- 跨数据库查询
SELECT * FROM main.users
UNION ALL
SELECT * FROM other.users;
-- 分离数据库
DETACH DATABASE other;
八、实际应用场景
移动应用数据存储
// Android示例
SQLiteDatabase db = openOrCreateDatabase("app_data.db", MODE_PRIVATE, null);
db.execSQL("CREATE TABLE IF NOT EXISTS settings (key TEXT PRIMARY KEY, value TEXT)");
ContentValues values = new ContentValues();
values.put("key", "theme");
values.put("value", "dark");
db.insert("settings", null, values);
网站数据分析
# 日志分析示例
import sqlite3
conn = sqlite3.connect('weblog.db')
conn.execute('''CREATE TABLE IF NOT EXISTS visits
(id INTEGER PRIMARY KEY,
ip TEXT,
url TEXT,
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP)''')
# 模拟插入访问记录
conn.execute("INSERT INTO visits (ip, url) VALUES (?, ?)",
('192.168.1.1', '/homepage'))
conn.commit()
# 连接到本地MySQL服务器
mysql -u root -p
# 指定主机和端口
mysql -h 127.0.0.1 -P 3306 -u username -p
# 连接后直接选择数据库
mysql -u root -p database_name
连接参数说明
参数
说明
示例
-u
用户名
-u admin
-p
密码提示
(回车后输入密码)
-h
主机地址
-h db.example.com
-P
端口号
-P 3307
-D
指定数据库
-D mydb
🔍 数据库与表操作
数据库管理
-- 显示所有数据库
SHOW DATABASES;
-- 创建新数据库
CREATE DATABASE school_db;
-- 选择数据库
USE school_db;
-- 删除数据库
DROP DATABASE old_db;
表操作
-- 创建学生表
CREATE TABLE students (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age INT CHECK (age >= 15),
email VARCHAR(100) UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 显示所有表
SHOW TABLES;
-- 查看表结构
DESCRIBE students;
-- 修改表结构
ALTER TABLE students ADD COLUMN major VARCHAR(50);
ALTER TABLE students MODIFY COLUMN age TINYINT;
ALTER TABLE students DROP COLUMN email;
📊 数据操作(CRUD)
插入数据
INSERT INTO students (name, age)
VALUES
('张三', 18),
('李四', 19),
('王五', 17);
查询数据
-- 查询所有数据
SELECT * FROM students;
-- 条件查询
SELECT name, age FROM students WHERE age > 18;
-- 排序和限制
SELECT * FROM students ORDER BY created_at DESC LIMIT 5;
-- 模糊查询
SELECT * FROM students WHERE name LIKE '张%';
更新数据
UPDATE students
SET age = 20
WHERE name = '张三';
删除数据
DELETE FROM students
WHERE name = '王五';
🔧 高级查询技巧
聚合函数
SELECT
COUNT(*) AS total,
AVG(age) AS avg_age,
MIN(created_at) AS oldest,
MAX(age) AS max_age
FROM students;
分组统计
SELECT
major,
COUNT(*) AS student_count,
AVG(age) AS avg_age
FROM students
GROUP BY major
HAVING COUNT(*) > 5;
表连接
-- 创建课程表
CREATE TABLE courses (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
instructor VARCHAR(50)
);
-- 内连接查询
SELECT s.name, c.name AS course
FROM students s
JOIN courses c ON s.id = c.student_id;
👥 用户与权限管理
用户管理
-- 创建新用户
CREATE USER 'dev'@'localhost' IDENTIFIED BY 'password123';
-- 修改密码
ALTER USER 'dev'@'localhost' IDENTIFIED BY 'newpassword456';
-- 删除用户
DROP USER 'dev'@'localhost';
权限管理
-- 授予权限
GRANT SELECT, INSERT, UPDATE ON school_db.* TO 'dev'@'localhost';
-- 查看权限
SHOW GRANTS FOR 'dev'@'localhost';
-- 撤销权限
REVOKE UPDATE ON school_db.* FROM 'dev'@'localhost';
-- 列出所有用户
\du
-- 创建新用户
CREATE USER dev WITH PASSWORD 'secret123';
-- 修改密码
ALTER USER dev WITH PASSWORD 'newsecret456';
-- 授予权限
GRANT SELECT, INSERT ON customers TO dev;
-- 简单查询
SELECT * FROM employees;
-- 条件查询
SELECT name, salary FROM employees WHERE salary > 50000;
-- 排序
SELECT * FROM orders ORDER BY order_date DESC;
-- 限制结果
SELECT * FROM products LIMIT 10;
多行编辑
-- 开启多行模式
\set PROMPT1 '%/%R%# '
-- 输入多行SQL语句
SELECT
first_name,
last_name,
department
FROM employees
WHERE hire_date > '2020-01-01';
-- 结束多行输入(分号后回车)
;
# 认证失败
psql: FATAL: password authentication failed for user "user"
# 解决方案:
# 1. 检查pg_hba.conf配置
# 2. 重置密码:ALTER USER user WITH PASSWORD 'newpassword';
权限问题
-- 权限拒绝
ERROR: permission denied for table tablename
# 解决方案:
GRANT SELECT, INSERT ON tablename TO username;
特殊字符处理
-- 包含引号的字符串
SELECT * FROM comments WHERE text E'contains \'quote\'';
-- 使用$tag$语法
DO $$
BEGIN
INSERT INTO logs (message) VALUES ('This contains ''quotes''');
END $$;
CREATE TABLE students (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age INT CHECK (age >= 15),
email VARCHAR(100) UNIQUE,
enrollment_date DATE DEFAULT CURRENT_DATE
);
查看表结构
DESCRIBE students;
修改表结构
-- 添加新列
ALTER TABLE students ADD COLUMN major VARCHAR(50);
-- 修改列类型
ALTER TABLE students MODIFY COLUMN age SMALLINT;
-- 删除列
ALTER TABLE students DROP COLUMN email;
删除表
DROP TABLE students;
三、数据操作(CRUD)
插入数据
INSERT INTO students (name, age, enrollment_date)
VALUES
('张三', 18, '2023-09-01'),
('李四', 19, '2023-08-25'),
('王五', 17, '2023-09-05');
查询数据
-- 查询所有列
SELECT * FROM students;
-- 查询特定列
SELECT name, age FROM students;
-- 带条件查询
SELECT * FROM students WHERE age > 18;
更新数据
UPDATE students
SET age = 20
WHERE name = '张三';
删除数据
DELETE FROM students
WHERE name = '王五';
四、高级查询技巧
排序结果
SELECT * FROM students
ORDER BY age DESC, name ASC;
限制结果数量
SELECT * FROM students
ORDER BY enrollment_date DESC
LIMIT 5;
模糊查询
SELECT * FROM students
WHERE name LIKE '张%';
聚合函数
SELECT
COUNT(*) AS total_students,
AVG(age) AS average_age,
MIN(enrollment_date) AS earliest_enrollment,
MAX(age) AS max_age
FROM students;
分组统计
SELECT
major,
COUNT(*) AS student_count,
AVG(age) AS avg_age
FROM students
GROUP BY major
HAVING COUNT(*) > 5;
SELECT s.name, c.course_name
FROM students s
INNER JOIN enrollments e ON s.id = e.student_id
INNER JOIN courses c ON e.course_id = c.course_id;
左连接
SELECT s.name, c.course_name
FROM students s
LEFT JOIN enrollments e ON s.id = e.student_id
LEFT JOIN courses c ON e.course_id = c.course_id;
六、子查询
单行子查询
SELECT * FROM students
WHERE age > (SELECT AVG(age) FROM students);
多行子查询
SELECT * FROM courses
WHERE course_id IN (
SELECT course_id FROM enrollments
GROUP BY course_id
HAVING COUNT(*) > 30
);
七、索引优化
创建索引
-- 单列索引
CREATE INDEX idx_student_name ON students(name);
-- 复合索引
CREATE INDEX idx_student_age_name ON students(age, name);
-- 唯一索引
CREATE UNIQUE INDEX idx_unique_email ON students(email);
查看索引
SHOW INDEX FROM students;
删除索引
DROP INDEX idx_student_name ON students;
八、视图
创建视图
CREATE VIEW student_summary AS
SELECT
s.id,
s.name,
COUNT(e.course_id) AS courses_enrolled
FROM students s
LEFT JOIN enrollments e ON s.id = e.student_id
GROUP BY s.id, s.name;
使用视图
SELECT * FROM student_summary
WHERE courses_enrolled > 3;
删除视图
DROP VIEW student_summary;
九、事务管理
START TRANSACTION;
-- 一系列操作
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
-- 提交事务
COMMIT;
-- 或回滚事务
-- ROLLBACK;
//*[((name()='h1' or name()='h2') and re:test(., '\s*((chapter|book|section|part)\s+)|((prolog|prologue|epilogue)(\s+|$))', 'i')) or @class = 'chapter']
//*[name()='h1' or name()='h2']
Hello, xxx!
Welcome to your personal Z-Library telegram bot 📚Z-Library is the world's largest e-book library with over 10 million books and 80 million articles. We aim to make knowledge accessible to everyone.
🔹How do I download books via the bot?
To find and download a book, just send the title of the book, author’s name, publisher or ISBN/ASIN number to the bot and click on the appeared link.
You can also specify language and preferred file format. For example, “war and peace pdf” or “oscar wilde chinese epub”.
🔹How many books can I download?
Using the bot, you can download more books in addition to your daily download limit on Z-Library website. For example, if your daily limit is 10 downloads, you have 10 extra downloads available in the bot (20 downloads in total). Or you can only use the bot and download 20 books from here. *Keep in mind that by downloading a book from the bot first, you are spending your daily website limit.
🔹How do I save files from Telegram?
On Desktop: right click on the file > choose “Save as” option.
On iOS: first open the file > use the Share button (upper right corner) > save it wherever you want (Files, iBooks, etc.).
On Android: open the file > press the three dots button > choose “Save to Gallery or Downloads”.
🔹Can I share the bot with others?
Only you, the bot creator, can use it to search and download books. You can share a link to your bot, in this case bot will prompt any other user to register a personal bot on the Z-Library website.
🔹How can I unlink my Telegram account?
You can do this in your library profile on the website. *Be aware that the bot will not work without binding to Z-Library account.
——————-
📧 If you have any issues feel free to contact us via support@z-lib.fm